This article is reproduced, and the original source is as follows:
What you need to know about character encoding
Character encoding is a problem that every programmer faces, especially when thinking deeply about the details of programming. This blog post is the most systematic and comprehensive coverage of the content I have seen so far. Among them, the basic principles of character encoding and the main points of various main encoding types are explained very incisively and are worth reading.
What you need to know about character encoding (ASCII, Unicode, Utf-8, GB2312...)
The problem of character encoding seems to be small and is often ignored by technical personnel, but it can easily lead to some inexplicable problems. Here is a summary of some popular knowledge of character encoding, hoping to help everyone.
Still have to start with ASCII code
When it comes to character encoding, I have to say a brief history of ASCII code. Computers were first invented to solve numerical computing problems, and later it was discovered that computers could do much more, such as text processing. But since computers only know "numbers", people have to tell the computer which number represents which particular character, e.g. 65 for the letter 'A', 66 for the letter 'B', and so on. However, the correspondence between characters and numbers between computers must be consistent, otherwise, the characters displayed in the same segment of numbers on different computers will be different. Therefore, the American National Standards Institute (ANSI) has developed a standard that specifies the set of commonly used characters and the corresponding number of each character. This is the ASCII character set (Character Set), also known as ASCII code.
Computers at that time generally used 8-bit bytes as the smallest storage and processing unit. In addition, there were very few characters used at that time. There were less than 100 26 uppercase and lowercase English letters and numbers plus other commonly used symbols. Therefore, ASCII code can be efficiently stored and processed using 7 bits, and the remaining most significant 1 bit is used for parity in some communication systems.
Note that a byte represents the smallest unit the system can handle, not necessarily 8 bits. It's just that the de facto standard for modern computers is to use 8 bits to represent a byte. In many specification documents, to avoid ambiguity, the term Octet is preferred rather than Byte to emphasize 8-bit binary streams. In the following, for ease of understanding, I will continue to use the familiar concept of "byte".
ASCII table 
The ASCII character set consists of 95 printable characters (0x20-0x7E) and 33 control characters (0x00-0x19, 0x7F). Printable characters are used to display on an output device, such as a screen or printer paper, control characters are used to send some special instructions to the computer, such as 0x07 to make the computer beep, 0x00 is usually used to indicate the end of a string, 0x0D and 0x0A are used to instruct the printer's print head to go back to the beginning of the line (carriage return) and move to the next line (line feed).
At that time, the character encoding and decoding system was very simple, which was a simple table lookup process. For example, to encode a character sequence into a binary stream and write it to a storage device, it is only necessary to find the bytes corresponding to the characters in the ASCII character set in turn, and then directly write the bytes to the storage device. The process of decoding a binary stream is similar.
Derivation of OEM character set
When computers began to develop, people gradually found that the poor 128 characters in the ASCII character set could no longer meet their needs. People are thinking that there are 256 numbers (numbers) that can be represented by a byte, and ASCII characters only use 0x00~0x7F, that is, the first 128 numbers are occupied, and the last 128 numbers are not used in vain, so many people fight The idea behind the 128 numbers. But the problem is that many people have this idea at the same time, but everyone has their own ideas about what kind of characters the 128 numbers after 0x80-0xFF correspond to. This resulted in a wide variety of OEM character sets on machines sold all over the world at the time.
The following table is one of the OEM character sets introduced by IBM-PC. The first 128 characters of the character set are basically the same as the ASCII character set (why it is basically the same, because the first 32 control characters are in some cases will be interpreted as printable characters by the IBM-PC), the latter 128 character spaces are added with accented characters used in some European countries, and some characters used for line drawing.

IBM-PC OEM character set
In fact, most OEM character sets are compatible with ASCII character sets, that is to say, everyone's interpretation of the range of 0x00~0x7F is basically the same, but the interpretation of the second half of 0x80~0xFF is not necessarily the same. Even sometimes the same character corresponds to different bytes in different OEM character sets.
Different OEM character sets make it impossible for people to communicate various documents across machines. For example, employee A sends a resume résumés to employee B, but what employee B sees is r?sum?s, because the é character corresponds to 0x82 in the OEM character set on employee A's machine, while the byte in employee B's OEM character set is 0x82. On the machine of , due to the different OEM character sets used, the character obtained after decoding the 0x82 byte is ?.
Multibyte Character Set (MBCS) and Chinese Character Set
The character sets we mentioned above are all based on single-byte encoding, that is, a byte is translated into a character. This may not be a problem for Latin-speaking countries, because they can get 256 characters by extending the 8th bit, which is enough. But for Asian countries, 256 characters is far from enough. Therefore, in order to use computers and maintain compatibility with the ASCII character set, people in these countries invented a multi-byte encoding method, and the corresponding character set is called a multi-byte character set. For example, China uses Double Byte Character Set (DBCS, Double Byte Character Set).
For a single-byte character set, there is only one code table in the code page, which records the characters represented by 256 numbers. The program only needs to do a simple look-up table operation to complete the encoding and decoding process.
The code page is the specific implementation of character set encoding. You can understand it as a "character-byte" mapping table, and the translation of "character-byte" can be realized by looking up the table. There will be a more detailed description below.
For multibyte character sets, there are usually many code tables in the code page. So how does the program know which code table to use to decode the binary stream? The answer is to choose a different code table for parsing based on the first byte.
For example, GB2312, the most commonly used Chinese character set at present, covers all simplified characters and some other characters; GBK (K stands for extension) adds other non-simplified characters such as traditional characters to GB2312 (GB18030 character set is not a double character set). Byte character set, which we will mention when we talk about Unicode). The characters of these two character sets are represented by 1-2 bytes. The Windows system uses the 936 code page to encode and decode the GBK character set. When parsing the byte stream, if the highest bit of the byte is 0, then the first code table in the 936 code page is used for decoding, which is consistent with the encoding and decoding method of the single-byte character set .
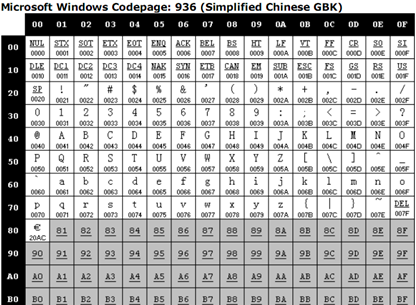
When the high bit of the byte is 1, to be exact, when the first byte is between 0x81–0xFE, find the corresponding code table in the code page according to the first byte, for example, when the first byte The byte is 0x81, which corresponds to the following code table in 936:

(For complete code table information in the 936 code page, see MSDN: http://msdn.microsoft.com/en-us/library/cc194913%28v=MSDN.10%29.aspx .)
According to the code table of the 936 code page, when the program encounters the continuous byte stream 0x81 0x40, it will be decoded as the "丂" character.
ANSI standard, national standard, ISO standard
The emergence of different ASCII-derived character sets has made document exchange very difficult, so various organizations have successively carried out standardization processes. For example, the ANSI organization in the United States has formulated the ANSI standard character encoding (note that we usually talk about ANSI encoding now, which usually refers to the default encoding of the platform, such as ISO-8859-1 in the English operating system and GBK in the Chinese system), and the ISO organization Various ISO standard character encodings have been developed, and some countries will also develop some national standard character sets, such as China's GBK, GB2312 and GB18030.
When the operating system is released, these standard character sets and platform-specific character sets are usually pre-installed in the machine, so that as long as your documents are written in standard character sets, the versatility is relatively high. For example, a document written in GB2312 character set can be displayed correctly on any machine in mainland China. At the same time, we can also read documents in multiple countries and languages on one machine, provided that the character set used by the document must be installed on this machine.
Emergence of Unicode
Although by using different character sets, we can view documents in different languages on one machine, but we still cannot solve one problem: display all characters in one document. To solve this problem, we need a huge character set that all human beings can agree on, which is the Unicode character set.
An overview of the Unicode character set
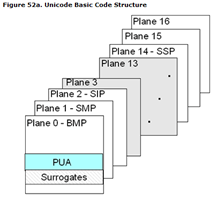
The Unicode character set covers all the characters currently used by humans, and assigns a unique character code (Code Point) to each character by uniform numbering. The Unicode character set divides all characters into 17 levels (Plane) according to the frequency of use, and each level has 216=65536 character code spaces.
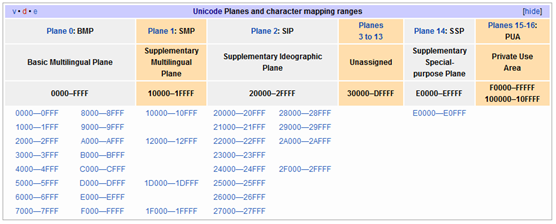
The 0th level BMP basically covers all the characters used in the world today. The other layers are either used to represent some ancient text or are reserved for expansion. The Unicode characters we usually use are generally located at the BMP level. There is still a large amount of unused character space in the Unicode character set.
Changes in the coding system
Before the advent of Unicode, all character sets were bound to specific encoding schemes, which directly bound the characters to the final byte stream. For example, the ASCII encoding system stipulated that 7 bits were used to encode the ASCII character set; GB2312 and GBK character sets limit the use of up to 2 bytes to encode all characters, and specify the endianness. Such an encoding system usually uses a simple look-up table, that is, through the code page, the characters can be directly mapped to the byte stream on the storage device. For example the following example:
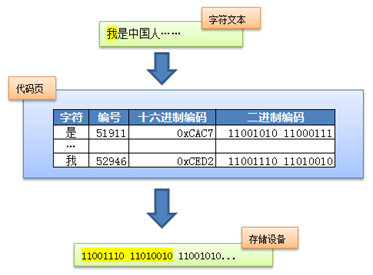
The disadvantage of this approach is that the coupling between the character and byte streams is too tight, which limits the scalability of the character set. Assuming that Martians settle on Earth in the future, it will become difficult or even impossible to add Martian characters to the existing character set, and it is easy to break the existing encoding rules.
So Unicode was designed with this in mind, separating the character set from the character encoding scheme.
character encoding system
That is to say, although each character can find a unique number (character code, also known as Unicode code) in the Unicode character set, it is the specific character encoding that determines the final byte stream. For example, the Unicode character "A" is also encoded, the byte stream obtained by UTF-8 character encoding is 0x41, and the UTF-16 (big endian mode) is 0x00 0x41.
Common Unicode encodings
UCS-2/UTF-16
If we were to implement the encoding scheme for BMP characters in the Unicode character set, how would we implement it? Since there are 216=65536 character codes at the BMP level, we only need two bytes to fully represent all these characters.
For example, the Unicode character code for "medium" is 0x4E2D (01001110 00101101), then we can encode it as 01001110 00101101 (big endian) or 00101101 01001110 (little endian).
Both UCS-2 and UTF-16 use 2 bytes to represent BMP-level characters, and the encoding results are exactly the same. The difference is that UCS-2 only considered BMP characters when it was originally designed, so it uses a fixed 2-byte length, that is, it cannot represent characters at other levels of Unicode, and UTF-16 In order to remove this limitation, It supports the encoding and decoding of the full Unicode character set. It adopts variable-length encoding and uses at least 2 bytes. If you want to encode characters other than BMP, you need 4-byte pairing. It will not be discussed here. If you are interested, you can refer to the wiki Encyclopedia: UTF-16/UCS-2.
Windows has used UTF-16 encoding since the NT era, and many popular programming platforms, such as .Net, Java, Qt, and Cocoa under Mac, use UTF-16 as the basic character encoding. For example, the string in the code, the corresponding byte stream in the memory is encoded with UTF-16.
UTF-8
UTF-8 should be the most widely used Unicode encoding scheme at present. Since UCS-2/UTF-16 uses two bytes to encode ASCII characters, the storage and processing efficiency is relatively low, and because of the two bytes obtained after UTF-16 encoding of ASCII characters, the high byte is always 0x00, Many C-language functions treat this byte as the end of the string and cannot parse the text correctly. Therefore, when it was first launched, it was opposed by many Western countries, which greatly affected the implementation of Unicode. Later, smart people invented UTF-8 encoding to solve this problem.
The UTF-8 encoding scheme uses 1-4 bytes to encode characters, and the method is actually very simple.
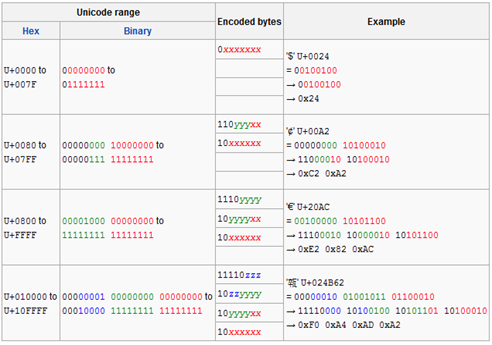
(x in the above figure represents the lower 8 bits of the Unicode code, and y represents the upper 8 bits)
对于ASCII字符的编码使用单字节,和ASCII编码一摸一样,这样所有原先使用ASCII编解码的文档就可以直接转到UTF-8编码了。对于其他字符,则使用2-4个字节来表示,其中,首字节前置1的数目代表正确解析所需要的字节数,剩余字节的高2位始终是10。例如首字节是1110yyyy,前置有3个1,说明正确解析总共需要3个字节,需要和后面2个以10开头的字节结合才能正确解析得到字符。
关于UTF-8的更多信息,参考维基百科:UTF-8。
GB18030
任何能够将Unicode字符映射为字节流的编码都属于Unicode编码。中国的GB18030编码,覆盖了Unicode所有的字符,因此也算是一种Unicode编码。只不过他的编码方式并不像UTF-8或者UTF-16一样,将Unicode字符的编号通过一定的规则进行转换,而只能通过查表的手段进行编码。
关于GB18030的更多信息,参考:GB18030。
Unicode相关的常见问题
Unicode是两个字节吗?
Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储为什么样的字节流,取决于字符编码方案。推荐的Unicode编码是UTF-16和UTF-8。
带签名的UTF-8指的是什么意思?
带签名指的是字节流以BOM标记开始。很多软件会“智能”的探测当前字节流使用的字符编码,这种探测过程出于效率考虑,通常会提取字节流前面若干个字节,看看是否符合某些常见字符编码的编码规则。由于UTF-8和ASCII编码对于纯英文的编码是一样的,无法区分开来,因此通过在字节流最前面添加BOM标记可以告诉软件,当前使用的是Unicode编码,判别成功率就十分准确了。但是需要注意,不是所有软件或者程序都能正确处理BOM标记,例如PHP就不会检测BOM标记,直接把它当普通字节流解析了。因此如果你的PHP文件是采用带BOM标记的UTF-8进行编码的,那么有可能会出现问题。
Unicode编码和以前的字符集编码有什么区别?
早期字符编码、字符集和代码页等概念都是表达同一个意思。例如GB2312字符集、GB2312编码,936代码页,实际上说的是同个东西。但是对于Unicode则不同,Unicode字符集只是定义了字符的集合和唯一编号,Unicode编码,则是对UTF-8、UCS-2/UTF-16等具体编码方案的统称而已,并不是具体的编码方案。所以当需要用到字符编码的时候,你可以写gb2312,codepage936,utf-8,utf-16,但请不要写unicode(看过别人在网页的meta标签里头写charset=unicode,有感而发)。
乱码问题
乱码指的是程序显示出来的字符文本无法用任何语言去解读。一般情况下会包含大量解码失败替换字符或者?。乱码问题是所有计算机用户或多或少会遇到的问题。造成乱码的原因就是因为使用了错误的字符编码去解码字节流,因此当我们在思考任何跟文本显示有关的问题时,请时刻保持清醒:当前使用的字符编码是什么。只有这样,我们才能正确分析和处理乱码问题。
例如最常见的网页乱码问题。如果你是网站技术人员,遇到这样的问题,需要检查以下原因:
- 服务器返回的响应头Content-Type没有指明字符编码
- 网页内是否使用META HTTP-EQUIV标签指定了字符编码
- 网页文件本身存储时使用的字符编码和网页声明的字符编码是否一致
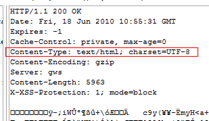

注意,网页解析的过程如果使用的字符编码不正确,还可能会导致脚本或者样式表出错。具体细节可以参考我以前写过的文章:文档字符集导致的脚本错误和Asp.Net页面的编码问题。
不久前看到某技术论坛有人反馈,WinForm程序使用Clipboard类的GetData方法去访问剪切板中的HTML内容时会出现乱码的问题,我估计也是由于WinForm在获取HTML文本的时候没有用对正确的字符编码导致的。Windows剪贴板只支持UTF-8编码,也就是说你传入的文本都会被UTF-8编解码。这样一来,只要两个程序都是调用Windows剪切板API编程的话,那么复制粘贴的过程中不会出现乱码。除非一方在获取到剪贴板数据之后使用了错误的字符编码进行解码,才会得到乱码(我做了简单的WinForm剪切板编程实验,发现GetData使用的是系统默认编码,而不是UTF-8编码)。
关于乱码中出现?或者?,这里需要额外提一下,当程序使用特定字符编码解析字节流的时候,一旦遇到无法解析的字节流时,就会用解码失败替换字符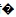 或者?来替代。因此,一旦你最终解析得到的文本包含这样的字符,而你又无法得到原始字节流的时候,说明正确的信息已经彻底丢失了,尝试任何字符编码都无法从这样的字符文本中还原出正确的信息来。
或者?来替代。因此,一旦你最终解析得到的文本包含这样的字符,而你又无法得到原始字节流的时候,说明正确的信息已经彻底丢失了,尝试任何字符编码都无法从这样的字符文本中还原出正确的信息来。
必要的术语解释
字符集(Character Set)
字面上的理解就是字符的集合,例如ASCII字符集,定义了128个字符;GB2312定义了7445个字符。而计算机系统中提到的字符集准确来说,指的是已编号的字符的有序集合(不一定是连续)。
字符码(Code Point)
指的就是字符集中每个字符的数字编号。例如ASCII字符集用0-127这连续的128个数字分别表示128个字符;GBK字符集使用区位码的方式为每个字符编号,首先定义一个94X94的矩阵,行称为“区”,列称为“位”,然后将所有国标汉字放入矩阵当中,这样每个汉字就可以用唯一的“区位”码来标识了。例如“中”字被放到54区第48位,因此字符码就是5448。而Unicode中将字符集按照一定的类别划分到0~16这17个层面(Planes)中,每个层面中拥有216=65536个字符码,因此Unicode总共拥有的字符码,也即是Unicode的字符空间总共有17*65536=1114112。
编码
将字符转换成字节流的过程。
解码
是将字节流解析为字符的过程。
字符编码(Character Encoding)
是将字符集中的字符码映射为字节流的一种具体实现方案。例如ASCII字符编码规定使用单字节中低位的7个比特去编码所有的字符。例如‘A’的编号是65,用单字节表示就是0x41,因此写入存储设备的时候就是b’01000001’。GBK编码则是将区位码(GBK的字符码)中的区码和位码的分别加上0xA0(160)的偏移(之所以要加上这样的偏移,主要是为了和ASCII码兼容),例如刚刚提到的“中”字,区位码是5448,十六进制是0x3630,区码和位码分别加上0xA0的偏移之后就得到0xD6D0,这就是“中”字的GBK编码结果。
代码页(Code Page)
一种字符编码具体形式。早期字符相对少,因此通常会使用类似表格的形式将字符直接映射为字节流,然后通过查表的方式来实现字符的编解码。现代操作系统沿用了这种方式。例如Windows使用936代码页、Mac系统使用EUC-CN代码页实现GBK字符集的编码,名字虽然不一样,但对于同一汉字的编码肯定是一样的。
大小端
说法源自《格列佛游记》。我们知道,鸡蛋通常一端大一端小,小人国的人们对于剥蛋壳时应从哪一端开始剥起有着不一样的看法。同样,计算机界对于传输多字节字(由多个字节来共同表示一个数据类型)时,是先传高位字节(大端)还是先传低位字节(小端)也有着不一样的看法,这就是计算机里头大小端模式的由来了。无论是写文件还是网络传输,实际上都是往流设备进行写操作的过程,而且这个写操作是从流的低地址向高地址开始写(这很符合人的习惯),对于多字节字来说,如果先写入高位字节,则称作大端模式。反之则称作小端模式。也就是说,大端模式下,字节序和流设备的地址顺序是相反的,而小端模式则是相同的。一般网络协议都采用大端模式进行传输,windows操作系统采用Utf-16小端模式。
——Kevin Yang
参考链接:
http://developers.sun.com/dev/gadc/technicalpublications/articles/gb18030.html
http://en.wikipedia.org/wiki/Universal_Character_Set
http://en.wikipedia.org/wiki/Code_page