Link: https://zhuanlan.zhihu.com/p/24379501
Source: Zhihu The
copyright belongs to the author. For commercial reprints, please contact the author for authorization, and for non-commercial reprints, please indicate the source.
foreword
In game development, the necessary information is often initialized when the player enters the game. Often, the initialization information packet is relatively large, generally around 30-40kb, and it is still necessary to compress it before sending the message, just right I read it some time ago, which lists some commonly used compression algorithms, as shown in the following figure:
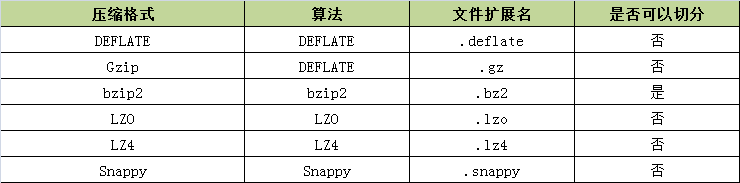
Whether or not it can be sliced indicates whether it is possible to search any position of the data stream and read the data further down. This function is especially suitable for Hadoop's MapReduce.
The following is a brief introduction to these compression formats, and a stress test is performed to compare the performance.
DEFLATE
DEFLATE is a lossless data compression algorithm that uses both the LZ77 algorithm and Huffman Coding. The source code of DEFLATE compression and decompression can be found on the free and general compression library zlib, zlib official website: http://www .zlib.net/
JDK provides support for zlib compression library, compression class Deflater and decompression class Inflater, both Deflater and Inflater provide native methods
private native int deflateBytes(long addr, byte[] b, int off, int len,
int flush);
private native int inflateBytes(long addr, byte[] b, int off, int len)
throws DataFormatException;
All can directly use the compression class Deflater and decompression class Inflater provided by jdk, the code is as follows:
public static byte[] compress(byte input[]) {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Deflater compressor = new Deflater(1);
try {
compressor.setInput(input);
compressor.finish();
final byte[] buf = new byte[2048];
while (!compressor.finished()) {
int count = compressor.deflate(buf);
bos.write(buf, 0, count);
}
} finally {
compressor.end();
}
return bos.toByteArray();
}
public static byte[] uncompress(byte[] input) throws DataFormatException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Inflater decompressor = new Inflater();
try {
decompressor.setInput(input);
final byte[] buf = new byte[2048];
while (!decompressor.finished()) {
int count = decompressor.inflate(buf);
bos.write(buf, 0, count);
}
} finally {
decompressor.end();
}
return bos.toByteArray();
}
The compression level of the algorithm can be specified so that you can balance compression time and output file size. The optional levels are 0 (no compression), and 1 (fast compression) to 9 (slow compression), where speed is the priority.
gzip
The implementation algorithm of gzip is still deflate, but the file header and file tail are added to the deflate format. Similarly, jdk also provides support for gzip, which are GZIPOutputStream and GZIPInputStream classes. It can also be found that GZIPOutputStream inherits from DeflaterOutputStream, and GZIPInputStream inherits from InflaterInputStream. , and the writeHeader and writeTrailer methods can be found in the source code:
private void writeHeader() throws IOException {
......
}
private void writeTrailer(byte[] buf, int offset) throws IOException {
......
}
The specific code implementation is as follows:
public static byte[] compress(byte srcBytes[]) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPOutputStream gzip;
try {
gzip = new GZIPOutputStream(out);
gzip.write(srcBytes);
gzip.close();
} catch (IOException e) {
e.printStackTrace();
}
return out.toByteArray();
}
public static byte[] uncompress(byte[] bytes) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
try {
GZIPInputStream ungzip = new GZIPInputStream(in);
byte[] buffer = new byte[2048];
int n;
while ((n = ungzip.read(buffer)) >= 0) {
out.write(buffer, 0, n);
}
} catch (IOException e) {
e.printStackTrace();
}
return out.toByteArray();
}
bzip2
bzip2 is a data compression algorithm and program developed by Julian Seward and released under a free software/open source software license. Seward first publicly released version 0.15 of bzip2 in July 1996. Over the next few years, the compression tool improved in stability and became more popular, with Seward releasing version 1.0 in late 2000. more wiki bzip2
bzip2 compresses more efficiently than traditional gzip, but it compresses slower.
There is no implementation of bzip2 in jdk, but it is implemented in commons-compress, introduced by maven:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.12</version>
</dependency>
The specific code implementation is as follows:
public static byte[] compress(byte srcBytes[]) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
BZip2CompressorOutputStream bcos = new BZip2CompressorOutputStream(out);
bcos.write(srcBytes);
bcos.close();
return out.toByteArray();
}
public static byte[] uncompress(byte[] bytes) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
try {
BZip2CompressorInputStream ungzip = new BZip2CompressorInputStream(
in);
byte[] buffer = new byte[2048];
int n;
while ((n = ungzip.read(buffer)) >= 0) {
out.write(buffer, 0, n);
}
} catch (IOException e) {
e.printStackTrace();
}
return out.toByteArray();
}
The following three compression algorithms, lzo, lz4 and snappy, all have compression speed as priority, but compression efficiency is slightly inferior
lzo
LZO is a data compression algorithm dedicated to decompression speed, LZO is the abbreviation of Lempel-Ziv-Oberhumer. This algorithm is a lossless algorithm, more wiki LZO
Need to introduce third-party libraries, maven introduces:
<dependency>
<groupId>org.anarres.lzo</groupId>
<artifactId>lzo-core</artifactId>
<version>1.0.5</version>
</dependency>
Specific implementation code:
public static byte[] compress(byte srcBytes[]) throws IOException {
LzoCompressor compressor = LzoLibrary.getInstance().newCompressor(
LzoAlgorithm.LZO1X, null);
ByteArrayOutputStream os = new ByteArrayOutputStream();
LzoOutputStream cs = new LzoOutputStream(os, compressor);
cs.write(srcBytes);
cs.close();
return os.toByteArray();
}
public static byte[] uncompress(byte[] bytes) throws IOException {
LzoDecompressor decompressor = LzoLibrary.getInstance()
.newDecompressor(LzoAlgorithm.LZO1X, null);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ByteArrayInputStream is = new ByteArrayInputStream(bytes);
LzoInputStream us = new LzoInputStream(is, decompressor);
int count;
byte[] buffer = new byte[2048];
while ((count = us.read(buffer)) != -1) {
baos.write(buffer, 0, count);
}
return baos.toByteArray();
}
lz4
LZ4 is a lossless data compression algorithm that focuses on compression and decompression speed more wiki lz4
Maven introduces third-party libraries:
<dependency>
<groupId>net.jpountz.lz4</groupId>
<artifactId>lz4</artifactId>
<version>1.2.0</version>
</dependency>
Specific code implementation:
public static byte[] compress(byte srcBytes[]) throws IOException {
LZ4Factory factory = LZ4Factory.fastestInstance();
ByteArrayOutputStream byteOutput = new ByteArrayOutputStream();
LZ4Compressor compressor = factory.fastCompressor();
LZ4BlockOutputStream compressedOutput = new LZ4BlockOutputStream(
byteOutput, 2048, compressor);
compressedOutput.write(srcBytes);
compressedOutput.close();
return byteOutput.toByteArray();
}
public static byte[] uncompress(byte[] bytes) throws IOException {
LZ4Factory factory = LZ4Factory.fastestInstance();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
LZ4FastDecompressor decompresser = factory.fastDecompressor();
LZ4BlockInputStream lzis = new LZ4BlockInputStream(
new ByteArrayInputStream(bytes), decompresser);
int count;
byte[] buffer = new byte[2048];
while ((count = lzis.read(buffer)) != -1) {
baos.write(buffer, 0, count);
}
lzis.close();
return baos.toByteArray();
}
snappy
Snappy (formerly Zippy) is a fast data compression and decompression library written in C++ language based on the idea of LZ77 by Google, and was open sourced in 2011. Its goal is not maximum compression ratio or compatibility with other compression libraries, but very high speed and reasonable compression ratio. more wiki snappyMaven introduces third-party libraries:
<dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
<version>1.1.2.6</version>
</dependency>
Specific code implementation:
public static byte[] compress(byte srcBytes[]) throws IOException {
return Snappy.compress(srcBytes);
}
public static byte[] uncompress(byte[] bytes) throws IOException {
return Snappy.uncompress(bytes);
}
pressure test
The following is a compression and decompression test for 35kb player data. Relatively speaking, 35kb data is still a very small amount of data. All the following test results are only the results of the test for the specified data volume range, and cannot explain which compression algorithm is good or bad. .
test environment:
- jdk:1.7.0_79
- CPU: [email protected] 4 cores
- memory:4G
Perform 2000 compression and decompression tests on 35kb data. The test code is as follows:
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream(new File("player.dat"));
FileChannel channel = fis.getChannel();
ByteBuffer bb = ByteBuffer.allocate((int) channel.size());
channel.read(bb);
byte[] beforeBytes = bb.array();
int times = 2000;
System.out.println("压缩前大小:" + beforeBytes.length + " bytes");
long startTime1 = System.currentTimeMillis();
byte[] afterBytes = null;
for (int i = 0; i < times; i++) {
afterBytes = GZIPUtil.compress(beforeBytes);
}
long endTime1 = System.currentTimeMillis();
System.out.println("压缩后大小:" + afterBytes.length + " bytes");
System.out.println("压缩次数:" + times + ",时间:" + (endTime1 - startTime1)
+ "ms");
byte[] resultBytes = null;
long startTime2 = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
resultBytes = GZIPUtil.uncompress(afterBytes);
}
System.out.println("解压缩后大小:" + resultBytes.length + " bytes");
long endTime2 = System.currentTimeMillis();
System.out.println("解压缩次数:" + times + ",时间:" + (endTime2 - startTime2)
+ "ms");
}
The GZIPUtil in the code is replaced according to different algorithms, and the test results are shown in the following figure:

Statistics were performed on the size before compression, size after compression, compression time, decompression time, and cpu peak.
Summarize
From the results, deflate, gzip and bzip2 pay more attention to the compression rate, and the compression and decompression time will be longer; the three compression algorithms of lzo, lz4 and snappy all have compression speed priority, and the compression rate will be slightly inferior; lzo, lz4 and snappy are a little lower at the cpu peak. Because within the tolerable compression rate, we pay more attention to compression and decompression time, as well as cpu usage, all of which end up using snappy, it is not difficult to find that snappy has the lowest compression and decompression time and cpu peak, and also has the lowest pressure rate. There aren't too many downsides.