Part 1: Introduction to Storm
1. Features The
Storm process resides in memory, and data is processed in memory without passing through the disk. (End the process by kill)
Architecture:
Nimbus, supervisor, worker
are similar to: master, follower, process respectively,
its programming model:
DAG and spout, bolt
Data transmission: ZMQ (twitter early product)
Netty
Storm is maintainable, with a graphical monitoring interface through StormUI.
Streaming processing (asynchronous and synchronous)
Asynchronous: the client submits data for settlement, and does not wait for the data calculation result. The MQ in the

middle can be kafaka, the storage can be DB,
Synchronization: After the client submits the data request, the calculation result is immediately obtained and returned to the client
Drpc

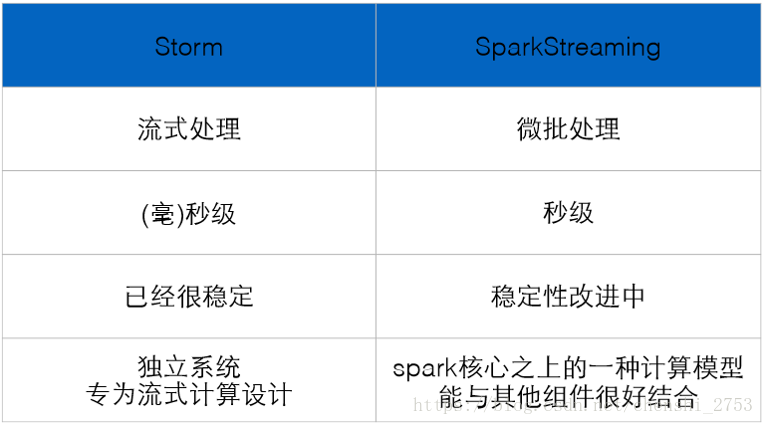
Storm: Pure stream processing
Spark Streaming: Micro batch processing
MapReduce: Batch
processing The relationship between the three
Storm: Processes and threads run in resident memory, data does not enter the disk, and data is transmitted through the network.
MapReduce: A batch computing framework designed for terabytes and petabytes of data.

Storm: pure stream processing
Specifically designed for stream processing
Data transmission mode is simpler and more efficient in many places It is
not impossible to do batch processing, it can also do micro batch processing to improve throughput
Spark Streaming: micro batch processing
Make RDDs small to approach stream processing with small batches.
Based on memory and DAG, processing tasks can be done quickly
2. Storm computing model
Basic concepts: Topology - Implementation of DAG
directed acyclic graph
Spout – data source
1. Read the tuple (Tuple) from the specified external data source and send it to the topology (Topology)
2. A Spout can send multiple data streams (Stream)
3. The core method in the Spout is nextTuple, which will be The Storm thread continuously calls and actively pulls data from the data source, and then sends the data generation tuple (Tuple) to the subsequent Bolt calculation through the emit method
Bolt - Data Stream Processing Component
1. Data processing in the topology is completed by Bolts. For simple tasks or data stream conversion, a single Bolt can be easily implemented; more complex scenarios often require multiple Bolts to complete in multiple steps
2. One Bolt can send multiple data streams (Stream)
3. The core method in Bolt is execute method, which is responsible for receiving a tuple of data and truly implementing the core business logic
The following diagram illustrates the calculation process of storm:
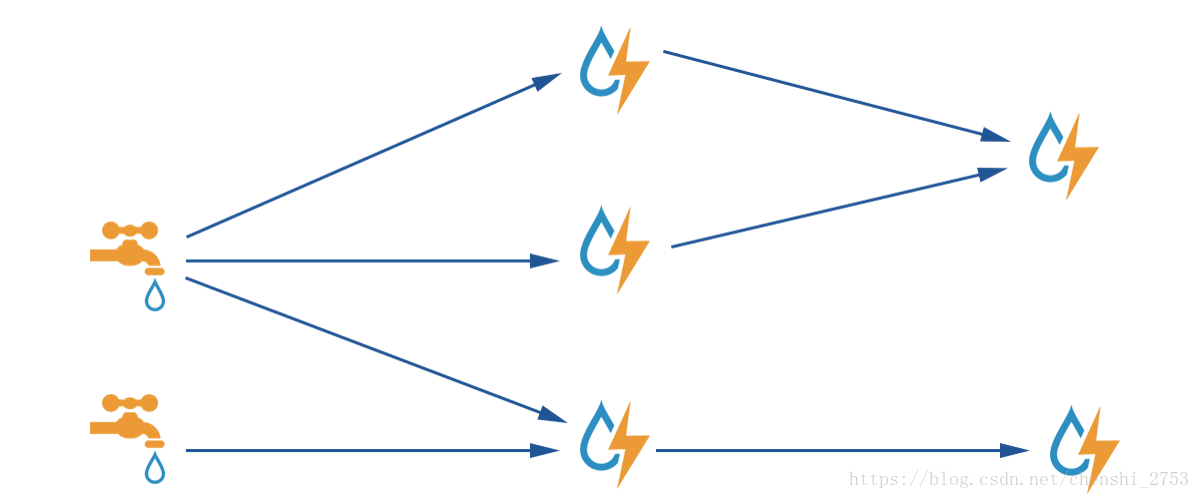
Remarks: The faucet is the spout end, sending the data stream to the bolt end. There can be multiple bolts. Different distribution strategies correspond to different thread processing methods. See Storm Grouping below .
Take a simple wordcount as an example as follows

Storm: The collected data is sent from the spout side through the smallest data unit of the tuple, and processed by the main logic of the bolt. If there are subsequent operations, you can also set the bolt.
3. Storm Grouping – data flow grouping (ie data distribution strategy)
1. Shuffle Grouping
randomly groups, randomly distributes tuples in the stream, and ensures that the number of tuples received by each bolt task is roughly the same.
Polling, evenly distributed
2. Fields Grouping Grouping
by fields, for example, grouping by the field "user-id", then tuple with the same "user-id" will be assigned to a task in the same Bolt, but different The "user-id" may be assigned to different tasks.
3.All Grouping
broadcast and send, for each tuple, all bolts will receive
4.Global Grouping
global grouping, and assign the tuple to the task with the lowest task id.
5.None Grouping
does not group, this grouping means that stream does not care how to group in the end. Currently this grouping has the same effect as Shuffle grouping. One difference is that Storm will put the bolt using none grouping into the same thread as the bolt's subscriber to execute (in the future, Storm will design this if possible).
6. Direct Grouping
is a special grouping method. Using this grouping means that the sender of the message (tuple) specifies which task of the message receiver processes the message. Only message streams declared as Direct Streams can declare this grouping method. And this message tuple must be emitted using the emitDirect method. The message handler can obtain the id of the task that processes its message through the TopologyContext (the OutputCollector.emit method will also return the id of the task)
7.Local or shuffle grouping
local or random grouping. If the target bolt has one or more tasks in the same worker process as the source bolt's tasks, the tuple will be randomly sent to those tasks in the same process. Otherwise, it is consistent with the normal Shuffle Grouping behavior.
8.customGrouping
customization is equivalent to implementing a partition by itself in mapreduce.
Use the first 2 more.
Demo implements summation and wordcount
The following is a simple accumulation implementation:
WSpout.java
/**
*
备注:此为storm计算累加的简单案例的spout的类
*/
public class WSpout extends BaseRichSpout {
Map map;
TopologyContext context;
SpoutOutputCollector collector;
int i = 0;
/**
* 初始设置配置
*/
@Override
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.map = map;
this.context = context;
this.collector = collector;
}
/**
* 被线程循环调用
*/
@Override
public void nextTuple() {
i++;
List num = new Values(i);
this.collector.emit(num);
System.err.println("storm======" + i);
Utils.sleep(1000);
}
/**
* 申明 申明发送的数据 bolt 通过申明来拿到数据
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("n"));
}
}Wbolt.java
public class Wbolt extends BaseRichBolt {
Map map;
TopologyContext contex;
OutputCollector collector;
int sum = 0;
@Override
public void prepare(Map map, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.contex = context;
this.map = map;
}
@Override
public void execute(Tuple input) {
int i = input.getIntegerByField("n");
sum += i;
System.err.println(sum);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO:后续无操作则不进行处理
}Test.java
/**
* 异步的方式,所谓异步也就是线程对CPU资源抢占的过程。谁快谁先拿到资源。
* 如果同步了,那单线程线性执行流程,第一个完成第二个完成。这样CPU资源可能浪费,有时候还会出现阻塞的现象。
*/
public class Test {
public static void main(String[] args) {
// 使用构建者模式构建来构建当前的storm的拓扑结构
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("wsspout", new WSpout());
tb.setBolt("wsbolt", new Wbolt()).shuffleGrouping("wsspout");
// 设置storm集群运行方式
LocalCluster loc = new LocalCluster();
loc.submitTopology("wsum", new Config(), tb.createTopology());
}
}The following is an example of wordcount:
WcSpout.java
public class WcSpout extends BaseRichSpout {
Map map;
TopologyContext context;
SpoutOutputCollector collcoter;
String[] text = { "chen shi xing kong", "tian chen", "chen shi" };
Random random = new Random();
@Override
public void open(Map map, TopologyContext context, SpoutOutputCollector collcoter) {
this.map = map;
this.context = context;
this.collcoter = collcoter;
}
@Override
public void nextTuple() {
List line = new Values(text[random.nextInt(text.length)]);
this.collcoter.emit(line);
System.out.println("spout emit -----" + line);
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}WsplitBolt.java
public class WsplitBolt extends BaseRichBolt {
OutputCollector collector;
@Override
public void prepare(Map map, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
List wd = new Values(word);
this.collector.emit(wd);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("w"));
}WcountBolt.java
public class WcountBolt extends BaseRichBolt {
Map map = new HashMap<String, Integer>(); // key:单词 value:个数
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
}
@Override
public void execute(Tuple input) {
String word = input.getString(0);
// 定义初始值
int count = 1;
// 若单词已出现,则获取该单词出现的次数,并让count累加
if (map.containsKey(word)) {
count = (int) map.get(word) + 1;
}
map.put(word, count);
// 展示单词及其出现的次数
System.err.println("word=" + word + "-------" + "num=" + count);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}