This time I will introduce you to multi-threaded programming in Python. The titles are as follows:
- Introduction to Python Multithreading
- The threading module of Python multithreading
- Lock thread lock for Python multithreading
- Python multithreading Python's GIL lock
- ThreadLocal for Python multithreading
- Multiprocessing vs Multithreading
- Execution characteristics of multi-process and multi-thread comparison
- Switching between multi-process and multi-thread comparison
- Computation-intensive and IO-intensive comparison of multiprocessing and multithreading
Introduction to Python Multithreading
A process consists of several threads. In the Python standard library, there are two modules thread and threading that provide an interface for scheduling threads. Because thread is a low-level module, many functions are not perfect, we generally only use threading , a relatively complete high-level module, so here we only discuss the use of threading module.
The threading module of Python multithreading
To start a thread, we just need to pass a function to the Thread instance, and then call start() to run it, which is exactly the same as the way we manipulated the process to call the Process instance.

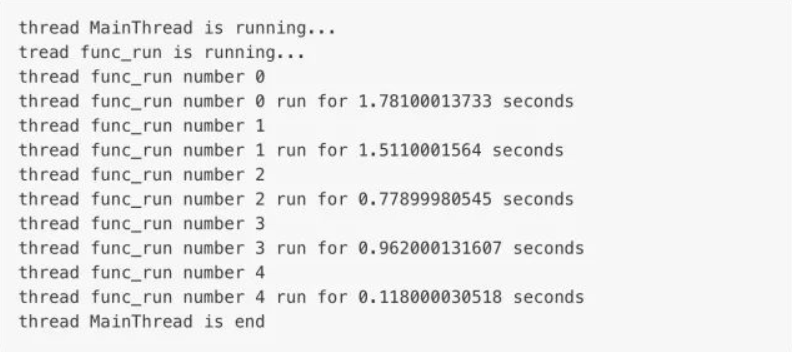
The current_thread() function is used to return the instance of the current thread. The name of the main thread instance is MainThread . The name of the child thread can be given at the time of creation, or it can be given names such as Thread-1 and Thread-2 by default .
Lock thread lock for Python multithreading
The biggest difference between multi-process and multi-thread is that for multi-process, a copy of the same variable exists in each process without affecting each other, while multi-threading is not the case, all threads share all variables, therefore, any variable can be modified by any thread. In order to avoid the dangerous situation of multiple threads modifying the same variable at the same time.
First we need to understand how multiple threads modify a variable at the same time.
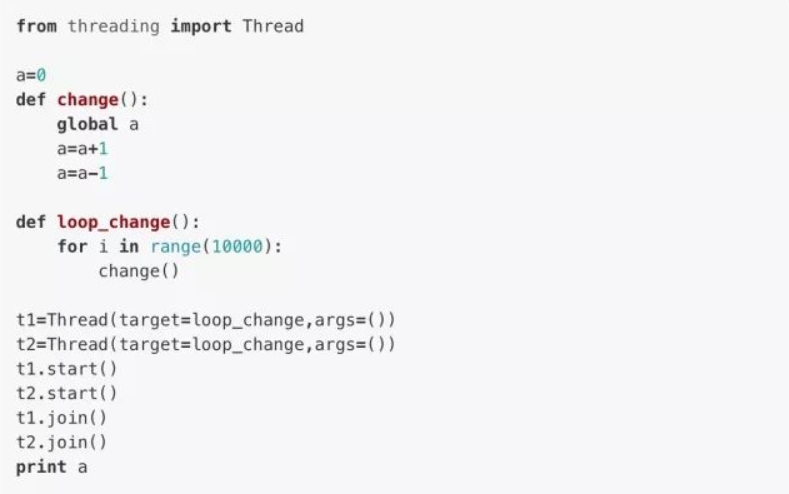

In theory, no matter how we call the function change() , the value of the shared variable a should be 0 , but in fact, because the two threads t1 and t2 run alternately too many times, the result of a may not be 0 .
To understand this situation, it is first necessary to briefly understand the underlying working principle of the CPU executing code:
In programming languages, when a line of code runs at the bottom layer, it is not necessarily completed as a line. For example, the above code a = a + 1 , the actual operation mode of the CPU during processing is to first use a temporary variable to store a+
The value of 1, and then assign the value of this temporary variable to a. If you have studied arm development, you can understand that when the CPU is working, it actually stores the values a and 1 into two registers respectively, and then puts The values of the two registers are added and the result is stored in the third register, and then the value of the third register is stored and overwritten in the register that originally held the value of a. In code language, it can be understood as follows:

Therefore, because both threads call their own registers, or have their own temporary variables c3 , when t1 and t2 run alternately, the situation described by the following code may occur:

In order to avoid this from happening, we need to provide thread locks to ensure that when one thread obtains the right to call change() , another thread cannot execute the change() method at the same time until the lock is released and the The lock can continue to modify.
We create a thread lock with threading.lock() method
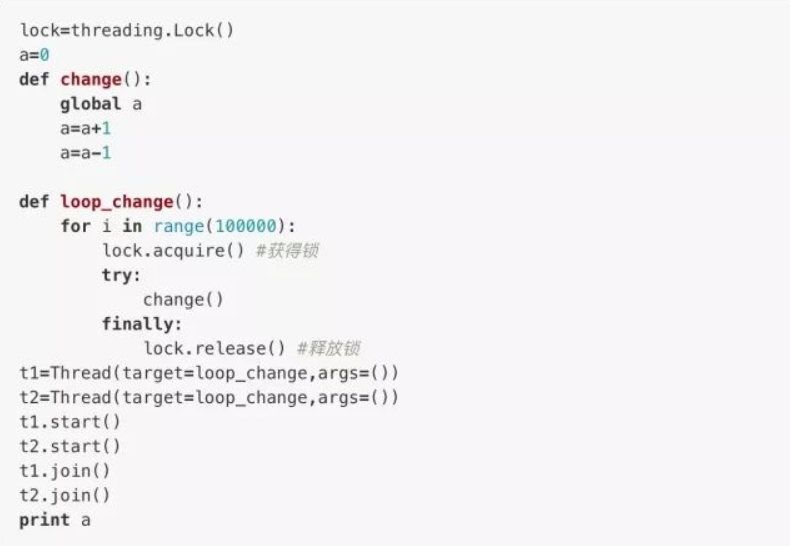

This way, no matter how you run it, the result will be the 0 we expect.
When multiple threads execute lock.acquire() at the same time, only one thread can successfully acquire the thread lock and then continue to execute the code, and other threads can only wait for the release of the lock. The thread that acquires the lock at the same time must remember to release it, otherwise it will become a dead thread. So we will use try...finally... to ensure the lock is released. However, the problem with locks is that on the one hand, the original multi-threaded task actually becomes a single-threaded operation mode (although for Python's pseudo multi-threading, this does not cause any performance degradation), and on the other hand, Since there can be multiple locks, different threads may hold different locks and try to acquire each other's locks, which may cause deadlocks and cause multiple threads to hang. At this time, the operating system can only be forced to terminate .
Python multithreading Python's GIL lock
For a multi-core CPU, it can execute multiple threads simultaneously. We can see the resource occupancy rate of the CPU through the task manager provided by Windows. Therefore, when we provide an infinite loop of dead threads, the occupancy rate of one CPU core will increase to 100%. If we provide two, it will be There is a core occupancy rate to 100%. This does happen if we do it in java or C, but if we try it in Python


It can be seen that we know from multiprocessing.cpu_count() that we have 4 CPUs, and then print 4 lines to indicate that 4 threads have been executed. At this time, our CPU usage should be full, but in fact
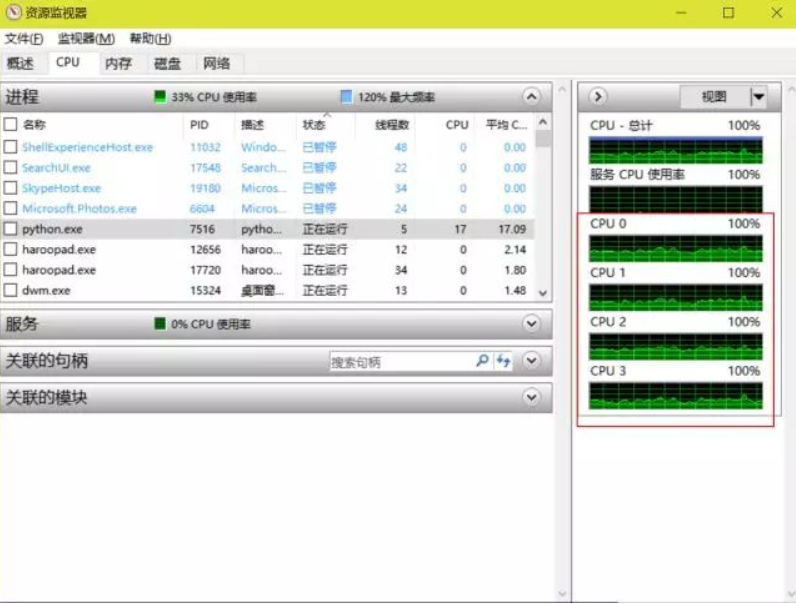
我们从红框中看到,情况并非如此。实际上哪怕我们启用再多的线程,CPU的占用率也不会提高多少。这是因为尽管Python使用的是真正的线程,但Python的解释器在执行代码时有一个GIL锁(Gloabal Interpreter Lock),不论是什么Python代码,一旦执行必然会获得GIL锁,然后每执行100行代码就会释放GIL锁使得其它线程有机会执行。GIL锁实际上就给一个Python进程的所有线程都上了锁,因此哪怕是再多的线程,在一个Python进程中也只能交替执行,也即是只能使用一个核。
Python多线程之ThreadLocal
既然我们已经知道,一个全局变量会受到所有线程的影响,那么,我们应该如何构建一个独属于这个线程的“全局变量”?换言之,我们既希望这个变量在这个线程中拥有类似于全局变量的功能,又不希望其它线程能够调用它,以防止出现上面所述的问题,该怎么做?

可以看到,在这个子线程中,如果我们希望函数do_task1()和do_task2()能用到变量a,则必须将它作为参数传进去。
使用ThreadLocal对象便是用于解决这个问题的方法而免于繁琐的操作,它由threading.local()方法创建:


我们可以认为ThreadLocal的原理类似于创建了一个词典,当我们创建一个变量local_varient.a的时候实际上是在local_varient这个词典里面创建了数个以threading.current_thread()为关键字(当前线程),不同线程中的a为值的键值对组成的dict,可以参照下面这个例程:

结果与上面用ThreadLocal的例程是一样的。当然,我在这里只是试图简单的描述一下ThreadLocal的工作原理,因为实际上它的工作原理和我们上面利用dict的例程并不是完全一样的,因为ThreadLocal对象可供传给的变量完全不只一个:

甚至local_varient.c、local_varient.d…都可以,没有一定的数量限制。而dict中能用threading.current_thread()做关键字的键值对都只能有一个不是吗。
进程和线程的比较
在初步了解进程和线程以及它们在Python中的运用方式之后,我们现在来讨论一下二者的区别与利弊。
多进程与多线程比较之执行特点
首先,我们简单了解一下多任务的工作模式:通常我们会将其设计为Master-Worker 模式,Master负责分配任务,Worker负责执行任务,多任务环境下通常是一个Master对应多个Worker。
那么多进程任务实现Master-Worker,主进程就是Master,其它进程是Worker。而多线程任务,主线程Master,子线程Worker。
先来说说多进程,多进程的优点就在于,它的稳定性高。因为一个子进程的崩溃不会影响到其它子进程和主进程(主进程挂了还是会全崩的)。但多进程的问题就在于,其创建进程的开销过大,特别是Windows系统,其多进程的开销要比使用fork()的Unix/Linux系统大的多得多。并且,对于一个操作系统本身而言,它能够同时运行的进程数也是有限的。
多线程模式占用的资源消耗没有多进程那么大,因此它也往往会更快一些(但似乎也不会快太多?但至少在Windows下多线程的效率往往要比多进程要高),而且,多线程模式与多进程模式正好相反,一个线程挂掉会直接让进程内包括主线程的所有的线程都崩溃,因为所有线程共享进程的内存。在Windows系统中,如果我们看到了这样的提示“该程序执行了非法操作,即将关闭”,那往往就是因为某个线程出现问题导致整个进程的崩溃。
多进程与多线程比较之切换
在使用多进程或多线程的时候都应该考虑线程数或者进程数切换的开销。无论是进程还是线程,如果数量太多,那么效率是肯定上不去的。
因为操作系统在切换进程和线程时,需要先保存当前执行的现场环境(包括CPU寄存器的状态,内存页等),然后再准备另一个任务的执行环境(恢复上次的寄存器状态,切换内存页等),才能开始执行新任务。这个过程虽然很快,但再快也是需要耗时的,因此一旦任务数量过于庞大,那么浪费在准备环境的时间就也会非常巨大。
多进程与多线程比较之计算密集型和IO密集型
考虑多任务的类型也是我们判断如何构建工作模式的一个重要点。我们可以将任务简单的分为两类:计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的运算,消耗CPU资源,例如一些复杂的数学运算,或者是一些视频的高清解码运算等等,纯靠CPU的计算能力来执行的任务。这种任务虽然也可以用多任务模式来完成,但任务之间切换的消耗往往比较大,因此若是要高效的进行这类任务的运算,计算密集型任务同时进行的数量最好不要超过CPU的核心数。
而对于语言而言,代码运行的效率对于计算密集型任务也是至关重要,因此,类似于Python这样的高级语言往往不适合,而像C这样的底层语言的效率就会更高。好在Python处理这类任务时用的往往是用C编写的库,但若是要自己实现这类任务的底层计算功能,还是以C为主比较好。
IO密集型的特点则是要进行大量的输入输出,涉及到网络、磁盘IO的任务往往都是IO密集型任务,这类任务消耗CPU的资源并不高,往往时间都是花在等待IO操作完成,因为IO操作的速度往往都比CPU和内存运行的速度要慢很多。对于IO密集型任务,多任务执行提升的效率就会很高,但当然,任务数量还是有一个限度的。
而对于这类任务使用的编程语言,Python这类开发效率高的语言就会更适合,因为能减少代码量,而C语言效果就很差,因为写起来很麻烦。
现代操作系统对IO操作进行了巨大的改进,其提供了异步IO的操作来实现单进程单线程执行多任务的方式,它在单核CPU上采用单进程模型可以高效地支持多任务。而在多核CPU上也可以运行多个进程(数量与CPU核心数相同)来充分地利用多核CPU。通过异步IO编程模型来实现多任务是目前的主流趋势。而在Python中,单进程的异步编程模型称为协程。