In this article, I mainly introduce how to embed a machine learning model into the web system. The main contents of this article include:
1. Build a simple web using flask
2. Embed the machine learning model into the web system
3. Update the model based on user feedback
It mainly includes three pages, a comment submission page, a classification result page, and a thank you page. When the user submits a comment and jumps to the result page, the background predicts whether the user's comment belongs to a positive or negative comment based on the existing model, returns which type of comment belongs to, and returns the probability of belonging to that type. Provide two user feedback result buttons, if the user clicks the correct button, the prediction is correct, otherwise the prediction is wrong, and the result is saved to the SQLlite database, and then jumps to the thank you page.
1. Project structure
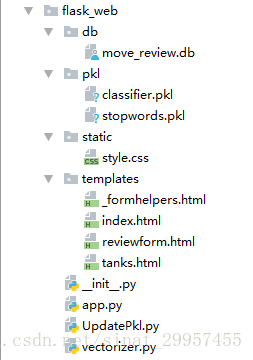
db: SQLite database files are stored in the directory.
pkl: Stores the model file, stopwords.pk is the stop word file, and classifer.pkl is the model file.
static: It is a static file directory, mainly storing js and css files.
templates: is the template file directory, used to store html files.
app.py: The main file, including functions such as interface jumping and model prediction.
updatePkl.py: Update file for the model.
vectorizer.py: Convert reviews into feature vectors for easy prediction.
2. Interface description
The interface is relatively simple, and there are not too many styles to adjust, mainly to achieve functions.
1. User submit comments interface
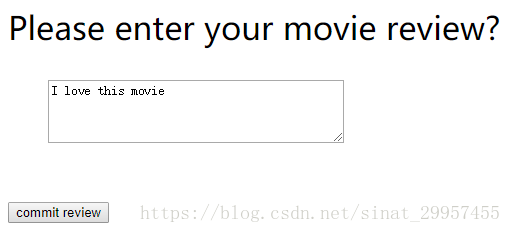
Users can enter their own comments on this interface and submit them.
2. Classification result page

Users can view the classification results of their own comments through this page, and can give corresponding feedback. If the user does not confirm whether it is correct, the category to which this comment belongs will not be stored in the SQLite database.
3. Thank you page
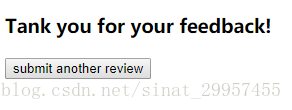
Through this interface, you can jump to and submit comments interface. Use SQLiteStudio to view database save comments

Third, the realization of the function
1. Convert comments into feature vectors
import re
import pickle
from sklearn.feature_extraction.text import HashingVectorizer
from nltk.stem.porter import PorterStemmer
import warnings
warnings.filterwarnings("ignore")
#load stopwords
stop = pickle.load(open("pkl/stopwords.pkl","rb"))
#Remove HTML tags and punctuation, remove stop words
def tokenizer(text):
#Remove HTML tags
text = re.sub("<[^>]*>","",text)
#Get all emojis
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text.lower())
#remove punctuation
text = re.sub("[\W]+"," ",text.lower())+" ".join(emoticons).replace("-","")
#remove stop words
tokenized = [word for word in text.split() if word not in stop]
# extract stem
porter = PorterStemmer()
#return the list of words after removing stop words
return [porter.stem(word) for word in tokenized]
#Get the feature vector of comments through HashingVectorizer
vect = HashingVectorizer(decode_error="ignore",n_features=2**21,preprocessor=None,tokenizer=tokenizer)
2. Main functions
import pickle
import sqlite3
import numpy as np
from flask import Flask,render_template,request
from wtforms import Form,TextAreaField,validators
from flask_web.vectorizer import vect
#Create a falsesk object
app = Flask(__name__)
#load classification model
clf = pickle.load(open("pkl/classifier.pkl","rb"))
#Create a comment database, run this method before app.py runs
def create_review_db():
conn = sqlite3.connect("db/move_review.db")
c = conn.cursor()
#move_review mainly includes four fields, review_id (review ID, primary key auto-increment), review (review content), sentiment (review category), review_date (review date)
c.execute("CREATE TABLE move_review (review_id INTEGER PRIMARY KEY AUTOINCREMENT,review TEXT"
",sentiment INTEGER,review_date TEXT)")
conn.commit()
conn.close()
# save the comments to the database
def save_review(review,label):
conn = sqlite3.connect("db/move_review.db")
c = conn.cursor()
#Insert comments into database
c.execute("INSERT INTO move_review (review,sentiment,review_date) VALUES "
"(?,?,DATETIME('now'))",(review,label))
conn.commit()
conn.close()
#Get the classification result of the comment
def classify_review(review):
label = {0:"negative",1:"positive"}
#Convert comments into feature vectors
X = vect.transform(review)
#Get comment integer class label
Y = clf.predict(X)[0]
#Get the string class label of the comment
label_Y = label[Y]
#Get the probability of the category the comment belongs to
test = np.max (clf.predict_test (X))
return Y,label_Y,test
#Jump to the user submit comment interface
@app.route("/")
def index():
# Verify that the text entered by the user is valid
form = ReviewForm(request.form)
return render_template("index.html",form=form)
#Jump to the comment classification result interface
@app.route("/main",methods=["POST"])
def main():
form = ReviewForm(request.form)
if request.method == "POST" and form.validate():
#Get the comments submitted by the form
review_text = request.form["review"]
#Get the classification result of the comment, class label, probability
Y,lable_Y,test = classify_review([review_text])
#Save the probability as a decimal and convert it to a percentage
proba = float("%.4f"%proba) * 100
# Return the classification results to the interface for display
return render_template("reviewform.html",review=review_text,Y=Y,label=lable_Y,probability=proba)
return render_template("index.html",form=form)
#user thank you interface
@app.route("/tanks",methods=["POST"])
def tanks():
# Determine whether the user clicks the correct button or the wrong button
btn_value = request.form["feedback_btn"]
#get comments
review = request.form["review"]
#Get the category label to which the comment belongs
label_temp = int(request.form["Y"])
#If correct, the class label is unchanged
if btn_value == "Correct":
label = label_temp
else:
#If wrong, the class label is opposite
label = 1 - label_temp
save_review(review,label)
return render_template("tanks.html")
class ReviewForm(Form):
review = TextAreaField("",[validators.DataRequired()])
if __name__ == "__main__":
#Start service
app.run()
3. Model update
import pickle
import sqlite3
import numpy as np
from flask_web.vectorizer import vect
#Update model method, update 10000 comments each time
def update_pkl(db_path,clf,batch_size=10000):
conn = sqlite3.connect(db_path)
c = conn.cursor()
c.execute("SELECT * from review")
# get all the comments
results = c.fetchmany(batch_size)
while results:
data = np.array(results)
#get comments
X = data[:,1]
#Obtain
Y = int(data[:,2])
classes = np.array([0,1])
#Convert comments into feature vectors
x_train = vect.transform(X)
#update model
clf.partial_fit(x_train,Y,classes=classes)
results = c.fetchmany(batch_size)
conn.close()
return None
if __name__ == "__main__":
#load model
clf = pickle.load(open("pkl/classifier.pkl", "rb"))
#update model
update_pkl("db/move_review.db",clf)
# save the model
pickle.dump(clf,open("pkl/classifier.pkl","wb"),protocol=4)
Why run the update model from another file instead of updating the model directly after the user submits feedback?
If there are many users commenting at the same time, updating the model directly after the user submits the feedback may cause the model file to be damaged when the model file is updated. It is recommended to update the model file locally before uploading it to the server.