Memory cgroup leakage is a common problem in K8s (Kubernetes) clusters, which can lead to tight node memory resources, or even cause the node to be unresponsive and only restart the server to recover; most developers will drop the cache regularly or close the kernel kmem accounting evade. Based on the practical case of the NetEase Shufan kernel team, this article analyzes the root cause of the memory cgroup leak problem, and provides a kernel-level solution to fix the problem.
background
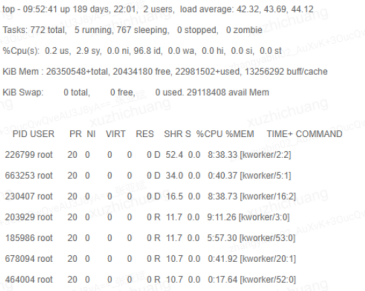
The operation and maintenance monitoring found that some cloud host computing nodes and K8s (Kubernetes) nodes have abnormally high load problems. The specific manifestation is that the system is running very slowly, the load continues to be 40+, and the CPU usage of some kworker threads is high or at D status, has already affected the business, and needs to analyze the specific reasons.
identify the problem
Phenomenon Analysis
For the problem of abnormal cpu usage, perf is an essential tool. Observing the hotspot function through perf top, it is found that the usage rate of the kernel function cache_reap will increase intermittently.
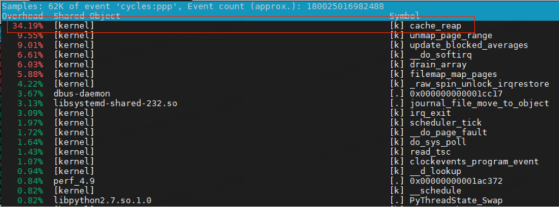
Open the corresponding kernel code, the cache_reap function is implemented as follows:
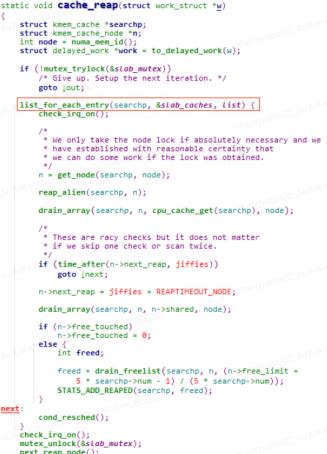
It is not difficult to see that this function mainly traverses a global slab_caches linked list, which records all slab memory objects related information on the system.
By analyzing the code flow related to the slab_caches variable, it is found that each memory cgroup corresponds to a memory.kmem.slabinfo file.
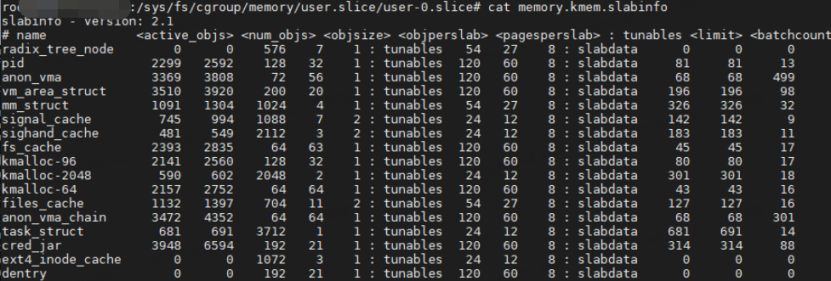
This file records the slab-related information applied by each memory cgroup group process. At the same time, the slab objects of the memory cgroup group will also be added to the global slab_caches linked list. Is it because there is too much data in the slab_caches linked list, which leads to the comparison of traversal time. long, causing the CPU to run high?
There is too much data in the slab_caches linked list, so the premise must be that the number of memory cgroups is particularly large. Naturally, we want to count how many memory cgroups exist on the system, but when we count the memory in the /sys/fs/cgroup/memory directory The number of cgroup groups is found to be less than 100 memory cgroups. The memory.kmem.slabinfo file in each memory cgroup contains dozens of records at most, so the number of slab_caches linked list members will not be at most. There are more than 10,000, so no matter how you look at it, there will be no problem.

In the end, we still start with the most primitive function cache_reap. Since this function consumes more CPU, we can directly trace the function to analyze where the execution time is relatively long in the code.
Confirm root cause
Through a series of tools to track the cache_reap function, it is found that the number of members of the slab_caches linked list has reached an astonishing millions, which is very different from the number we actually calculated.
Then check the current cgroup information of the system through cat /proc/cgroup, and find that the number of memory cgroups has accumulated to 20w+. It is obviously not normal to have so many cgroups on cloud host computing nodes. Even on K8s (Kubernetes) nodes, cgroups of this order of magnitude cannot be generated normally by container services.
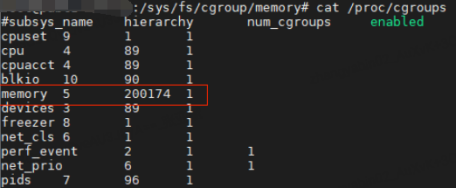
So why is there such a big difference between the number of memory cgroups counted in the /sys/fs/cgroup/memory directory and the number of records in the /proc/cgroups file? Caused by memory cgroup leak!
The detailed explanation is as follows:
Many operations on the system (such as creating and destroying containers/cloud hosts, logging in to hosts, cron scheduled tasks, etc.) will trigger the creation of temporary memory cgroups. The processes in these memory cgroup groups may generate cache memory (such as accessing files, creating new files, etc.) during the running process, and the cache memory will be associated with the memory cgroup. When the process in the memory cgroup group exits, the corresponding directory in the /sys/fs/cgroup/memory directory of the cgroup group will be deleted. However, the cache memory generated by the memory cgroup group will not be actively reclaimed. Since the memory cgroup object is still referenced by the cache memory, the objects in the memory cgroup will not be deleted.
During the positioning process, we found that the cumulative number of memory cgroups is still growing slowly every day, so we tracked the creation and deletion of the memory cgroup directory of the node, and found that the following two trigger sources will cause memory cgroup leakage:
-
Specific cron scheduled task execution
-
Users log in and out of nodes frequently
The reasons for the memory cgroup leakage caused by these two trigger sources are related to the systemd-logind login service. When executing cron scheduled tasks or logging in to the host, the systemd-logind service will create a temporary memory cgroup, and wait until the cron task is executed or After the user logs out, the temporary memory cgroup will be deleted, which will lead to memory cgroup leaks in scenarios with file operations.
Reproduce method
After analyzing the triggering scenarios of memory cgroup leaks, it is much easier to reproduce the problem:

The core reproduction logic is to create a temporary memory cgroup, perform file operations to generate cache memory, and then delete the memory cgroup temporary directory. Through the above method, the 40w memory cgroup residual scene can be quickly reproduced in the test environment.
solution
By analyzing the problem of memory cgroup leakage, we have basically figured out the root cause and triggering scenarios of the problem, so how to solve the problem of leakage?
Option 1: drop cache
Since the cgroup leak is caused by the inability to reclaim the cache memory, the most direct solution is to clear the system cache through "echo 3 > /proc/sys/vm/drop_caches".
However, clearing the cache can only alleviate it, and cgroup leaks will still occur in the future. On the one hand, it is necessary to configure daily scheduled tasks to drop cache. At the same time, the drop cache action itself will consume a lot of CPU and affect the business. For nodes that have formed a large number of cgroup leaks, the drop cache action may be stuck in the process of clearing the cache, causing new question.
Option 2: nokmem
The kernel provides the cgroup.memory = nokmem parameter to disable the kmem accounting function. After configuring this parameter, the memory cgroup will not have a separate slabinfo file, so that even if the memory cgroup leaks, it will not cause the kworker thread CPU to run high.
However, this solution needs to restart the system to take effect, which will have a certain impact on the business, and this solution cannot completely solve the fundamental problem of memory cgroup leakage, but can only alleviate the problem to a certain extent.
Option 3: Eliminate the trigger source
The two trigger sources that cause cgroup leakage found in the above analysis can all be eliminated.
For the first case, confirm that the cron task can be closed by communicating with the corresponding business module;
For the second case, it can be solved by setting the corresponding user as the background resident user through loginctl enable-linger username.
After setting as a resident user, when the user logs in, the systemd-logind service will create a permanent memory cgroup group for the user. The user can reuse this memory cgroup group every time he logs in, and it will not be deleted after the user logs out, so There will be no leakage.
At this point, it seems that the problem of memory cgroup leakage has been solved perfectly, but in fact, the above solution can only cover the two known triggering scenarios, and does not solve the problem that cgroup resources cannot be completely cleaned and recycled. There may also be trigger scenarios for new memory cgroup leaks.
Solutions in the kernel
conventional plan
In the process of locating the problem, Google has found a lot of problems caused by cgroup leaks in container scenarios. There are cases reported on the centos7 series and the 4.x kernel, mainly because the kernel supports the cgroup kernel memory accounting feature. It is not perfect. When K8s (Kubernetes)/RunC uses this feature, there will be a problem of memory cgroup leakage.
The main solution is nothing more than the following avoidance schemes:
-
Execute drop cache regularly
-
Kernel configuration nokmem disable kmem accounting function
-
K8s(Kubernetes) disable KernelMemoryAccounting function
-
docker/runc disables the KernelMemoryAccounting feature
We are considering whether there is a better solution that can "completely" solve the problem of cgroup leakage at the kernel level?
kernel recycling thread
Through in-depth analysis of the memoy cgroup leak problem, we can see that the core problem is that although the cgroup directory temporarily created by systemd-logind will be automatically destroyed, the cache memory and related slab memory generated by file reading and writing are not immediately reclaimed. , due to the existence of these memory pages, the reference count of the cgroup management structure cannot be cleared, so although the directory mounted by the cgroup has been deleted, the related kernel data structure is still retained in the kernel.
Based on the tracking analysis of solutions to community-related problems and the ideas provided by Alibaba Cloud Linux, we implement a simple and direct solution:
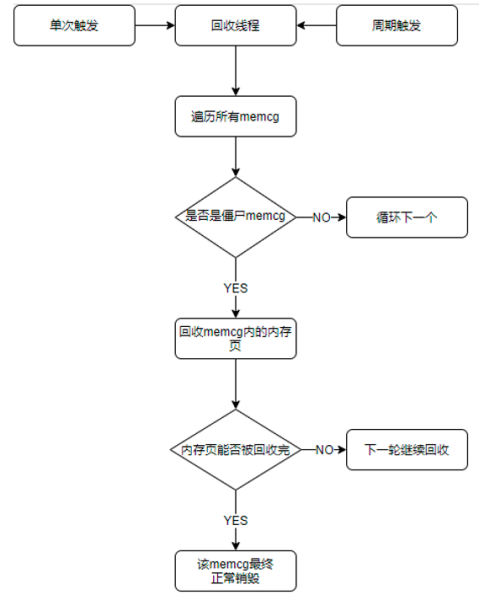
Run a kernel thread in the kernel, perform memory reclamation separately for these residual memory cgroups, and release the memory pages held by them to the system, so that these residual memory cgroups can be reclaimed by the system normally.
This kernel thread has the following characteristics:
-
Only reclaim remaining memory cgroups
-
This kernel thread priority is set to lowest
-
Actively cond_resched() every time you do a round of memory cgroup recycling to prevent CPU usage for a long time
The core process of recycling threads is as follows:
Functional Verification
The function and performance test of the kernel merged into the kernel recycling thread is as follows:
-
Open the recycling thread in the test environment, and the residual memory cgroup of the system can be cleaned up in time;
-
Simulate cleaning up 40w leaked memory cgroups, the maximum CPU usage of the recycling thread does not exceed 5%, and the resource usage is acceptable;
-
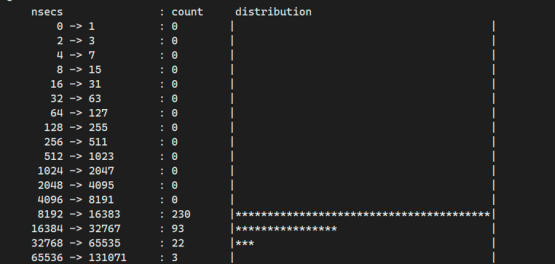
Test for the residual memory cgroup of super large size, recover one memory cgroup holding 20G memory, the execution time distribution of the core recovery function basically does not exceed 64us; it will not affect other services;
After the kernel recycling thread is enabled, the kernel LTP stability test is passed normally without increasing the risk of kernel stability.
It can be seen that by adding a new kernel thread to recycle the residual memory cgroup, the problem of cgroup leakage can be effectively solved with a small resource utilization rate. This solution has been widely used in NetEase private cloud, effectively improving NetEase container business. stability.
Summarize
The above is the analysis and positioning process of the memory cgroup leak problem that we shared, and the relevant solutions are given, and at the same time, it provides an idea to solve the problem at the kernel level.
In the long-term business practice, I deeply realize that the use and requirements of Linux kernel in K8s (Kubernetes)/container scenarios are all-round. On the one hand, the entire container technology is mainly built based on the capabilities provided by the kernel. To improve the stability of the kernel, the ability to locate and repair bugs in related modules is essential; on the other hand, the optimization/new features of the kernel for container scenarios emerge in an endless stream. We also continue to pay attention to the development of related technologies, such as using ebpf to optimize container networks, enhancing kernel monitoring capabilities, and using cgroup v2/PSI to improve container resource isolation and monitoring capabilities.
Author introduction: Zhang Yabin, NetEase Shufan kernel expert