table display
First, the two tables involved in the query, a user and an order table, the contents of the specific tables are as follows:
user table:
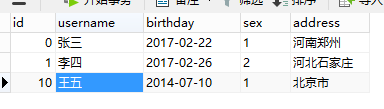
order table:
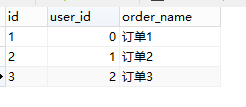
in
Determines whether the given value matches values in a subquery or list. When querying, first query the table of the subquery, then do a Cartesian product of the inner table and the outer table, and then filter according to the conditions. Therefore, when the internal table is relatively small, the speed of in is faster.
The specific sql statement is as follows:

1 SELECT 2 * 3 FROM 4 `user` 5 WHERE 6 `user`.id IN ( 7 SELECT 8 `order`.user_id 9 FROM 10 `order` 11 )
This statement is very simple. The data of the user_id found by the subquery is matched with the id in the user table and the result is obtained. The execution result of this statement is as follows:

What is its execution process like? Let's look together.
First, inside the database, query the subquery and execute the following code:
SELECT
`order`.user_id
FROM
`order`
After execution, the result is as follows:

At this point, a Cartesian product of the query result and the original user table is performed, and the result is as follows:
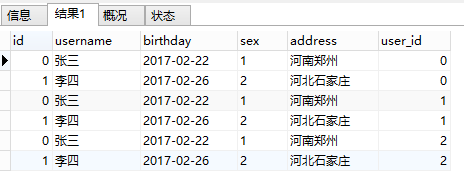
At this time, according to the condition of our user.id IN order.user_id, the results are filtered (that is, if the values of the id column and the user_id column are compared, they will be deleted if they are not equal). Finally, two pieces of data that meet the conditions are obtained.
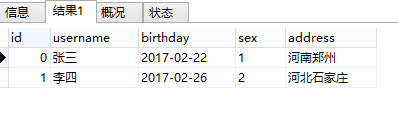
exists
Specify a subquery that checks for the existence of rows. Traverse the outer table and see if the records in the outer table are the same as the data in the inner table. If it matches, the result is put into the result set.
The specific sql statement is as follows:
1 SELECT 2 `user`.* 3 FROM 4 `user` 5 WHERE 6 EXISTS ( 7 SELECT 8 `order`.user_id 9 FROM 10 `order` 11 WHERE 12 `user`.id = `order`.user_id 13 )
The execution result of this sql statement is the same as the execution result of in above.

However, the difference is that their execution flow is completely different:
When using the exists keyword to query, first of all, what we first query is not the content of the subquery, but the table of our main query, that is to say, the sql statement we execute first is:
SELECT `user`.* FROM `user`
The result obtained is as follows:

Then, according to each record in the table, execute the following statement to judge whether the conditions behind where are true in turn:
EXISTS (
SELECT
`order`.user_id
FROM
`order`
WHERE
`user`.id = `order`.user_id
)
Returns true if true, otherwise returns false. If it returns true, the result of the row is retained, if it returns false, the row is deleted, and the result is returned at last.
Differences and application scenarios
The difference between in and exists: If the result set obtained by the subquery has fewer records, in should be used when the table in the main query is large and has an index. On the contrary, if the outer main query has fewer records, the table in the subquery Use exists when it is large and has an index. In fact, we distinguish between in and exists mainly because of changes in the driving order (this is the key to performance changes). If it is exists, then the outer table is the driving table, and it is accessed first. If it is IN, then the subquery is executed first, so We will aim to drive the fast return of the table, then the relationship between the index and the result set will be considered, and NULL will not be processed during IN.
in is a hash connection between the outer and inner tables, and exists is a loop for the outer, and the inner table is queried every time the loop is looped. The long-standing belief that exists is more efficient than in is inaccurate.
not in 和not exists
If the query statement uses not in, then both the inner and outer tables perform a full table scan without using the index; and the subquery of not extsts can still use the index on the table. So no matter the size of the table, using not exists is faster than not in.