Preamble
In the previous blog series one function a day, we concentrated on overcoming the obscure syntax in spark after another, and gained a lot of knowledge. If we use warfare as a metaphor, it means that our guerrilla warfare has achieved local and significant results. But if you want to shake the entire spark-streaming building, you also need to have an in-depth understanding of the entire runtime mechanism, knowing that the so-called interface applications and calls are some engineering encapsulated things, which only require skilled training. , but if you want to use it better, you must understand its mechanism from the bottom.
Before understanding the runtime mechanism in depth, I suggest that you think about this question. Why is the computing model used by spark a DAG model with wide dependencies as the dividing line? In my opinion, there are the following advantages. The first point is to divide according to different stages, which makes the calculation more efficient. Narrow dependencies such as x square can be directly operated in the form of pipes, while wide dependencies such as (x+y) ), it needs to wait until the parent dependency is ready to calculate, so this division can maximize the calculation rate. The second point is that due to the uncontrollability of distributed clusters, our data may be placed on the disk at any time, so that because we use the stage mode of processing, we can save the intermediate results on disk, without A situation where all data is lost due to downtime occurs.
Based on the above concepts, let's talk about some technical terms and the architecture of the spark runtime.
Terminologies
SparkContext
SparkContext is the core part of the entire Spark Application. It establishes a connection to the Spark Execution environment, it is also used to create Spark RDDs, accumulators, and broadcast variables, and it also takes responsibility for fetching spark services and running jobs. SparkContext is a client of Spark execution environment and acts as the master of Spark application . The above sentence expresses the essence of sparkcontext. Let me list the main functions of Spark Context:
- Getting the current status of spark application
- Canceling the job
- Canceling the Stage
- Running job synchronously
- Running job asynchronously
- Accessing persistent RDD
- Unpersisting ASD
- Programmable dynamic allocation
If you want to learn more about sparkcontext, please read "Understanding spark context in depth"
Spark Shell
Surprisingly, the spark shell is also a spark application written in scala. It provides a command-line environment that can help us better understand the features of spark and help us better build our own spark application. program.
Spark Application
Spark application is a complete computing framework that can run user-submitted programs. Even when it is not running a job, it will run its own process.
Task
A task is a work unit submitted to an executor. Each stage has some tasks, and a task corresponds to a partition .
The Same task is done over different partitions of RDD。
Job
A job is a parallel computing task composed of a series of tasks, which is activated by a function of type action. In other words, without action, the job will not be submitted.
Stages
Each job is divided into several small sets, called stages, which are interdependent. Regarding how stages are divided, please refer to the width and narrow dependence theory of RDD in spark, which is the example I mentioned at the beginning of the article. The final calculation result can only be obtained after all stages are calculated.
Architecture
Spark uses a master-slave structure, that is, a core coordinator and multiple workers, also known as executors, each executor is a separate java process . In other words a spark application is a set of drivers and all its executors, which can be run on a series of clusters with the help of the cluster manager . Standalone Cluster Manager is spark's default built-in cluster manager. In addition, Spark can also run on some open source cluster managers, such as Yarn and Mesos.
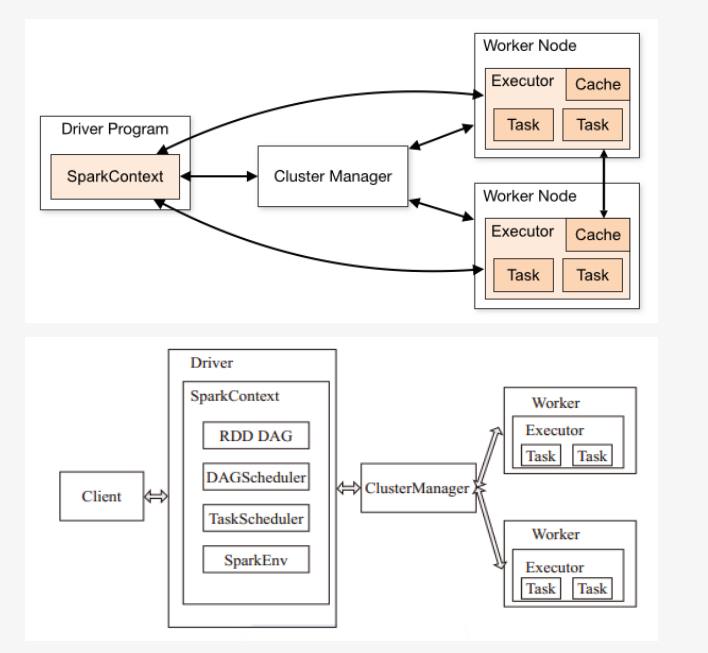
The Apache Spark Driver
The driver is the core coordinator in the entire spark. When an action method is called , the sparkcontext in the driver program will create a job and then submit it to the DAG Scheduler (DAG Scheduler creates the operator graph and submits the Job to the task Scheduler ) . Task Scheduler starts tasks through the cluster manager. In this way, with the help of the cluster manager, a complete spark program is started in the cluster.
From the perspective of the program, the main method runs in the driver, the driver runs the code submitted by the user, generates RDD, executes transformation and action functions, and creates SparkContext at the same time. These are the responsibilities of a driver. When a driver stops working, the entire application ends its life cycle.
The two most important roles of the driver are:
- Converting user program into the task.
- Scheduling task on the executor.
Looking at spark from a higher level, the RDD is generated from the input data source, a new RDD is obtained through a series of transformation functions, and then the action function is executed. In a spark program, the DAG of the operation is implicitly created, and when the driver runs, it converts the DAG into a physical-level executor.
Apache Spark Cluster Manager
In some cases, spark will rely on the cluster manager to launch executors, and even drivers are launched through it. It is a plugin in spark. On the cluster manager, the jobs and actions in the spark application are arranged by the Spark Scheduler in the order of FIFO. The resources occupied by the spark application can be dynamically adjusted according to the workload size, which is suitable for any cluster mode.
Apache Spark Executors
The individual task in the given Spark job runs in the Spark executors. Executors are launched once in the beginning of Spark Application and then they run for the entire lifetime of an application. Even if the Spark executor fails, the Spark application can continue with ease. There are two main roles of the executors:
- Runs the task that makes up the application and returns the result to the driver.
- Provide in-memory storage for RDDs that are cached by the user.
How to launch a Program in Spark
No matter which cluster manager we use, spark provides us with a simple script called spark-submit to facilitate us to submit our program. It starts the application on the cluster, can connect to different cluster managers and can control the resources required by our program.
How to Run Apache Spark Application on a cluster
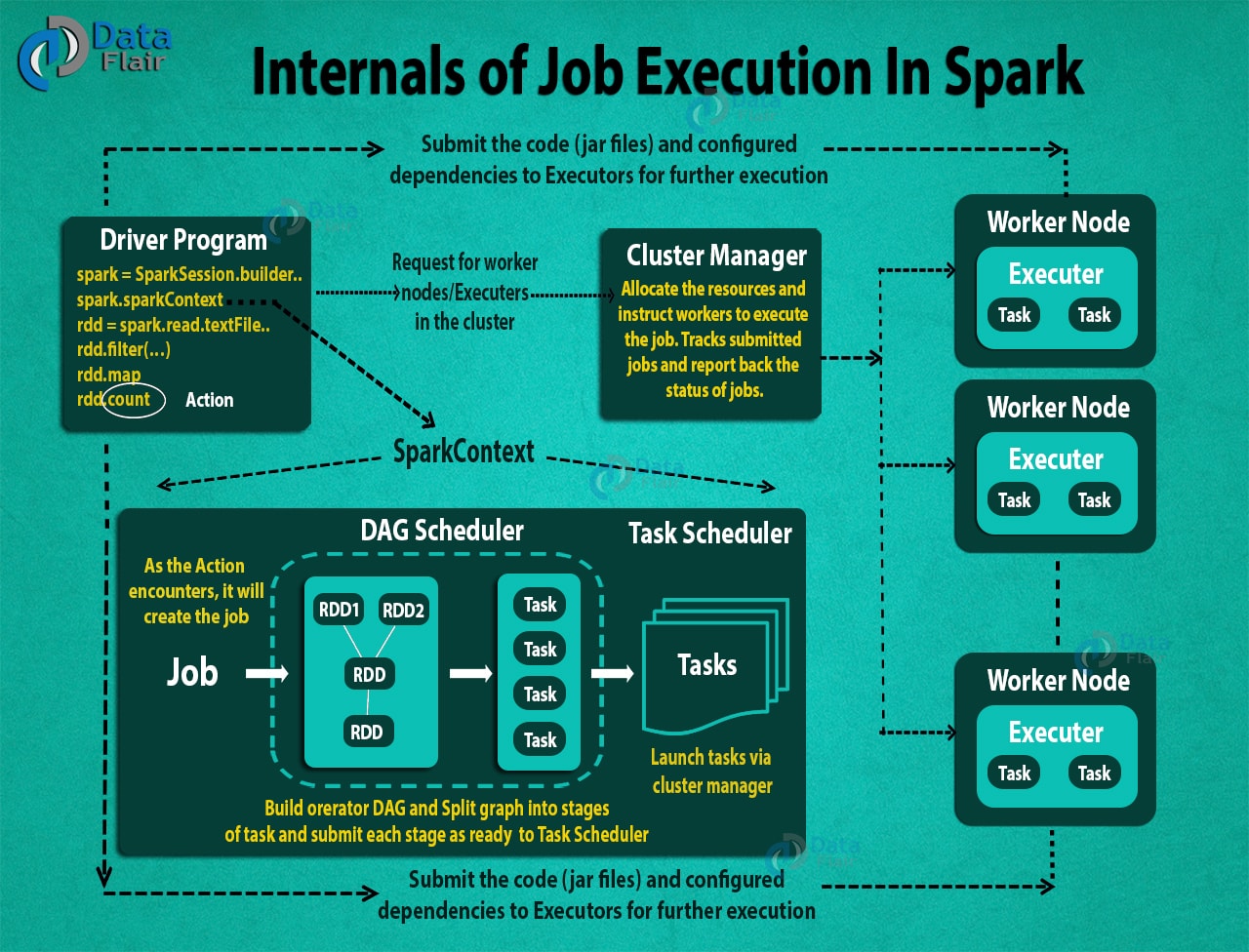
Above, we introduced the concepts of various terms in spark. If you find it confusing, it doesn't matter. Let's sort it out from a macro perspective:
- Users use spark-submit to submit programs.
- In spark-submit, the user-defined main() method is called. It also starts the driver program.
- The driver program will ask the cluster manager for the necessary resources to start executors.
- The cluster manager starts executors on behalf of the driver program.
- The driver process runs with the help of the user application. Based on the actions and transformation functions of RDD, the driver sends work to the executors in the form of tasks.
- Executors process tasks and return the calculation results to the driver through the cluster manager.