Original: http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/
As a software developer, you must have a complete and hierarchical understanding of how web applications work, including the technologies used by these applications: like browsers, HTTP, HTML, web servers, request processing, etc. .
This article will take a deeper look at what happens in the background when you enter a URL~
1. First of all, you have to enter the URL in the browser:

2. The browser looks up the IP address of the domain name

The first step in navigation is to find out its IP address by the domain name visited. The DNS lookup process is as follows:
- Browser caching – Browsers cache DNS records for a period of time. Interestingly, the OS doesn't tell the browser how long to store DNS records, so different browsers store a self-fixed amount of time (ranging from 2 minutes to 30 minutes).
- System cache - If the desired record is not found in the browser cache, the browser will make a system call (gethostbyname in windows). This will get the record in the system cache.
- Router Cache – Next, the preceding query request is sent to the router, which typically has its own DNS cache.
- ISP DNS Cache – The next thing to check is the server that the ISP caches DNS on. Corresponding cache records can generally be found here.
- Recursive Search - Your ISP's DNS server starts a recursive search with the nameservers, from the .com top-level nameservers to Facebook's nameservers. Generally, the cache of the DNS server will have the domain name in the .com domain name server, so the matching process to the top-level server is not so necessary.
DNS recursive lookup is shown in the following figure:
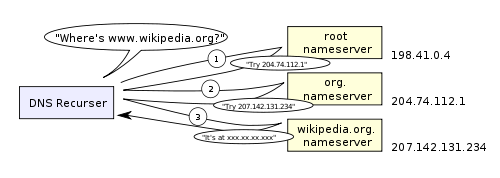
One of the worrisome things about DNS is that an entire domain name like wikipedia.org or facebook.com appears to correspond to a single IP address. Fortunately, there are several ways to remove this bottleneck:
- Round-robin DNS is a solution when DNS lookups return multiple IPs. For example, Facebook.com actually corresponds to four IP addresses.
- A load balancer is a hardware device that listens on a specific IP address and forwards network requests to clustered servers. Some large sites generally use this expensive high-performance load balancer.
- Geo-DNS improves scalability by mapping domain names to multiple different IP addresses based on the geographic location of the user. This way different servers can't update sync state, but it's great for mapping static content.
- Anycast is a routing technology that maps an IP address to multiple physical hosts. The fly in the ointment, Anycast is not well adapted to the TCP protocol, so it is rarely used in those programs.
Most DNS servers use Anycast for efficient low-latency DNS lookups.
3. The browser sends an HTTP request to the web server
Because dynamic pages like Facebook's homepage expire quickly or even immediately after being opened in the browser's cache, there's no doubt they can't read from it.
So, the browser will send the following request to the server where Facebook is located:
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
GET This request defines the URL to read : "http://facebook.com/". The browser itself defines ( User-Agent header), and what type of response it wants to accept ( Accept and Accept-Encoding header). The Connection header asks the server not to close the TCP connection for subsequent requests.
The request also includes cookies stored by the browser for that domain . As you may already know, cookies are key-values that are matched to track the state of a website across page requests. This way the cookies store the login username, the password assigned by the server and some user settings etc. Cookies are stored in the client as a text document and sent to the server each time a request is made.
There are many tools for viewing raw HTTP requests and their corresponding tools. The author prefers to use fiddler, of course there are other tools like FireBug. These softwares can be of great help when it comes to website optimization.
In addition to the get request, there is also a send request, which is often used in submitting forms. Send a request passing its parameters via the URL (eg: http://robozzle.com/puzzle.aspx?id=85). A send request sends its parameters after the request body headers.
Slashes like "http://facebook.com/" are critical. In this case, browsers can safely add slashes. And addresses like "http://example.com/folderOrFile" cannot automatically add slashes because the browser doesn't know whether folderOrFile is a folder or a file. At this time, the browser directly accesses the address without slashes, and the server responds with a redirection, resulting in an unnecessary handshake.
4. Permanent redirect response from facebook service
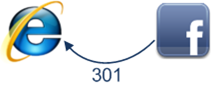
The picture shows the response from the Facebook server back to the browser:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
The server responds to the browser with a 301 Permanent Redirect response, so that the browser will visit "http://www.facebook.com/" instead of "http://facebook.com/".
Why does the server have to redirect instead of directly sending the content of the webpage that the user wants to see? There are many interesting answers to this question.
One of the reasons has to do with search engine rankings . You see, if a page has two addresses, like http://www.igoro.com/ and http://igoro.com/, search engines will think they are two sites, resulting in a search link for each are reduced, thereby lowering the ranking. And search engines know what 301 permanent redirects mean, so they will assign visits to addresses with www and without www to the same website ranking.
Another is that using different addresses will cause poor cache friendliness . When a page has several names, it may appear in the cache several times.
5. Browser Tracking Redirect Addresses
Now, the browser knows that "http://www.facebook.com/" is the correct address to visit, so it sends another get request:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
The header information has the same meaning as in the previous request.
6. The server "handles" the request

The server receives the get request, processes it, and returns a response.
On the surface, this may seem like a directional task, but in fact a lot of interesting things happen in the middle - a simple website like an author's blog, not to mention a website with a lot of traffic like facebook!
- Web Server Software
Web server software (like IIS and Apache) receives an HTTP request and then determines what request processing to perform to handle it. A request handler is a program (like ASP.NET, PHP, RUBY...) that can read a request and generate HTML in response.
For the simplest example, demand processing can be stored at the file level that maps the address structure of the website. An address like http://example.com/folder1/page1.aspx will map the file /httpdocs/folder1/page1.aspx. The web server software can be set to handle the corresponding requests manually, so that the publishing address of page1.aspx can be http://example.com/folder1/page1.
- Request processing
Request processing reads the request and its parameters and cookies. It will read and possibly update some data and store the data on the server. The request processing then generates an HTML response.
All dynamic websites face an interesting difficulty - how to store data. Half of the small sites will have an SQL database to store their data, and sites that store a lot of data and/or have a lot of traffic have to find some way to distribute the database across multiple machines. Solutions include: sharding (spreading data tables into multiple databases based on primary key values), replication, and simplified databases using weak semantic consistency.
Delegating work to batch processing is an inexpensive technique for keeping data updated. For example, Facebook needs to update its news feed in a timely manner, but the data-backed "people you may know" feature only needs to be updated every night (the author guesses that this is the case, how to improve the function is unknown). Batch job updates cause some less important data to become stale, but make data update farming faster and cleaner.
7. The server sends back an HTML response
The figure shows the response generated and returned by the server:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]
The entire response is 35kB in size, most of which are transferred as blobs after sorting.
The Content-Encoding header tells the browser to compress the entire response body with the gzip algorithm. After unpacking the blob block, you can see the expected HTML like this:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"
lang="en" id="facebook" class=" no_js">
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-language" content="en" />
...
Regarding compression, the header information indicates whether to cache the page, how to do it if cached, what cookies to set (not in the previous response) and privacy information, etc.
Note that the Content-type is set to " text/html " in the header. The header tells the browser to render the response content as HTML instead of downloading it as a file. The browser decides how to interpret the response based on the header information, but also considers other factors like the content of the URL extension.
8. The browser starts displaying HTML
Before the browser has fully accepted the entire HTML document, it has already started to display this page:
9. The browser sends to get the object embedded in the HTML
When the browser displays the HTML, it notices tags that need to get the content of other addresses. At this point, the browser will send a get request to retrieve the files.
Here are a few URLs that we need to refetch when we visit facebook.com:
- Image
http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
… - CSS style sheet
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
… - JavaScript file
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
These addresses go through a process similar to HTML reading. So the browser will look up these domains in DNS, send requests, redirects, etc...
But unlike dynamic pages, static files allow browsers to cache them. Some files may not need to communicate with the server, but read directly from the cache. The server's response includes information about how long static files are kept, so the browser knows how long to cache them. Also, each response may contain an ETag header (the entity value of the requested variable) that works like a version number, and if the browser observes that the file's version ETag information already exists, it stops the transfer of the file immediately.
Try to guess what " fbcdn.net " stands for in the address? The clever answer is "Facebook Content Delivery Network". Facebook utilizes a Content Delivery Network (CDN) to distribute static files like images, CSS tables and JavaScript files. Therefore, these files will be backed up in the data centers of many CDNs around the world.
Static content often represents the bandwidth of the site, and can also be easily replicated through a CDN. Often websites use third-party CDNs. For example, Facebook's static files are hosted by Akamai, the largest CDN provider.
For example, when you try to ping static.ak.fbcdn.net, you might get a response from one of the akamai.net servers. Interestingly, when you ping the same again, the server that responds may be different, indicating that the load balancing behind the scenes is working.
10. The browser sends an asynchronous (AJAX) request
Under the guidance of the great spirit of Web 2.0, the client still keeps in touch with the server after the page is displayed.
Take the Facebook chat feature, for example, which keeps in touch with the server to update the status of your brightly-grayed friends. To update the friend status of these avatars, JavaScript code executed in the browser sends an asynchronous request to the server. This asynchronous request is sent to a specific address, and it is a programmatically constructed get or send request. Still in the Facebook example, the client sends a post request to http://www.facebook.com/ajax/chat/buddy_list.php to get status information about which of your friends is online.
Speaking of this pattern, we must talk about "AJAX" - "Asynchronous JavaScript and XML", although there is no clear reason why the server responds in XML format. As another example, for asynchronous requests, Facebook will return some JavaScript snippets.
Among other things, fiddler is a tool that lets you see asynchronous requests sent by the browser. In fact, not only can you passively watch these requests, but you can proactively modify and resend them. It's really frustrating for online game developers who score points to be so easily fooled by AJAX requests. (Of course, don't lie to people like that~)
The Facebook chat feature provides an interesting example of a problem with AJAX: pushing data from the server to the client. Because HTTP is a request-response protocol, chat servers cannot send new messages to clients. Instead, the client has to poll the server every few seconds to see if it has new messages.
Long polling is an interesting technique to reduce server load when these situations occur. If the server has no new messages when polled, it ignores the client. When a new message from the client is received before the timeout expires, the server will find the unfinished request and return the new message to the client as a response.
in conclusion
Hope after reading this article, you can understand how different network modules work together