A brief introduction to linked lists
Why do you need a linear linked list?
Of course, it is to overcome the shortcomings of the sequential list. In the sequential list, when inserting and deleting operations, a large number of moving elements are required, resulting in a decrease in efficiency.
Classification of Linear Linked Lists
- According to the link method: singly linked list, circular linked list, double linked list
- According to the implementation point of view: static linked list, dynamic linked list
The creation and simple traversal of linear linked list
Algorithmic thinking
Create a linked list and simply traverse and output the data in the linked list.
Algorithm implementation
# include <stdio.h>
# include <stdlib.h>
typedef struct Node
{
int data;//数据域
struct Node * pNext;//指针域 ,通过指针域 可以指下一个节点 “整体”,而不是一部分;指针指向的是和他本身数据类型一模一样的数据,从结构体的层面上说,也就是说单个指向整体,(这里这是通俗的说法,实施情况并非是这样的)下面用代码进行说明。
}NODE,*PNODE; //NODE == struct Node;PNODE ==struct Node *
PNODE create_list(void)//对于在链表,确定一个链表我们只需要找到“头指针”的地址就好,然后就可以确认链表,所以我们直接让他返回头指针的地址
{
int len;//存放有效节点的个数
int i;
int val; //用来临时存放用书输入的节点的的值
PNODE pHead = (PNODE)malloc(sizeof(NODE)); //请求系统分配一个NODE大小的空间
if (NULL == pHead)//如果指针指向为空,则动态内存分配失败,因为在一个链表中首节点和尾节点后面都是NULL,没有其他元素
{
printf("分配内存失败,程序终止");
exit(-1);
}
PNODE pTail = pHead;//声明一个尾指针,并进行初始化指向头节点
pTail->data = NULL;//把尾指针的数据域清空,毕竟和是个结点(清空的话更符合指针的的逻辑,但是不清空也没有问题)
printf("请您输入要生成链表节点的个数:len =");
scanf("%d",&len);
for (i=0;i < len;i++)
{
printf("请输入第%d个节点的值",i+1);
scanf("%d",&val);
PNODE pNew = (PNODE)malloc(sizeof(NODE));//创建新节点,使之指针都指向每一个节点(循环了len次)
if(NULL == pNew)//如果指针指向为空,则动态内存分配失败,pNew 的数据类型是PNODE类型,也就是指针类型,指针指向的就是地址,如果地址指向的 //的 地址为空,换句话说,相当于只有头指针,或者是只有尾指针,尾指针应该是不能的,因为一开始的链表是只有一个 //头指针的,所以说,如果pNew指向为空的话,说明,内存并没有进行分配,这个链表仍然是只有一个头节点的空链表。
{
printf("内存分配失败,程序终止运行!\n");
exit(-1);
}
pNew->data = val; //把有效数据存入pNEW
pTail->pNext = pNew; //把pNew 挂在pTail的后面(也就是pTail指针域指向,依次串起来)
pNew->pNext = NULL;//把pNew的指针域清空
pTail = pNew; //在把pNew赋值给pTai,这样就能循环,实现依次连接(而我们想的是只是把第一个节点挂在头节点上,后面的依次进行,即把第二个
//节点挂在第一个节点的指针域上),这个地方也是前面说的,要给pHead 一个“别名的原因”
/*
如果不是这样的话,代码是这样写的:
pNew->data = val;//一个临时的节点
pHead->pNext = pNew;//把pNew挂到pHead上
pNew->pNext=NULL; //这个临时的节点最末尾是空
注释掉的这行代码是有问题的,上面注释掉的代码的含义是分别把头节点后面的节点都挂在头节点上,
导致头节点后面的节点的指针域丢失(不存在指向),而我们想的是只是把第一个节点挂在头节点上,后面的依次进行,即把第二个
节点挂在第一个节点的指针域上,依次类推,很明显上面所注释掉的代码是实现不了这个功能的,pTail 在这里的做用就相当于一个中转站的作用,类似于两个数交换算法中的那个中间变量的作用,在一个链表中pHead 是头节点,这个在一个链表中是只有一个的,但是如果把这个节点所具备的属性赋值给另外的一个变量(pTail)这样的话,pTail 就相当于另外的一个头指针,然后当然也是可以循环。
*/
}
return pHead;//返回头节点的地址
}
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;//等价于 struct Node * pHead = NULL;把首节点的地址赋值给pHead(在一个链表中首节点和尾节点后面都是NULL,没有其他元素)
//PNODE 等价于struct Node *
pHead = create_list();
traverse_list(pHead);
return 0;
} Run the demo

Algorithm Summary
This is just a simple example, the algorithm used for inserting nodes is the tail insertion method, and the specific algorithm is as follows.
Implementation of linear linked list header insertion
Algorithmic thinking
Starting from an empty table, each time the data is read, a new node is generated, the read data is stored in the data field of the new node, and the new node is inserted after the header node of the current table.
Algorithm implementation
# include <stdio.h>
# include <stdlib.h>
typedef struct Node
{
int data;
struct Node * pNext;
}NODE,*PNODE;
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度\n");
int n;
int val;
scanf("%d",&n);
for (int i = n;i > 0;i--)
{
printf("请输入的第%d个数据",i);
PNODE p = (PNODE)malloc(sizeof(NODE));//建立新的结点p
if(NULL == p)
{
printf("内存分配失败,程序终止运行!\n");
exit(-1);
}
scanf("%d",&val);
p->data = val;
p->pNext = pHead->pNext;//将p结点插入到表头,这里把头节点的指针赋给了p结点
//此时,可以理解为已经把p节点和头节点连起来了,头指针指向,也就变成了
//p节点的指针指向了(此时的p节点相当于首节点了)
pHead->pNext = p;
}
return pHead;
}
int main(void)
{
PNODE pHead = NULL;
pHead = create_list();
traverse_list(pHead);
return 0;
} Run the demo

Algorithm Summary
The logical order of the singly linked list obtained by the head insertion method is opposite to the order of the input elements, so the head insertion method is also called the reverse order table building method. Why is it in reverse order? Because when you start building a table, the so-called head insertion method is to create a new node and link it behind the head node, that is to say, the latest inserted node is also far from the head node The closer it is! The key to this algorithm is p->data = val;p->pNext = pHead->pNext; pHead->pNext = p;. It may be clearer if it is represented by a diagram.

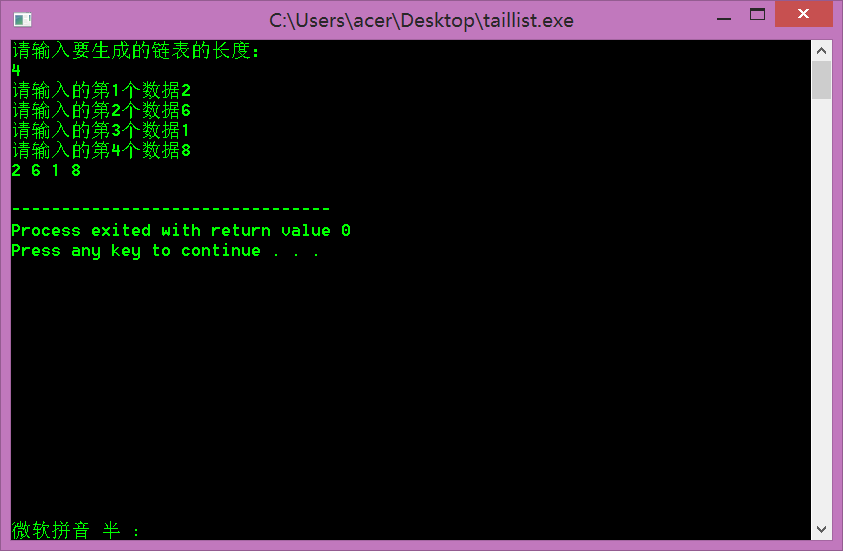
Implementation of linear linked list tail interpolation
Algorithmic thinking
Although the algorithm of establishing a linked list by the head insertion method is simple, the order of the nodes in the generated linked list is opposite to the input order. If you want the two to be in the same order, you can use the tail insertion method. For this purpose, you need to add a tail pointer r to point to the singly linked list. footer of the table.
Algorithm implementation
# include <stdio.h>
# include <stdlib.h>
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;//r 指针动态指向链表的当前表尾,以便于做尾插入,其初始值指向头节点,
//这里可以总结出一个很重要的知识点,如果都是指针类型的数据,“=”可以以理解为指向。
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val; //给新节点p的数据域赋值
r->pNext = p;//因为一开始尾指针r是指向头节点的, 这里又是尾指针指向s
// 所以,节点p已经链接在了头节点的后面了
p->pNext = NULL; //把新节点的指针域清空 ,先清空可以保证最后一个的节点的指针域为空
r = p; // r始终指向单链表的表尾,这样就实现了一个接一个的插入
}
return pHead;
}
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;
pHead = create_list();
traverse_list(pHead);
return 0;
}
Run the demo
Algorithm Summary
Through the study of the tail interpolation method, the understanding of the linked list has been further deepened. "=" can be understood as an assignment number or as a "pointer". The flexible use of the two can better understand the related content in the linked list.
Also, this tail difference method is actually the method used in the small example at the beginning of this article. The two can be compared and learned.
Find the i-th node (return the pointer of this node when found)
Find by serial number
Algorithmic thinking
In a singly linked list, since the storage location of each node is placed in the next field of its previous node, even if you know the serial number of the node being accessed, you cannot directly access the one-dimensional array according to the serial number as in the sequential list. The corresponding elements of , realize random access, and can only be triggered from the head pointer of the linked list, along the chain domain next, search down node by node until the i-th node is searched.
To find the i-th node in the singly linked list with the head node, you need to start from the head pointer L of the ** singly linked list, start from the head node (pHead->next) and scan along the linked list, and use the pointer p to point to the currently scanned node. , the initial value points to the head node, and j is used as a counter to accumulate the number of nodes currently scanned (the initial value is 0). When i==j, the node pointed to by the pointer p is the node to be found.
Code
# include <stdio.h>
# include <stdlib.h>
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//查找第i个节点
NODE * getID(PNODE pHead,int i)//找到后返还该节点的地址,只需要需要头节点和要找的节点的序号
{
int j; //计数,扫描的次数
NODE * p;
if(i<=0)
return 0;
p = pHead;
j = 0;
while ((p->pNext!=NULL)&&(j<i))
{
p = p->pNext;
j++;
}
if(i==j)//找到了第i个节点
return p;
else
return 0;
}
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;
int n;
NODE * flag;
pHead = create_list();
traverse_list(pHead);
printf("请输入你要查找的结点的序列:");
scanf("%d",&n);
flag = getID(pHead,n);
if(flag != 0)
printf("找到了!");
else
printf("没找到!") ;
return 0;
}
Run the demo
Find by value
Algorithmic thinking
Search by value means to search for a node whose value is equal to val in a singly linked list. During the search process, it starts from the head node pointed to by the head pointer of the singly linked list, and follows the chain to compare the value of the node to the given value one by one. The val is compared and the result is returned.
Code
# include <stdio.h>
# include <stdlib.h>
#include <cstdlib> //为了总是出现null未定义的错误提示
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//查找按照数值
NODE * getKey(PNODE pHead,int key)
{
NODE * p;
p = pHead->pNext;
while(p!=NULL)
{
if(p->data != key)
{
p = p->pNext;//这个地方要处理一下,要不然找不到的话就指向了系统的的别的地方了emmm
if(p->pNext == NULL)
{
printf("对不起,没要找到你要查询的节点的数据!");
return p;//这样的话,如果找不到的话就可以退出循环了,而不是一直去指。。。。造成指向了系统内存emmm
}
}
else
break;
}
printf("您找的%d找到了!",p->data) ;
return p;
}
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;
int val;
pHead = create_list();
traverse_list(pHead);
printf("请输入你要查找的结点的值:");
scanf("%d",&val);
getKey(pHead,val);
return 0;
}
Run the demo
Algorithm Summary
The two algorithms are similar. The first is to search by serial number and define a count variable j, which has two functions. The first function is to record the serial number of the node. The pointer appears to point somewhere else. The second lookup by value, of course, can also use the same method to limit the scope and prevent the pointer from pointing to another location. Or as written above, add a judgment, if it reaches the end of the table and is empty, it will exit the loop.
Find the length of the linked list
Algorithmic thinking
Calculate the length of the singly linked list with the head node by using the "number" method. That is, start from the "head" to "number" (p=L->next), and use the pointer p to point to each node in turn. And design the counter j, always drain the last node (p->next == NUll), so as to get the length of the singly linked list.
Algorithm implementation
# include <stdio.h>
# include <stdlib.h>
#include <cstdlib> //为了总是出现null未定义的错误提示
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的节点(输入0结束):\n");
int val=1;//赋一个初始值,防止 因为垃圾值而报错,下面都会被scanf函数给覆盖掉
PNODE r = pHead;
while(val != 0)
{
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//计算链表的长度
int ListLength(PNODE pHead)
{
NODE * p;
int j;//计数
p = pHead->pNext;
j = 0;
while(p!=NULL)
{
p = p->pNext;
j++;
}
return j;
}
int main(void)
{
PNODE pHead = NULL;
pHead = create_list();
int len = ListLength(pHead);
printf("%d",len);
return 0;
}
Run the demo
Algorithm Summary
In the sequence table, the length of the linear table is its attribute, which is determined when the array is defined. In the singly linked list, the entire linked list is represented by the "head pointer", and the length of the singly linked list is counted in the process of traversing from head to tail. , the resulting length value is not displayed and saved.
Find the maximum value in the singly linked list and implement the address inverse linked list
Algorithm idea (find the maximum value of a singly linked list)
This problem can be easily achieved by using two pointers. It is worth noting that the process of comparison should be mainly simulated, and the data fields of the two nodes pointed to by the pointers should be compared, and the address of the node with the larger data field should be returned. to find.
Algorithm implementation
# include <stdio.h>
# include <stdlib.h>
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//查找单链表中的最大值
NODE * SearchMAx(PNODE pHead)
{
NODE * p1;//定义两个指针,依次比较两次的数据域大小
NODE * p2;
p1 = pHead->pNext;
p2 = p1->pNext;
while(p2 != NULL)
{
if(p2->data > p1->data) //注意这里和上面的赋值的顺序
{
p1 = p2;//把p1定义为最大结点的指针
p2 = p2->pNext;//继续走链表
}
else
{
p2 = p2->pNext; //如果一直没有找到比p1大的数据,继续找
}
}
return p1;//把最大的节点的地址返回
}
int main(void)
{
PNODE pHead = NULL;
NODE * p;
pHead = create_list();
p = SearchMAx(pHead);
printf("链表中的最大值为%d",p->data);
return 0;
} Run the demo

Algorithm idea (reverse address permutation)
Algorithm idea: The inverted linked list is initially empty, the nodes in the table are "deleted" from the original linked list in turn, and then inserted into the headers of the inverted linked list one by one (that is, "head inserted" into the inverted linked list), making it an inverted linked list The "new" first node, and so on, until the original linked list is empty. Use the header method.
Algorithm implementation
void converse(LinkList *head)
{
LinkList *p,*q;
p=head->next;
head->next=NULL;
while(p)
{
/*向后挪动一个位置*/
q=p;
p=p->next;
/*头插*/
q->next=head->next;
head->next=q;
}
}
references
- Data Structure - Described in C Language (Second Edition) [Geng Guohua]
- Data Structure (C Language Version) [Yan Weimin, Wu Weimin]