
Last week's sensational Gitlab incident has finally settled. It is undeniable that the official public relations of Gitlab for this accident are very good. They announced the details of the incident in time and asked for help. This turned what was an accident caused by a mistake into a sincere one. Positive teaching material for facing problems and reflecting. This has been well received on the Internet.
Latest News:
As of 2017/02/02 02:14 Beijing time, GitLab.com has returned to normal. Lost 6 hours of database data (issues, merge requests, users, comments, snippets, etc.) Git/wiki repositories and self-hosted installations are not affected. According to GitLab's conclusions from the logs, 707 users lost data, 5,037 projects were lost, and less than 1% of the user base was affected by the incident.
Event recap:
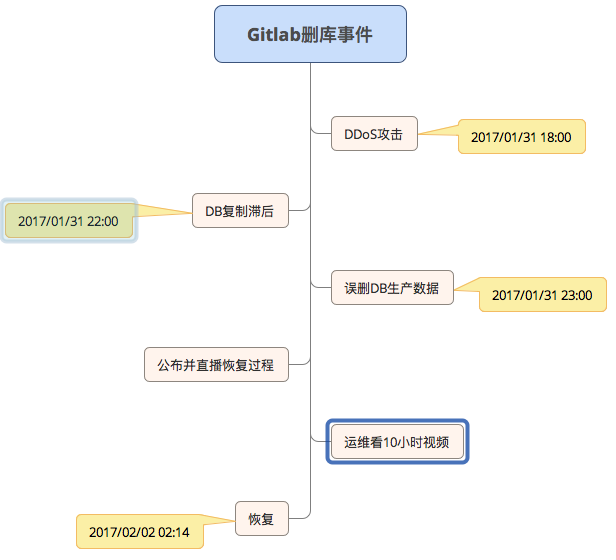
The reason is that at around 18:00 on 2017/01/31, Gitlab detected that the spammer attacked the database by creating fragments, making it unstable, so the operation and maintenance blocked the attacker's IP, and removed the user to send spam. After that, operation and maintenance A found that the db2.staging replication lag was 4GB of data in the production database (according to the CTO of the 2nd Quadrant – Simon Riggs in the later stage, it is normal for PostgreSQL to have a synchronization lag of 4GB), A began to try to repair db2, but the replication failed, A in Still the same after trying multiple options.
At around 23:00 on January 31, 2017, A decided to delete the db2 database directory and make it replicate again. Due to the long driving time at night, A mistakenly deleted the database of db1.cluster.gitlab.com (production library) instead of db2. Although realizing the problem after a second or two, the delete operation was terminated, but it was too late. About 300 GB or so of data is left with only about 4.5 GB.
Afterwards, although there is a so-called five-fold backup mechanism (regular backup (once in 24 hours), automatic synchronization, LVM snapshot (once in 24 hours), Azure backup (only enabled for NFS, invalid for database), S3 backup), there is no one Reliably run or set up, only to end up with an LVM-based backup (last 6 hours ago), restoring a backup 6 hours ago. Gitlab live-streamed the recovery process during the recovery.
Please refer to the documentation for details
reference meaning
1. Be proactive and seek help
What shocked us about this incident was that Gitlab took the initiative to announce the details of the incident, not only submitted a detailed accident report to googleDoc, but also actively sought help on the Internet. This sincerity is truly admirable. If it is a general technical team who hides problems from the outside world, and then solves them by themselves, the time is eventually delayed, users still don’t recognize you, and you can’t express your own hardships. On the contrary, Gitlab took the initiative to announce it, which not only won the help of various technical organizations, but also gained the understanding and support of users, and at the same time, there was less speculation and rumors on the Internet.
In addition to the positive public event details, GitLab's failure review also stated that it is necessary to carry out Ask 5 Whys for this accident. Later, during the live broadcast, the official also took the initiative to explain that operation and maintenance A would not be fired, but would punish him for watching a video called "10 hours of nyancat" ( http://www.nyan.cat/ Haha, very ugly). This shows that the entire team's attitude towards this accident is to work together to solve the problem, and then review the process, not to blame individuals. This attitude is also worthy of admiration. When there is a problem, first of all, it is not to be held accountable, but to solve the problem, and then find the underlying problem, so as to effectively avoid making the same mistake next time.
2. Prevent human flesh operation and maintenance
After the accident, some people suggested not to use the rm command, but to use the mv command. In fact, this can only solve the temporary problem. Can you guarantee that there will be no problems with other commands? In addition, some people suggest to establish a checklist process, check the process every time it is executed, and there are documents to indicate that some low-level mistakes will not be made. If each command is checked, the work will not be more complicated.
In addition, there are some suggestions for two-person operation, adding a permission system, etc. I think that for a standardized process, some necessary prompts and specifications can be added, but the operation and maintenance should be automated, and machines should be used instead of labor, instead of going backwards to adopt more A lot of manual work to avoid mistakes.
3. Highly available distributed system
During the recovery of this accident, it was found that 5 backup systems were basically useless, which eventually resulted in the loss of 6 hours of data. Based on the shortcomings of the backup system, some operation and maintenance students suggested the following:
1. Review the backup plan of all data, the frequency of backup, where to store the backup data, and how long to keep it.
2. For services such as image backup that comes with the cloud service, confirm whether it is opened and set correctly
3. For self-built backup solutions, confirm
4. Regularly do disaster recovery drills to check whether recovery from backups can be done correctly, and how much time and resources this process requires.
In terms of backup procedures and specifications, these recommendations are pertinent. From another point of view, even if your backup system has done this, and there is zero operator error, the problem of lost data will still occur , why na.
The following is the text taken from the left ear mouse " I thought of deleting the database by mistake from Gitlab ".
Backups are usually periodic, so if your data is lost, restoring data from your most recent backup will be lost from the time of the backup to the time of the downtime.
The backed up data may have version incompatibility issues. For example, during the last time you backed up data until the failure, you made a change to the data scheme, or you made some adjustments to the data, then the data you backed up will be incompatible with your online program. condition.
Some companies or banks have data centers for disaster recovery, but the data centers for disaster recovery have not been live for a day. When the real disaster comes and you need to live, you will find that various problems make you unable to live. You can read this report a few years ago and get a good feel for "Last Analysis of Ningxia Bank's System Paralysis in July" by Taking History as a Mirror.
Therefore, when disaster strikes, you will find that your well-designed "backup system" or "disaster recovery system" can work normally, but it will also lead to data loss, and the backup system that may not be used for a long time is difficult to restore (For example, incompatible versions of applications, tools, data, etc.).
Therefore, if you want to make your backup system available at any time, then you need to make it live at any time, and a multi-node system that is live at any time is basically a distributed high-availability system. Because there are many reasons for data loss, such as power failure, disk damage, virus, etc., and those processes, rules, human flesh checks, permission systems, checklists, etc. are just for people not to misuse them, and they don't work. This At times, you have to use better technology to design a highly available system! There is no other way.
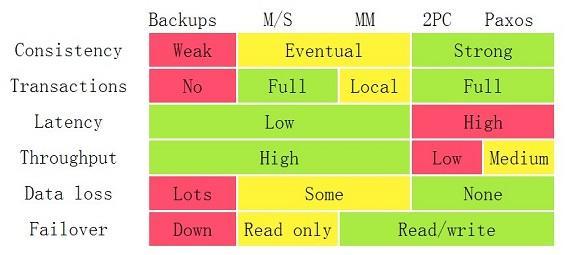
The above are the advantages and disadvantages of each architecture. We can see that under the Backups, Master/Slave, and Master/Master architectures, there will be losses in Data, but 2PC and Paxos will not.
4. Beware of driving at night
It is dark and windy at night, and if you drive for a long time at night, there will inevitably be a car accident scene. The operation and maintenance A of this accident, working late at night, must have something to do with fatigued driving.
We do not comment on whether the 8-hour work system is reasonable, but for mental workers, violating the law of brain use or even putting them in a state of overload fatigue will significantly reduce the energy conversion efficiency of the brain. highest place. It is hoped that policymakers will be aware of this problem and not just work overtime to catch up. This kind of harm has been more and more recognized by practitioners.
For more information, please scan the code and follow the public account:
