background
Recently a student came to me and described the following scene to me:
There are many reports on their company's internal management system, and the report data is displayed in pagination, and the browsing speed is OK. However, when exporting data with a slightly larger time window, each report is extremely slow, and sometimes a heap overflow occurs when multiple people export together.
He knew that it was a heap overflow caused by all the data being loaded into jvm memory. So only the time window can be limited. To avoid heap overflow caused by too large exported data. Finally, I set a limit as follows: the time window of the exported data cannot exceed 1 month.
Although the problem was solved, the operation lady was unhappy. She ran over and said to the junior, I want to export the data for one year, should I export it 12 times and then merge it manually. The student thought to himself, this is also. The system is for people and cannot change its nature in order to solve a problem.
So the question he wanted to ask me was: Is there any way to fundamentally solve this problem.
The so-called fundamental solution to this problem, he proposed to achieve two conditions
- Faster export speed
- Multiple people can download large data sets in parallel
After I listened to his question, I thought that his question must have been encountered by many other children's shoes when exporting data from web pages. In order to maintain the stability of the system, many people generally limit the number of exported data or the time window when exporting data. But the demand side definitely prefers to export datasets with arbitrary conditions at one time.
Can you have both fish and bear's paw?
The answer is yes.
I firmly told my younger brother that I made a download center program about 7 years ago, and the export of 20w data should take about 4 seconds. . . Support multiple people to export online at the same time. . .
The younger brother looked a little excited after hearing this, but his brows wrinkled again, and said, how can it be so fast, 20w data in 4 seconds?
To give him an example, I dug up the code from 7 years ago. . . It took a night to extract the core code, strip it clean, and make an example of a download center
Demonstration of ultra-fast download solution
Let’s not talk about the technology first, let’s look at the effect first, ( the complete case code is provided at the end of the article )
The database is mysql (in theory, this solution supports any structured database), and a test table is prepared t_person. The table structure is as follows:
CREATE TABLE `t_person` (
`id` bigint(20) NOT NULL auto_increment,
`name` varchar(20) default NULL,
`age` int(11) default NULL,
`address` varchar(50) default NULL,
`mobile` varchar(20) default NULL,
`email` varchar(50) default NULL,
`company` varchar(50) default NULL,
`title` varchar(50) default NULL,
`create_time` datetime default NULL,
PRIMARY KEY (`id`)
);
There are 9 fields in total. Let's create test data first.
The case code provides a simple page, click the following button to create 5w pieces of test data at one time:
Here I clicked 4 times in a row, and soon 20w pieces of data were generated. Here, in order to show the general appearance of the data, I jumped directly to the last page.

Then click 下载大容量文件it, click the Execute button to start downloading t_personall the data in this table

After clicking the execute button, click the refresh button below, you can see an asynchronous download record, the status is P, indicating the pendingstatus, keep refreshing the refresh button, after about a few seconds, this record will become Sthe status, indicatingSuccess
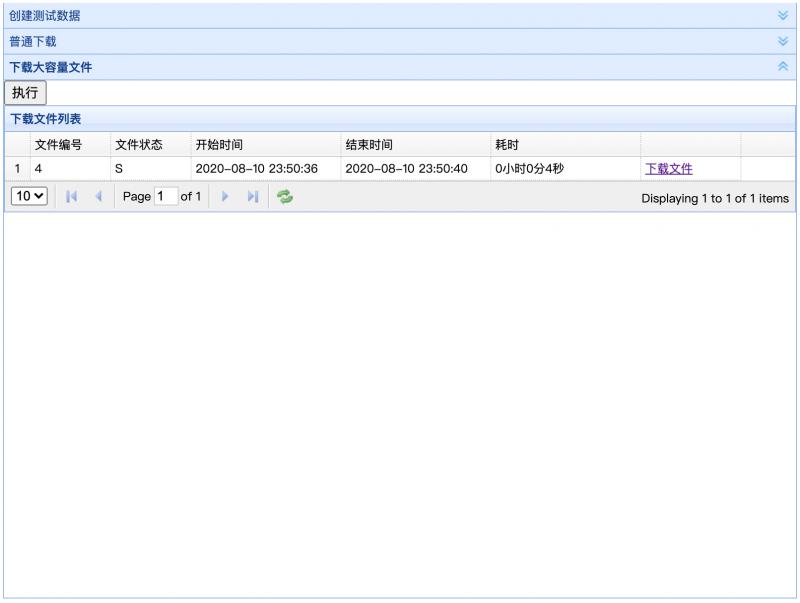
Then you can download it locally, the file size is about 31M

Seeing this, many children's shoes are going to be confused. This download is csv? csv is actually a text file, and opening it with excel will lose formatting and precision. This doesn't solve the problem, we need excel format! !
In fact, if you have a little knowledge of excel skills, you can use the function of importing data in excel, data->import data, follow the prompts step by step, just select commas to separate them, the key columns can define the format, and the data can be completed in 10 seconds import
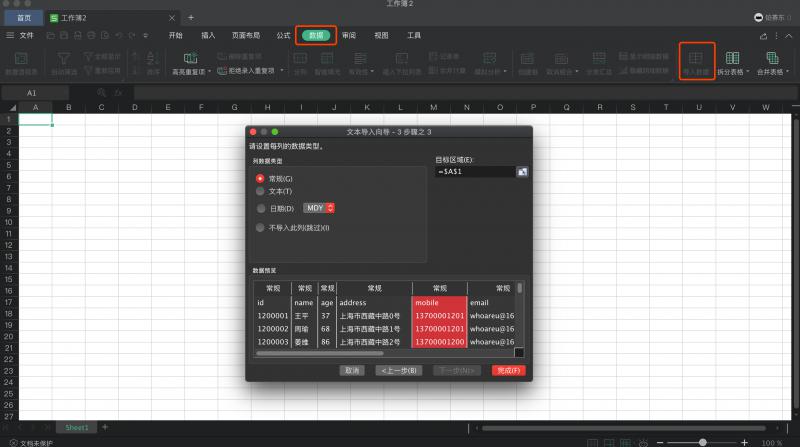
You just need to tell Miss Operations to complete the import of excel according to this step. And the downloaded files can also be downloaded repeatedly.
Does it essentially solve the problem of downloading large datasets?
Principle and core code
When my younger brother heard this, he was very excited to say that this solution could solve my pain point. Tell me why.
In fact, the core of this scheme is very simple, it only comes from a knowledge point, JdbcTemplateand this interface is used:
@Override
public void query(String sql, @Nullable Object[] args, RowCallbackHandler rch) throws DataAccessException {
query(sql, newArgPreparedStatementSetter(args), rch);
}
sql is select * from t_person, RowCallbackHandlerthis callback interface refers to the callback function to be executed after each piece of data is traversed. Now posting my own RowCallbackHandlerimplementation
private class CsvRowCallbackHandler implements RowCallbackHandler{
private PrintWriter pw;
public CsvRowCallbackHandler(PrintWriter pw){
this.pw = pw;
}
public void processRow(ResultSet rs) throws SQLException {
if (rs.isFirst()){
rs.setFetchSize(500);
for (int i = 0; i < rs.getMetaData().getColumnCount(); i++){
if (i == rs.getMetaData().getColumnCount() - 1){
this.writeToFile(pw, rs.getMetaData().getColumnName(i+1), true);
}else{
this.writeToFile(pw, rs.getMetaData().getColumnName(i+1), false);
}
}
}else{
for (int i = 0; i < rs.getMetaData().getColumnCount(); i++){
if (i == rs.getMetaData().getColumnCount() - 1){
this.writeToFile(pw, rs.getObject(i+1), true);
}else{
this.writeToFile(pw, rs.getObject(i+1), false);
}
}
}
pw.println();
}
private void writeToFile(PrintWriter pw, Object valueObj, boolean isLineEnd){
...
}
}
What this CsvRowCallbackHandlerdoes is to take out 500 records from the database each time, and then write them into the local file on the server. In this way, no matter whether your SQL query is 20w or 100w, the memory theoretically only occupies 500 data storage space. . When the file is finished, all we have to do is to download the generated file from the server to the local.
Because the capacity of only 500 pieces of data is constantly refreshed in the memory, even in a multi-threaded download environment. The memory also won't overflow because of this. In this way, the scenario of multiple downloads is perfectly solved.
Of course, too many parallel downloads will not cause memory overflow, but will consume a lot of IO resources. To this end, we still need to control the number of multi-threaded parallelism, and we can use the thread pool to submit jobs
ExecutorService threadPool = Executors.newFixedThreadPool(5);
threadPool.submit(new Thread(){
@Override
public void run() {
下载大数据集代码
}
}
Finally, I tested the download of 50w person data, which took about 9 seconds, and 100w person data, which took 19 seconds. This download efficiency should be able to meet the report export needs of most companies.
finally
After the student got my sample code, after a week of revisions, a new version of the page export was launched. All reports were submitted asynchronously, and everyone went to the download center to view and download the files. It perfectly solved the previous two pain points.
But in the end, the younger brother still has a question, why can't excel be generated directly. That is to say RowCallbackHandler, do you continue to write data to excel in ?
My answer is:
1. Text file stream writing is faster
2. The excel file format doesn't seem to support continuous stream writing. Anyway, I haven't tried it successfully.
I have sorted out the cases that have been stripped out and provided them to you free of charge, hoping to help children’s shoes who encounter similar scenarios.
Follow the author
Follow the official account **"Yuanren Tribe"** and reply " Export Case " to get the above complete case code, which can be run directly. Enter http://127.0.0.1:8080 on the page to open the simulation of the case in the text page.
