The author of this article: Wang Yu, engineer of Baidu Infrastructure Department
The master-slave replication of Redis has undergone many evolutions. This article will start from the most basic principles and implementations, and proceed layer by layer, gradually presenting the evolution history of Redis master-slave replication. You will understand the principle of Redis master-slave replication, and what problems are solved by each improved version, and finally see the whole picture of Redis 7.0 master-slave replication principle.
What is master-slave replication?
In the context of databases, replication is the copying of data from one database to another. Master-slave replication is to divide the database into a master node and a slave node. The master node continuously copies data to the slave nodes to ensure that the same data is stored in the master and slave nodes. With master-slave replication, data can have multiple copies, which brings a variety of benefits: First, it improves the request processing capability of the database system. The read traffic that a single node can support is limited, and multiple nodes are deployed to form a master-slave relationship. Master-slave replication is used to keep the data of the master and slave nodes consistent, so that the master and slave nodes can provide services together. Second, improve the availability of the entire system. Because the slave node has a copy of the master node's data, when the master node goes down, one of the slave nodes can be promoted to the master node immediately and continue to provide services.
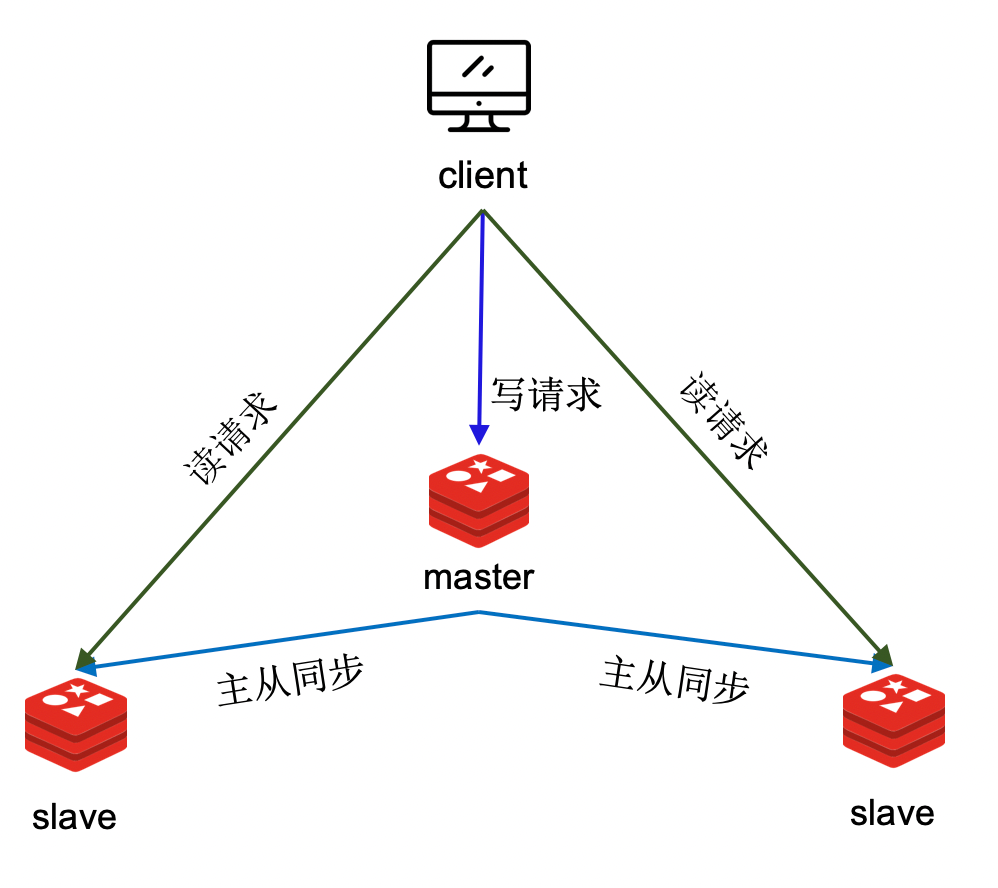
Redis master-slave replication principle
To achieve master-slave replication, the intuitive idea is to generate a snapshot of the data of the master node and send it to the slave node, and use this as a benchmark, and then send the incremental data after the snapshot time to the slave node, so that the master-slave data can be guaranteed. consistent. Generally speaking, master-slave replication generally includes two stages of full data synchronization and incremental synchronization.
In the master-slave replication implementation of Redis, there are two similar phases: full data synchronization and command propagation. Full data synchronization: The master node generates a snapshot of the full amount of data, that is, the RDB file, and sends the snapshot to the slave node. And from the moment when the snapshot is generated, the newly received write command is recorded. When the snapshot is sent, the accumulated write commands are sent to the slave node, and the slave node executes these write commands. At this point, the benchmark has been established, and the data between the master and slave nodes is generally consistent. Command propagation: After the full data synchronization is completed, the master node continuously sends the executed write commands to the slave nodes, and the slave nodes execute these commands to ensure that the data in the master and slave nodes have the same changes, thus ensuring that the master and slave data are consistent.
The following figure shows the entire process of Redis master-slave replication:
After the master-slave relationship is established, the slave node sends a SYNC command to the master node to request master-slave synchronization. After the master node receives the SYNC command, it executes fork to create a child process. In the child process, all data is stored in the RDB (Redis Database) file according to a specific code, which generates a snapshot of the database. The master node sends this snapshot to the slave node, which receives and loads the snapshot. The master node then sends the backlogged write commands during snapshot generation and snapshot sending to the slave node, and the slave node receives these commands and executes them. After the command is executed, the data in the slave node will also have the same change. After that, the master node continuously synchronizes the newly executed write commands to the slave node, and the slave node executes the propagated commands. In this way, the master-slave data remains consistent. It should be noted that there is a delay in command propagation, so at any time, the data between the master and slave nodes cannot be guaranteed to be completely consistent. The above is the basic principle of Redis master-slave replication. It is very simple and easy to understand. Redis initially adopted this scheme, but there are some problems with this scheme: fork takes too long, and when the main process is blocked from executing fork, a large amount of memory needs to be copied Page table, this is a time-consuming operation, especially when the memory usage is large. The students in the group have done tests. When the memory occupies 10GB, the fork needs to consume more than 100 milliseconds. When fork, the main process is blocked for more than 100 milliseconds, which is too long for Redis. In addition, after fork, if there are a lot of writes in the main library, due to the copy-on-write mechanism, it will consume a lot of memory and increase the response time. The network flash between the master and the slave will trigger full synchronization. If the network between the master and the slave fails and the connection is disconnected unexpectedly, the master node cannot continue to propagate commands to the slave node. After the network is restored, after the slave node reconnects to the master node, the master node can no longer continue to propagate the newly received commands, because the slave node has missed some commands. At this point, the slave node needs to start all over again and perform the entire synchronization process again, which requires a high cost. Network outages are a common occurrence. During the outage, only a relatively small amount of data may be written to the master node, but because of this small amount of data, the slave node needs to perform a costly full synchronization. This approach is very inefficient, how to solve this problem? The next section, Redis Partial Resync, will give you the answer.
Redis partial resync
After the network is disconnected for a short time, the slave node needs to be resynchronized, which is a waste of resources and not environmentally friendly. Why does the slave node need to be resynchronized? Because some commands are not synchronized to the slave node during the master-slave disconnection. If you ignore these commands and continue to propagate subsequent commands, it will cause data confusion, because the lost commands cannot be ignored. Why not save those commands? In this way, when the slave node is reconnected, the commands during the disconnection period can be supplemented to it, so that there is no need to re-synchronize fully. Partial synchronization was introduced after Redis 2.8. It maintains a replication backlog buffer in the master node, and commands are propagated to the slave nodes on the one hand and recorded in this buffer on the other hand. It is not necessary to save all the commands, a circular buffer is used in Redis, so that only the most recent commands can be kept.

The command is saved, but after the slave node is reconnected, where should the master node start sending commands to the slave node? If a number can be assigned to all commands, the slave node only needs to tell the master node the number of the last command it received, and the master node will know where to send the command from. In the Redis implementation, the bytes are numbered, and this number is called the replication offset in the context of Redis.
With partial synchronization, the master-slave replication process becomes as follows:

When master-slave replication, the SYNC command is no longer used, but PSYNC, which means Partial SYNC, is partially synchronized. The syntax of PSYNC is as follows: PSYNC <master id> <replication offset>
The two parameters in the command, one is the number of the primary node, and the other is the replication offset. Each Redis node has a 40-byte number, and the number carried in the PSYNC command is the number of the master node that is expected to synchronize. The replication offset indicates where the current slave wants to start partial synchronization. If it is the first time to perform master-slave replication, it is natural that you do not know the number of the master node, and the replication offset is meaningless. At this time, use PSYNC ? -1 to perform full synchronization. In addition, if the replication offset specified by the slave node is not within the scope of the replication backlog buffer of the master node, the partial synchronization will fail and the full synchronization will be turned. With partial synchronization, full synchronization can be avoided after the network is disconnected. But because the master can only keep some recent commands, how much depends on the size of the replication backlog buffer. If the slave node is disconnected for too long, or if the master node executes enough new write commands during the disconnection period, the missed commands cannot all be saved to the replication backlog buffer. Increasing the copy backlog buffer can avoid as many full synchronizations as possible, but it also causes additional memory consumption. Partial synchronization consumes part of the memory to save the most recently executed write commands and avoids full synchronization after a flash. This is a very intuitive and easy to imagine solution. This solution is very good, are there any other problems? Consider the following questions: What if the slave node reboots? Partial synchronization depends on the number and replication offset of the master node. The slave node will obtain the number of the master node during the initial synchronization, and continuously adjust the replication offset in subsequent synchronizations. This information is stored in memory. When the slave node restarts unexpectedly, although there are RDB or AOF files locally, a full synchronization is still required. But in fact, it is completely possible to load local data and perform partial synchronization. What if the master-slave is switched? If the master node unexpectedly goes down, the peripheral monitoring component performs a master-slave switchover. At this time, the master node corresponding to other slave nodes has changed, and the master node number recorded in the slave node cannot match the new master node. At this time, a full synchronization will be performed. But in fact, the synchronization progress of all slave nodes should be similar before the master-slave switchover, and the newly promoted slave node should contain the most complete data. After the master-slave switch, all slave nodes should perform a full synchronization, which is really unreasonable.
以上问题如何解决,请继续往后看。
Homologous Incremental Synchronization
After the slave node restarts, the original master node number and replication offset are lost, which leads to the need for full synchronization after restart. After the master-slave switch, the information of the master node has changed, causing the slave nodes to need to be fully synchronized. This is also easy to solve. As long as you can confirm that the data on the new master node is copied from the original master node, you can continue from the new master node. make a copy. After Redis 4.0, PSYNC has been improved, and a solution of homologous incremental replication is proposed, which solves the two problems mentioned above. After the slave node restarts, it needs to fully synchronize with the master node. This is essentially because the slave node loses the master node's number information. After Redis 4.0, the master node's number information is written to the RDB for persistent storage. After switching to the master, the slave node needs to be fully synchronized with the new master node. The essential reason is that the new master node does not recognize the number of the original master node. The slave node sends PSYNC <original master node number> <copy offset> to the new master node, if the new master node can recognize the <original master node number> and understand that its data is copied from this node. Then the new master node should know that it is in the same family as the slave node and should accept partial synchronization. How to identify it, just let the slave node record the number of its previous master node when it switches to the master node. After Redis 4.0, after the master-slave switch, the new master node will record the previous master node, observe the result of info replication, you can see the master_replid and master_replid2 two numbers, the former is the number of the current master node, the latter is The number of the previous master node:
127.0.0.1:6379> slaveof no one
OK
127.0.0.1:6379> info replication
# Replication
role:master
...
master\_replid:b34aff08d983991b3feb4567a2ac0308984a892a
master\_replid2:a3f2428d31e096a99d87affa6cc787cceb6128a2
master\_repl\_offset:38599
second\_repl\_offset:38600
...
repl\_backlog\_histlen:5180The current value in Redis retains two master node numbers, but a linked list can be implemented to record the number information of the past master nodes, so that it can be traced further. In this way, if a slave node is disconnected and performs multiple master-slave switchovers, after the slave node is reconnected, it can still recognize that their data is of the same origin. But Redis did not do this because it was not necessary, because even if the data was of the same origin, the data stored in the replication backlog buffer was limited. After multiple master-slave switchovers, the commands saved in the replication backlog buffer could no longer be replicated. Satisfaction partially synced. With same-origin incremental replication, after the master node switches, other slave nodes can continue incremental synchronization based on the new master node. At this point, master-slave replication does not seem to have much problem. But the guys working on Redis are always thinking about whether they can do more optimization. Below I will describe some optimization strategies for Redis master-slave replication.
Diskless full sync and diskless loading
To perform full replication, Redis needs to generate a snapshot of the current database. The specific method is to execute fork to create a sub-process. The sub-process traverses all the data and writes it to the RDB file after encoding. After the RDB is generated, in the master process, this file is read and sent to the slave nodes. Reading and writing RDB files on disk is resource-intensive, and executing it in the main process will inevitably lead to a longer response time for Redis. Therefore, an optimization solution is to directly send the data to the slave node after dumping, without writing the data to the RDB first. This strategy of diskless full synchronization and diskless loading is implemented in Redis 6.0. The use of diskless full synchronization avoids the operation of disks, but it also has disadvantages. In general, sending data directly using the network in the child process is slower than generating an RDB in the child process, which means that the child process needs to survive for a relatively long time. The longer the child process exists, the greater the impact of copy-on-write, which in turn consumes more memory. During full replication, the slave node generally first receives the RDB and stores it locally, and then loads the RDB after receiving it. Similarly, the slave node can also directly load the data sent by the master node, avoiding storing it in a local RDB file and then loading it from disk.
Shared master-slave replication buffer
From the perspective of the master node, the slave node is a client. After the slave node sends the PSYNC command, the master node will complete full synchronization with them, and continuously synchronize the write command to the slave node. A send buffer exists on each client connection in Redis. After the master node executes the write command, it will write the command content into the send buffer of each connection. The send buffer stores the command to be propagated, which means that the contents of multiple send buffers are actually the same. Moreover, these commands are also stored in the copy backlog buffer. This causes a lot of memory waste, especially when there are many slave nodes.

In Redis 7.0, our teammates proposed and implemented a shared master-slave replication buffer solution to solve this problem. This scheme allows the sending buffer to be shared with the replication backlog buffer, which avoids data duplication and can effectively save memory.
Summarize
This article reviews and summarizes the evolution of Redis master-slave replication, and explains the problems solved by each evolution. Finally, some strategies for optimizing Redis master-slave replication are described.
The following is a summary of the full text:
From a macro perspective, the master-slave replication of Redis is divided into two stages: full synchronization and command propagation. The master node first sends a snapshot to the slave node, and then continuously propagates commands to the slave node to ensure the consistency of the master and slave data. The master-slave replication before Redis 2.8 had the problem of full synchronization after a flash. Redis 2.8 introduced the replication backlog buffer to solve this problem. In Redis 4.0, the same-origin incremental replication strategy was proposed, which solved the problem of full synchronization of slave nodes after master-slave switchover. So far, the master-slave replication of Redis has been relatively complete as a whole. In Redis 6.0, in order to further optimize the performance of master-slave replication, diskless synchronization and loading are proposed to avoid reading and writing disks during full synchronization and improve the speed of master-slave synchronization. In Redis 7.0 rc1, the strategy of sharing master-slave replication buffers is adopted, which reduces the memory overhead caused by master-slave replication. I hope this article can help you review the principle of Redis master-slave replication and build a deeper impression on it.