content
1. Tell me about your understanding of Kafka
2. Do you know the message queue model? How does Kafka support these two models?
3. Can you talk about the principle of Kafka communication process?
4. So how do you choose a partition when sending a message?
5. Why is partitioning needed? What are the benefits?
6. Explain in detail about consumer groups and consumer rebalancing?
The following describes the rebalancing process.
7. Specifically talk about the partition allocation strategy?
8. How to ensure message reliability?
9. Let’s talk about the copy and its synchronization principle, right?
10. Why did the new version of Kafka abandon Zookeeper?
3. Batch processing and compression
1. Tell me about your understanding of Kafka
Kafka is a streaming data processing platform. It has the capabilities of a message system and real-time streaming data processing and analysis capabilities , but we are more inclined to use it as a message queue system .
If we say that it is easy to understand, it can be roughly divided into three layers:
The first layer is Zookeeper , which is equivalent to the registration center . It is responsible for the management of kafka cluster metadata and the coordination of the cluster. When each kafka server starts, it connects to Zookeeper and registers itself in Zookeeper .
The second layer is the core layer of kafka , which contains many basic concepts of kafka:
Record : represents the message
Topic: Topic, messages will be organized by a topic, which can be understood as a classification of messages
Producer: Producer, responsible for sending messages
Consumer: Consumer, responsible for consuming messages
Broker: kafka server
Partition: Partition, the topic will be composed of multiple partitions . Usually, the messages of each partition are read in order. Different partitions cannot guarantee the order. Partition is the data sharding mechanism we often say, the main purpose is to In order to improve the scalability of the system, through partitioning, the reading and writing of messages can be load balanced to multiple different nodes
Leader/Follower: A replica of the partition. In order to ensure high availability, the partition will have some replicas. Each partition will have a leader master replica responsible for reading and writing data. Follower slave replicas are only responsible for maintaining data synchronization with the leader replica, and do not provide any external services.
Offset: offset, each message in the partition will have an increasing sequence number according to the time sequence, this sequence number is the offset offset
Consumer group: a consumer group, composed of multiple consumers, only one consumer in a group consumes messages from one partition
Coordinator: Coordinator, mainly to allocate partitions for consumer groups and rebalance Rebalance operations
Controller: The controller is actually just a broker. It is used to coordinate and manage the entire Kafka cluster. It will be responsible for partition leader election, topic management, etc. The first person to create a temporary node/controller in Zookeeper will become the controller
The third layer is the storage layer , which is used to save the core data of kafka, and they will be eventually written to the disk in the form of logs.
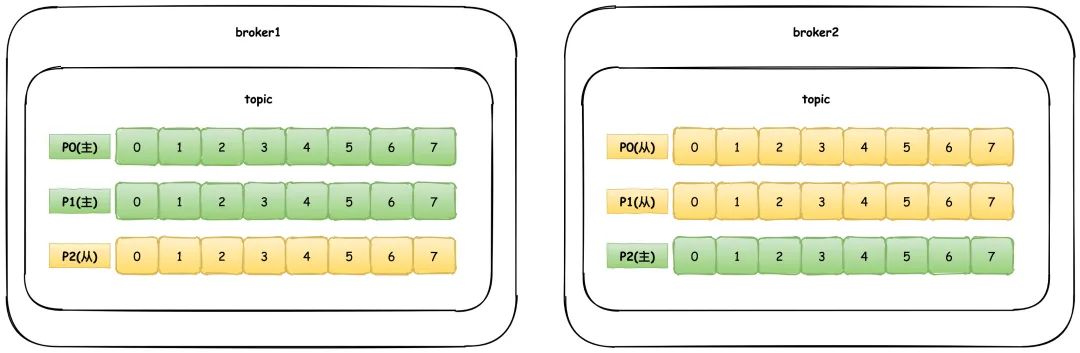
2. Do you know the message queue model? How does Kafka support these two models?
Two models are supported for traditional message queuing systems:
1. Point-to-point: that is, messages can only be consumed by one consumer, and messages are deleted after consumption
2. Publish and subscribe: equivalent to broadcast mode, messages can be consumed by all consumers
As mentioned above, Kafka actually supports both models through the Consumer Group .
If all consumers belong to a group, and messages can only be consumed by one consumer in the same group, that is the point-to-point mode.
If each consumer is a separate Group, then it is a publish-subscribe model.
In fact, Kafka supports both models flexibly by grouping consumers.
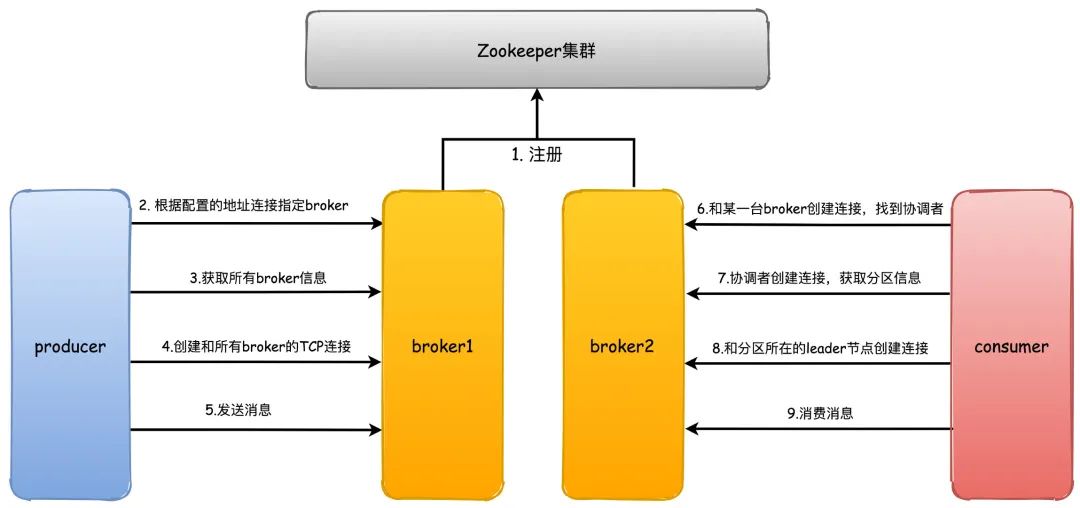
3. Can you talk about the principle of Kafka communication process?
1. First, when the kafka broker starts, it will register its own ID (create a temporary node) with Zookeeper. This ID can be configured or automatically generated. At the same time, it will subscribe to the brokers/ids path of Zookeeper. When a new broker joins or exits , you can get all the current broker information
2. When the producer starts, it will specify bootstrap.servers. Through the specified broker address , Kafka will create a TCP connection with these brokers (usually we do not need to configure all the broker server addresses ddfr90zsssx--, otherwise kafka will communicate with all the configured brokers) both establish a TCP connection)
3. After connecting to any broker, send a request to obtain metadata information (including which topics, which partitions the topics have, which copies of the partitions, and the leader copy of the partitions, etc.)
4. Then a TCP connection to all brokers will be created
5. After that is the process of sending a message
6. Like the producer, the consumer will also specify the bootstrap.servers property, then select a broker to create a TCP connection, and send a request to find the broker where the coordinator is located.
7. Then create a TCP connection with the coordinator broker to obtain metadata
8. According to the broker node where the partition leader node is located, create connections with these brokers respectively
9. Finally start consuming messages
4. So how do you choose a partition when sending a message?
There are mainly two ways:
1. Polling, sending messages to different partitions in sequence
2. Random, randomly sent to a partition
If the message specifies a key, it will be hashed according to the key of the message , and then the number of partition partitions will be modulo to determine which partition it falls on. Therefore, for messages with the same key , they will always be sent to the same partition . We often talk about the order of message partitions.
A very common scenario is that we want the order and payment messages to be in order, so that the order ID is used as the key to send the message to achieve the purpose of partition order.
If no key is specified, the default round-robin load balancing strategy will be implemented, for example, the first message falls on P0, the second message falls on P1, and then the third message falls on P1.
In addition, for some specific business scenarios and requirements, you can also achieve the effect of custom partitioning by implementing the Partitioner interface and rewriting the configure and partition methods.
5. Why is partitioning needed? What are the benefits?
This problem is very simple. If there is no partition, we can only save the message and write data to one node. In this case, no matter how good the performance of this server node is, it will not be able to support it in the end.
In fact, distributed systems all face this problem. Either data is divided after receiving the message, or it is divided in advance. Kafka chooses the former, and the data can be evenly distributed to different nodes through partitioning.
Partitioning brings load balancing and horizontal scaling capabilities.
When sending a message, it can fall on different Kafka server nodes according to the number of partitions, which improves the performance of concurrent message writing. When consuming messages, it is bound to consumers, and messages can be consumed from different partitions of different nodes, which improves the The ability to read messages.
The other is that the partition introduces replicas, and redundant replicas ensure the high availability and durability of Kafka .
6. Explain in detail about consumer groups and consumer rebalancing?
Consumer groups in Kafka subscribe to topic messages. Generally speaking, the number of consumers should be consistent with the number of all topic partitions (for example, one topic can be subscribed to multiple topics).
When the number of consumers is less than the number of partitions, there must be one consumer consuming messages from multiple partitions.
When the number of consumers exceeds the number of partitions, there must be consumers who have no partitions to consume.
Therefore, on the one hand, the advantages of consumer groups have been mentioned above, which can support multiple message models, and on the other hand, support horizontal expansion and expansion according to the consumption relationship between consumers and partitions.

When we know how consumers consume partitions, there will obviously be a problem. How are the partitions consumed by consumers allocated, and what if there are consumers who join first?
The rebalancing process of the old version is mainly triggered by the ZK listener, and each consumer client executes the partition allocation algorithm by itself.
The new version is completed by the coordinator. Every time a new consumer joins, a request is sent to the coordinator to obtain the partition allocation. The algorithm logic of this partition allocation is completed by the coordinator.
Rebalancing Rebalance refers to the situation where new consumers join. For example, at the beginning, we only have consumer A consuming messages. After a period of time, consumers B and C have joined. At this time, the partition needs to be redistributed. This is the rebalancing process. Balancing can also be called rebalancing, but the process of rebalancing is very similar to STW during our GC, which will cause the entire consumer group to stop working, and messages cannot be sent during the rebalancing.
In addition, rebalancing is not the only case, because there is a binding relationship between consumers and the total number of partitions. As mentioned above, the number of consumers should preferably be the same as the total number of partitions for all topics.
As long as any one of the number of consumers, the number of topics (such as the topic used for regular subscription), and the number of partitions changes, rebalancing will be triggered .
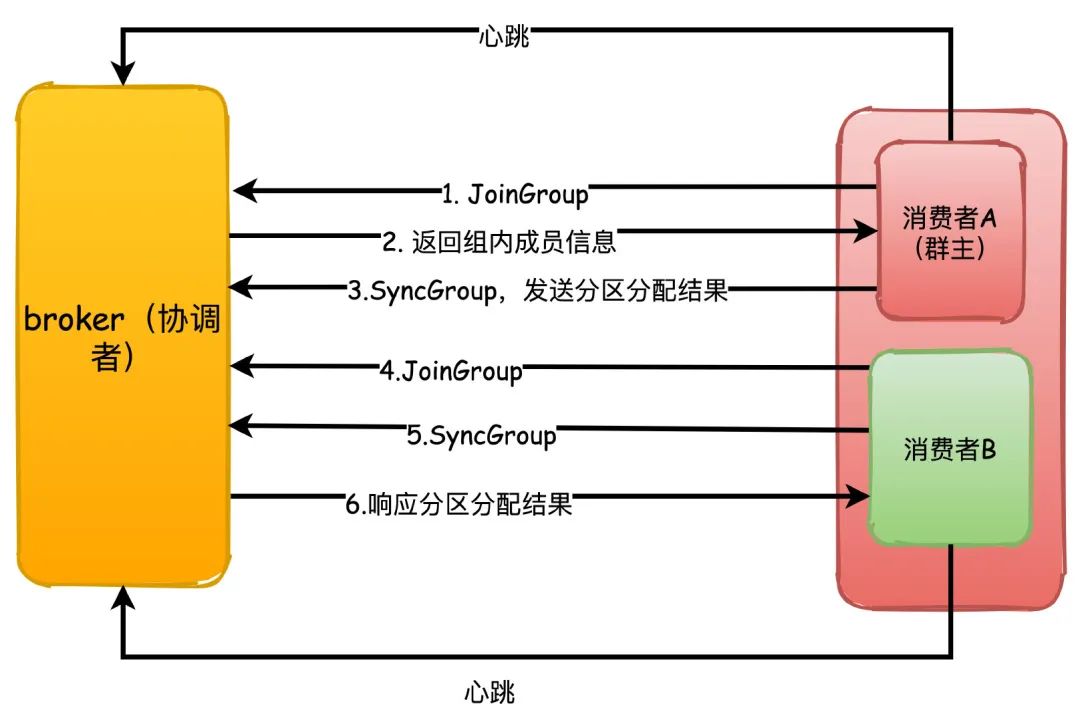
The following describes the rebalancing process.
The rebalancing mechanism relies on the heartbeat between the consumer and the coordinator to maintain. The consumer will have an independent thread to send the heartbeat to the coordinator regularly. This can be controlled by the parameter heartbeat.interval.ms. The interval time for sending heartbeats.
1. When each consumer joins the group for the first time, it will send a JoinGroup request to the coordinator. The first consumer to send this request will become the "group owner", and the coordinator will return the group member list to the group owner.
2. The group owner executes the partition allocation strategy, and then sends the allocation result to the coordinator through the SyncGroup request, and the coordinator receives the partition allocation result
3. Other group members also send SyncGroup to the coordinator, and the coordinator responds to them with the partition assignment of each consumer
7. Specifically talk about the partition allocation strategy?
There are three main allocation strategies:
Range
This is the default policy. The general meaning is to sort the partitions, and the higher-ordered partitions can be allocated to more partitions.
For example, there are 3 partitions, and Consumer A is ranked higher, so it can be allocated to two partitions P0\P1, and Consumer B can only be allocated to one P2.
If there are 4 partitions, then they will be allocated exactly 2.
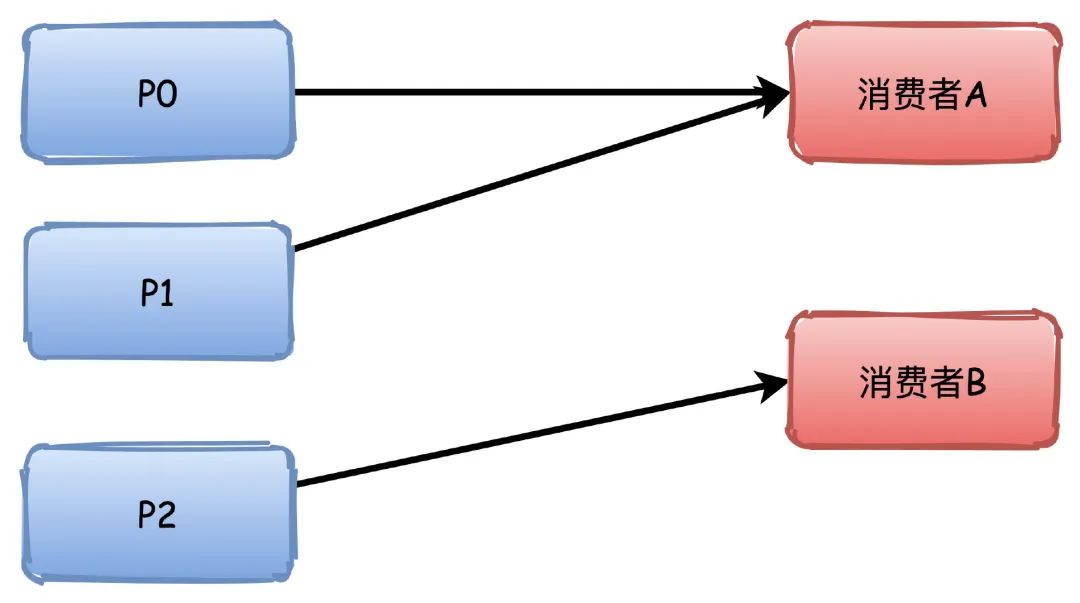
However, this allocation strategy will be a little problematic. He allocates according to the topic, so if the consumer group subscribes to multiple topics, it may lead to uneven partition allocation.
For example, the P0\P1 of the two topics in the figure below are all assigned to A, so that A has 4 partitions, while B has only 2. If the number of such topics is more, the imbalance will be more serious.

RoundRobin
That is what we often call polling. This is relatively simple, and you can easily understand it without drawing a picture.
This will perform round-robin allocation according to all topics, and there will be no problem of uneven partition allocation when there are more topics such as Range.
P0->A, P1->B, P1->A. . . and so on

Sticky
This literally means sticky strategy , which is probably what it means. The main consideration is to make the allocation of partitions smaller changes under the premise of balanced allocation.
For example, P0\P1 was allocated to consumer A before, so try to allocate it to A next time.
The advantage of this is that the connection can be reused. To consume messages, it is always necessary to connect with the broker. If the last allocated partition can be maintained, then there is no need to frequently destroy and create connections.
8. How to ensure message reliability?
The guarantee of message reliability is basically explained from three aspects (this is more comprehensive and impeccable)
Producer sends message lost
Kafka supports 3 ways to send messages, which are also the conventional 3 ways. After sending, regardless of the result, synchronous sending, or asynchronous sending, basically all message queues play like this.
1. Send and forget, call the send method directly, regardless of the result, although automatic retry can be turned on, there will definitely be a possibility of message loss
2. Synchronous sending, synchronous sending returns the Future object, we can know the sending result, and then process it
3. Asynchronously send, send a message, and specify a callback function at the same time, and perform corresponding processing according to the result
To be on the safe side, we generally use asynchronous sending with callbacks to send messages, and then set the parameters to keep retrying if the message fails to send.
1,acks=all, this parameter can be configured with 0|1|all .
0 means that the producer writes the message regardless of the server's response , the message may still be in the network buffer, the server does not receive the message at all, and of course the message will be lost.
1 means that at least one copy is considered successful after receiving the message , and one copy must be the leader copy of the cluster, but if the node where the leader copy is located just hangs, the follower does not synchronize the message, and the message is still lost.
If all is configured, it means that all ISRs are successfully written , and the message will be lost unless all the copies in the ISR are down.
2, retries=N, set a very large value , so that the producer can keep retrying after the failure to send the message
Kafka's own messages are lost
Kafka still has the possibility of losing messages because messages are written to disk asynchronously through PageCache .
Therefore, the possible setting parameters for the loss of kafka itself:
replication.factor=N , set a relatively large value to ensure that there are at least 2 or more replicas.
min.insync.replicas=N , which represents how the message can be considered to be successfully written. Set a number greater than 1 to ensure that at least one or more replicas are written to be successful.
unclean.leader.election.enable=false, this setting means that partition replicas that are not fully synchronized cannot become leader replicas. If it is true, after those replicas that are not fully synchronized leaders become leaders, there will be a risk of message loss.
Consumer message lost
The possibility of loss of consumers is relatively simple, just turn off the automatic submission of displacement , and change to manual submission of successful business processing .
Because when the rebalancing occurs, the consumer will read the offset of the last commit , and the auto commit is every 5 seconds by default, which will lead to repeated consumption or loss of messages.
enable.auto.commit=false , set to manual commit .
There is one more parameter we may also need to take into account:
auto.offset.reset=earliest, this parameter represents how the consumer handles when there is no offset to submit or there is no offset on the broker. earliest means reading from the beginning of the partition, and the message may be read repeatedly, but it will not be lost. Generally, we must ensure idempotency on the consumer side. The other latest means reading from the end of the partition, and there will be a probability of loss. information.
Combining these parameter settings, we can ensure that the message will not be lost and ensure reliability.
9. Let’s talk about the copy and its synchronization principle, right?
As mentioned before, Kafka replicas are divided into Leader replicas and Follower replicas , that is, master replicas and slave replicas. Unlike other replicas such as Mysql, only Leader replicas in Kafka will provide services to the outside world, and Follower replicas are simply and Leader maintains data synchronization as a function of data redundancy and disaster recovery.
In Kafka, we collectively call the set of all replicas AR ( Assigned Replicas ), and the replica set that keeps synchronization with the Leader replica is called ISR ( InSyncReplicas ).
ISR is a dynamic set. The maintenance of this set will be controlled by the replica.lag.time.max.ms parameter, which represents the maximum time behind the leader copy. The default value is 10 seconds, so as long as the follower copy is not behind the leader copy by more than 10 Seconds or more, it can be considered to be synchronized with the Leader (simply can be considered to be the synchronization time difference).
There are also two key concepts for synchronization between replicas:
HW (High Watermark) : The high water mark, also known as the replication point , indicates the location of synchronization between replicas. As shown in the figure below, 0~4 green indicates submitted messages, which have been synchronized between replicas, consumers can see these messages and consume them, 4~6 yellow indicate uncommitted messages, and may also Without synchronization between replicas , these messages are invisible to consumers.
LEO (Log End Offset): The offset of the next message to be written
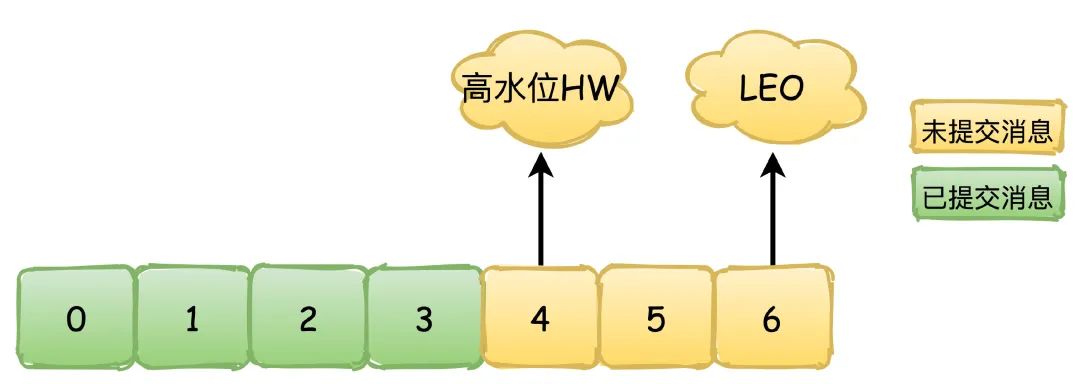
hw
The process of synchronization between replicas depends on the update of HW and LEO . The process of replica synchronization messages is demonstrated by their value changes. Green represents the leader replica, and yellow represents the follower replica.
First, the producer keeps writing data to the leader. At this time, the LEO of the leader may have reached 10, but the HW is still 0. The two followers request synchronization data from the leader, and their values are both 0.

Then, the message continues to be written, the LEO value of the leader changes again, and the two followers also pull their own messages, so they update their own LEO values, but the HW of the leader still does not change at this time.

At this point, the Follower pulls data from the Leader again. At this time, the Leader will update its HW value and update it by taking the smallest LEO value in the Follower.

After that, the leader responds to its own HW to the follower, and the follower updates its own HW value. Because the message is pulled again, the LEO is updated again, and the process is analogous.

10. Why did the new version of Kafka abandon Zookeeper?
I think this question can be answered in two ways:
First of all, from the perspective of the complexity of operation and maintenance, Kafka itself is a distributed system, and its operation and maintenance is already very complicated. In addition, it needs to rely heavily on another ZK, which has a huge impact on cost and complexity. Said it was a lot of work.
Secondly, performance issues should be taken into account. For example, the previous operations of committing displacement are stored in ZK, but ZK is actually not suitable for such high-frequency read and write update operations, which will seriously affect the ZK cluster. Performance, in this regard, in the new version, Kafka also handles the submission and storage of displacements in the form of messages.
In addition, Kafka relies heavily on ZK for metadata management and cluster coordination. If the scale of the cluster is large and the number of topics and partitions is large, it will lead to too much metadata in the ZK cluster and excessive cluster pressure, which directly affects the delay of many Watches. time or lost.
11. Why is Kafka fast?
1. Sequential IO
Kafka writes messages to partitions by appending, that is, sequentially writing to disk , not random writing. This speed is much faster than ordinary random IO, almost comparable to the speed of network IO.
2. Page Cache and Zero Copy
When Kafka writes message data, it uses mmap memory mapping instead of writing to disk immediately. Instead, it uses the operating system's file cache PageCache to write asynchronously, which improves the performance of writing messages. Zero copy is achieved through sendfile.
3. Batch processing and compression
When Kafka sends messages, it does not send messages one by one, but combines multiple messages into one batch for processing and sending. It is also reasonable to consume messages. One batch of messages is pulled for consumption at a time.
And Producer, Broker, and Consumer all use optimized compression algorithms. The use of compression for sending and message messages saves the overhead of network transmission, and the use of compression for Broker storage reduces disk storage space.
——————————————————————————————————
Learning: Interview Question Series: Kafka's 11 Deadly Serial Questions