Map interface and its implementation class
Map interface:
The storage is in the form of key-value pairs. The key-value key-value pair exists. The key value cannot be repeated, and the value can be repeated.
Methods under the Map interface:

Explanation of common methods in collections:
// V put(K key, V value) 向集合中添加键值对
hashMap.put("张杰","谢娜");
// hashMap.put("张杰","谢娜2");
System.out.println(hashMap.size());
//void clear() 将集合元素清空处理
// hashMap.clear();
//boolean containsKey(Object key) 判断集合中是否存在指定的键 key 存在返回true 不存在返回false
boolean key = hashMap.containsKey("战三");
// System.out.println(key);
//boolean containsValue(Object value) 判断集合中是否存在指定的值value 存在返回true 不存在返回false
hashMap.containsValue("zhangsna");
// System.out.println(hashMap.size());
//V get(Object key) 通过键key获取value
String s = hashMap.get("张杰");The traversal form of the collection under the Map interface:
/通过entrySet遍历键值对
Iterator <Map.Entry <String, String>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry <String, String> entry = iterator.next();
System.out.println("key:"+entry.getKey()+",value:"+entry.getValue()+ " ");
}
//通过keySet遍历键
Iterator <String> iterator1 = hashMap.keySet().iterator();
while (iterator1.hasNext()) {
String key1 = iterator1.next();
System.out.print(key1+" ");
}
//通过values()遍历值
Iterator <String> iterator2 = hashMap.values().iterator();
while (iterator2.hasNext()) {
String value = iterator2.next();
System.out.print(value+" ");
}
Introduction to HashMap
Features:
1. The stored data is in the form of key-value pairs, the key cannot be repeated, and the value can be repeated
2. Both key and value can be null
3. The order of internal elements is not guaranteed
4. The underlying data structure is a hash table
Hash table: A data structure in which keys are mapped to specific values through a hash function
Hash collision: hash function f(x), f(m) = f(n), m is not equal to n
Hash function: direct hash, modulo.
Hash collision: chain address method, detection method (linear detection, random detection).
Chain address method: As shown in the figure:
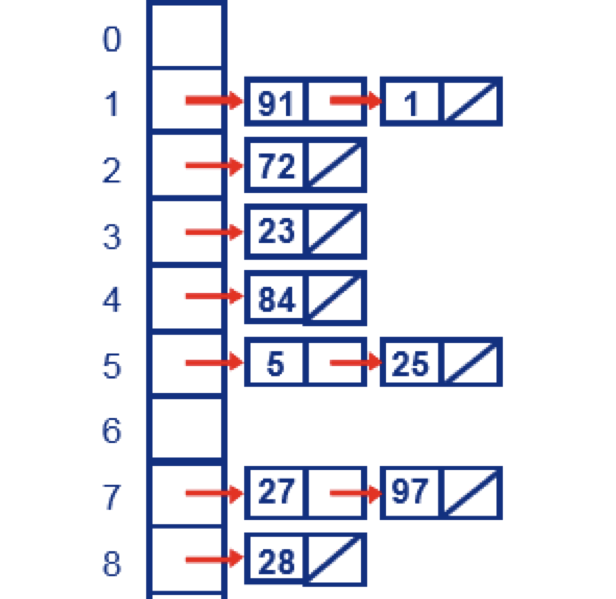
HashMap source code research
inheritance relationship
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable HashMap inherits from AbstractMap. This abstract class implements the common methods of the Map interface, which is convenient for subclasses to reuse.
Implements the class Map interface, with all the methods provided in Map
Implement Cloneable and Serializable interfaces
Constructor
SortedMap接口,SortedMap接口具有排序功能,具有比较器类Comparator
比较器类说明:
Comparable和Comparator比较
两个比较器都是接口:
Comparable接口中提供方法:
```java
public interface Comparable<T> {
public int compareTo(T o);
}
```
该接口中提供了一个compareTo方法,
返回值分别为 -1 ,0,1
在类内部作为比较器使用,一旦确定比较属性,就不能更改
Comparator接口:
```java
public interface Comparator<T> {
int compare(T o1, T o2);
}
```
接口中提供了compare方法,
该方法返回结果为大于0,等于0,小于0
类外部实现,自定义实现比较过程使用该接口
使用场景:对数据进行排序选择TreeMapproperty default value
//默认初始容量 :值为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子:0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//默认空表
static final Entry<?,?>[] EMPTY_TABLE = {};
//存放数据 table属性,是entry类型数组
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//存放的键值对个数
transient int size;
//扩容阈值 ,在扩容时判断 threshold =table.length()*loadFactor
int threshold;
//加载因子
final float loadFactor;
//版本控制
transient int modCount;
//key哈希相关
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
//key哈希相关
transient int hashSeed = 0;
underlying data structure
//存放数据位置
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}It can be seen from the above that the data stored at the bottom of HashMap is in the form of a data plus linked list, that is, a hash table structure
Expansion mechanism
Expansion timing: when size>threshold, expansion will be performed
Common method
Insert element: put(key,value)
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
//当table数组为空时,进入初始化table数据,当第一次调用put操作会进入
inflateTable(threshold);
}
//key为null,将数据存放在0号卡槽位置
if (key == null)
return putForNullKey(value);
//key不为null的处理
//通过key找到对应的存放卡槽位置
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//通过位置i找到卡槽i位置的数据链表,从头遍历,找key是否存在
//判断条件是hash和key,相等值更新
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//key在i位置不存在,需要新增entry节点存放数据
modCount++;
addEntry(hash, key, value, i);
return null;
}
private V putForNullKey(V value) {
//key为null将哈希位置为0号位置,需要遍历0号卡槽链表、判断key为null是否存在
//存在将entry中value进行跟新,返回旧的value中
//不存在则新建entry实体,存放put的数据
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
//通过key哈希找到对应卡槽
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
通过key的哈希值找到在哈希表中的位置
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
容量是16
0001 0000 16
0000 1111 15
1010 1001
-------------
0000 1001 9
return h & (length-1);
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//当存放数据size大于扩容阈值threshold,进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//对HashMap进行2倍的扩容
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
//获取当前key应该插入的新卡槽位置
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//扩容
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//新创建数组为原来的2倍
Entry[] newTable = new Entry[newCapacity];
//将原map中的每一个entry实体进行重新哈希到新的map中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//threshold = table.length*loadFactor
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//采用头插法将数据插入
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}put operation steps:
1. First determine whether the key is null, special treatment, and store it in the slot 0 of the hash table
2. Whether the data whose key is null exists, traverse the linked list of slot 0, if it exists (==), update the value and return
3. If it does not exist, create a new node (addentry)
4. If the key is not null, use the key to calculate the hash value and find the slot position in the hash table (hash, indexFor)
5. Obtain the linked list in the corresponding card slot, traverse to find out whether the key exists, if it exists (hash&&equals), update the value and return
6. The key does not exist in the linked list, create a new node (addEntry)
7. Consider whether to expand the capacity (size>threshold), you need to expand the capacity, make the new size twice the original size, and then change the data in the original hash table
are re-hashed into the new hash table and update the slot position of the currently inserted node
8. Use head insertion to insert the new entry node into the given slot position
Get element: get(key)
public V get(Object key) {
//key为null,直接到0号卡槽位置获取结果
if (key == null)
return getForNullKey();
//key不为null
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
//如果map为空,返回null
if (size == 0) {
return null;
}
//在0号卡槽位置,对链表遍历,查找key为null是否存在,存在则找entry中value返回,否则返回null
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
通过key找到对应entry实例
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//通过key的哈希找到key对应卡槽位置
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {
Object k;
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}Query process:
1. If the key is null, traverse the linked list query at slot 0. If the key exists, return the value of the entry, otherwise return null
2. If the key is not null, hash the key, find the corresponding card slot, traverse the linked list, determine whether the key exists (hash, key.equals), return the value of the entry, otherwise return null
Remove elements: remove(key)
Delete the entry entity that can be located by key
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
//如果集合为空,直接返回null
if (size == 0) {
return null;
}
//通过key哈希找到对应卡槽(key为null卡槽为0)
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
//删除节点即解决单向链表的删除问题:解决思路:给定两个指针,两指针一前一后,前指针表示要删除的节点,
、 //通过后一个指针来将节点和前节点指针的next建立联系
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
//如果删除的是头结点,将后一个节点作为当前卡槽的头结点
if (prev == e)
table[i] = next;
else
//后一个指针prex来将节点和前节点指针的next建立联系
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}Deletion process:
1. Find the slot position by key hash (key is null in slot 0)
2. The linked list corresponding to the card slot is traversed and searched. Given two pointers one after the other, the front pointer finds the node to be deleted, and the back pointer establishes a relationship with the next node
Summarize the characteristics of HashMap
1. Data structure: Hash table (array + linked list)
2. Default array size: 16
3. Expansion mechanism: the size is twice the length of the original array
4. Capacity expansion factor: 0.75f
5. Expansion condition: 0.75*length of the array
6. Thread-safe: The collection is thread-unsafe
7. The type of stored data is a key-value pair (key and value)
8. Both key and value can be null
9. The stored data is disordered
10. The key cannot be repeated, and the value can be repeated
11. If the key is the same, the value will be overwritten
Introduction to LinkedHashMap
It can be seen from the collection frame diagram: LinkedHashMap belongs to the sub-implementation class of HashMap
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>Basic Features:
1. The key cannot be repeated, and the value can be repeated. 2. LinkedHashMap is insertion order/access order accessOrder: true access order false: insertion order 3, the underlying data structure is a hash table 4, both key and value can be is null
How is LinkedHashMap ordered?
data structure
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>The inheritance relationship through LinkedHashMap is inherited from HashMap, and the properties and methods of HashMap are inherited
The table attribute and entry type will be inherited, and its interior is also a hash table structure
Similarities and differences between HashTable and HashMap
Same point:
1. The underlying data organization is a hash table (JDK 1.7)
2. In the key-value key-value pair, the key cannot be repeated, and the value can be repeated
3. Both HashMap and Hashtable are inserted unordered
difference:
1. HashTable inherits from Dictionary class, which is the parent class of map provided earlier. It is recommended to use AbstractMap class
2. The default initial value of HashTable is 11
3. HashTable is thread-safe (by adding the synchronized key to the method)
4. The key and value in HashTable cannot be null
5. The hashing process for keys in HashTable is different from HashMap
6. The expansion of HashTable is based on 2 times plus 1 size expansion ((oldCapacity << 1) + 1)
TreeMap collection
Basic Features:
treeMap features 1. The keys are sorted in order of size. The default is from small to large. 2. The key cannot be null, and the value can be null. 3. The key cannot be repeated, and the value can be repeated.
How does TreeMap achieve key ordering?
The underlying data structure of TreeMap is a red-black tree
Time complexity O(log n) O(n) o(1)
TreeMap inheritance relationship
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializabletreemap implements the NavigableMap interface, supports a series of navigation methods, returns an ordered key collection, etc.
The NavigableMap interface is declared as follows:
public interface NavigableMap<K,V> extends SortedMap<K,V>The NavigableMap interface inherits from
SortedMap interface, SortedMap interface has sorting function, with comparator class Comparator
Comparator class description:
Comparable and Comparator Comparison
Both comparators are interfaces:
Methods are provided in the Comparable interface:
public interface Comparable<T> {
public int compareTo(T o);
}This interface provides a compareTo method,
The return value is -1, 0, 1 respectively
Used inside a class as a comparator, once a comparison property is determined, it cannot be changed
Comparator interface:
public interface Comparator<T> {
int compare(T o1, T o2);
}The compare method is provided in the interface,
This method returns a result greater than 0, equal to 0, less than 0
The external implementation of the class, the custom implementation comparison process uses this interface
Usage scenario: Sort data and select TreeMap