On December 18, 2021, the annual 2021 Fintech, Regtech, Blockchain Blue Book Conference (hereinafter referred to as the "Blue Book Conference") was successfully held. Affected by the epidemic, this conference was broadcast live, with even numbers. Technology was invited to attend and give a speech.
The Blue Book Conference is guided by the Social Sciences Literature Press of the Chinese Academy of Social Sciences, the China Payment and Clearing Association, and the Financial Technology Professional Committee of the China Society for Finance and Banking. Hosted by Beijing Blockchain Technology Application Association (BBAA).
The conference released the "China Regulatory Technology Development Report (2021)", "China FinTech Development Report (2021)", "China Blockchain Development Report (2021)", and the three annual blue books were published by the People's Bank of China Monetary Policy Report Sun Guofeng, director of the Department, Li Wei, director of the Science and Technology Department of the People's Bank of China, and Yao Qian, director of the Science and Technology Supervision Bureau of the China Securities Regulatory Commission, served as editor-in-chief.
The three blue books are all guided by the People's Bank of China and other authoritative institutions, and published under the authorization of the Social Sciences Literature Publishing House. At the same time, the "Fintech Industry Map", "Regulatory Technology Industry Map" and "Blockchain Industry Map" were released, focusing on describing the industrial ecology, subdivisions and representative enterprises in their respective fields, which is helpful for an objective and comprehensive , Correctly understand the development level and trend of various fields, and provide scientific reference for government departments, enterprises, investment institutions and industry practitioners.
The following is the transcript of even-numbered technology speeches:
1. Data warehouse architecture development route: unlimited expansion, super performance and compatibility
In recent years, big data and cloud computing technologies have been continuously innovating, and they have been rapidly implemented in thousands of industries, especially the financial industry. By changing strategic decisions and changing the way companies create value and services, they continue to demonstrate the driving force of data on business. When we mention big data and cloud computing, we have to mention cloud data warehouse. How did the cloud warehouse appear in the spotlight of today's financial technology? We can briefly review the development of the data warehouse together.
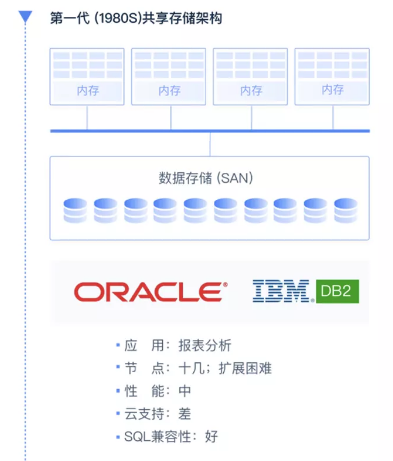

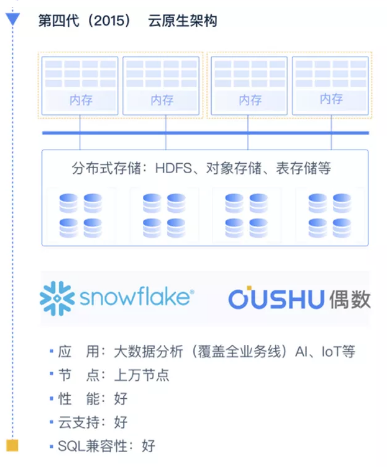
The development of data warehouse can be divided into four stages. Since the 1980s, the shared storage architecture represented by Oracle and IBM DB2 was the mainstream database product at that time. In the early days, we did not use analytical databases specifically for analytical applications, but still used classic transactional databases.
I believe that many developers are very familiar with the characteristics of traditional transactional databases, such as SQL compatibility is very good. However, when doing large-scale complex queries, the performance is not very satisfactory. At the same time, due to the characteristics of the shared storage architecture itself, the scalability is not very good. Usually, a cluster can only reach a dozen nodes.
As the volume of data continues to increase, and the needs of users for analysis continue to increase. Since the 1980s, MPP analytical databases specially used for analysis have appeared. Like the well-known Greenplum and Teradata, they still maintain the same excellent SQL compatibility as traditional transactional databases. Although the storage and computing of the MPP database are not separated, it is Such a parallel architecture can already be scaled to hundreds of nodes. Like traditional transactional databases, MPP architecture is not cloud friendly.
Since 2000, the concept of big data platform, which is the third-generation SQL-on-Hadoop architecture, has been proposed and promoted successively at home and abroad. For example, SparkSQL and Cloudera, which we are more familiar with, can reach thousands of nodes and have certain support for the cloud. But compared with the traditional MPP data warehouse, it is not satisfactory in performance and SQL compatibility.
What is the architecture of the next-generation data warehouse? We think it should be a cloud-native architecture. Although the Cloud Native Computing Foundation CNCF provides the definition of cloud native at the application level, there is no unified definition of cloud native database in the industry at present. From the characteristics of the architecture itself and the characteristics of cloud facilities, you can find that cloud native should completely separate storage and computing. The cloud-native architecture optimizes the shortcomings of MPP and SQL-on-Hadoop. A single cluster can reach thousands of nodes, and it is also very perfect in complex query performance and SQL compatibility. Since storage and computing are completely separated, it can be easily, that is, cloud-native infrastructure that supports mainstream cloud platforms. Snowflake in the United States has attracted much attention in the capital market with this feature, and even attracted the attention of Mr. Buffett; in China, Oushu Database, which is independently developed by Even Technology, has also gained a lot of users and investments by virtue of its completely separated computing and storage architecture. people's favor.
2. OushuDB Architecture
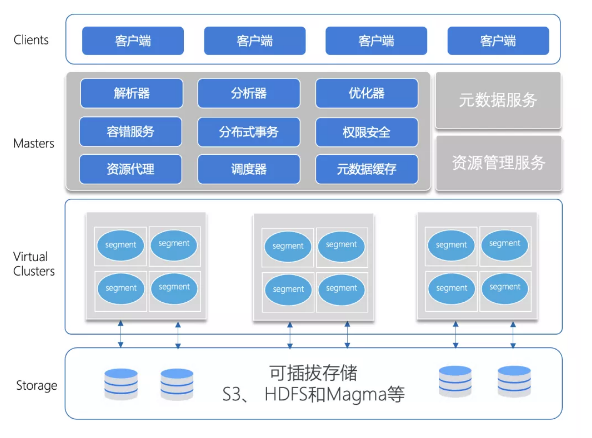
-
Extremely fast analytical database
-
Leading SIMD performance optimization technology
-
Realize PB-level big data interactive query
-
The performance exceeds that of traditional data warehouses by 5-10 times and that of SQL on Hadoop engines by dozens of times
-
-
Cloud-native database architecture
-
Separation of computing and storage, multiple virtual computing clusters, elastic expansion, multi-level resource management
-
-
Fully compatible with international standards such as ANSI-SQL
-
High compatibility, ACID characteristics
-
Seamless support for AI
-
Domestic independent and controllable
-
Separation of computing and storage
-
Data can be easily shared between computing clusters, which is a great advantage over traditional databases
-
-
Multiple virtual computing clusters
-
Resources between virtual computing clusters can be isolated without affecting each other
-
-
pluggable storage
-
Support various object storage, HDFS and self-developed Magma distributed table storage
-
-
Multi-cloud, hybrid cloud and cross-cloud support
-
Support Tencent Cloud, Alibaba Cloud, Huawei Cloud, AWS, Azure, Kingsoft Cloud
-
80+% of enterprises use multi-cloud to prevent cloud vendor lock-in
-
-
Elastic expansion architecture
-
No need to redistribute data when adding or removing nodes
-
High system availability and good scalability
-
-
Multi-level resource management
-
Support global-user-operator multi-level resource management
-
Pay-as-you-go
-
But OushuDB is not a mirrored Snowflake. OushuDB has its own characteristics and advantages. For example, in terms of underlying storage, Snowflake only supports object storage S3, so it can only provide services to users on AWS;
In addition to S3, OushuDB also supports Tencent Cloud's COS storage, HDFS and even self-developed Magma storage. In this way, OushuDB can meet the needs of users on different cloud platforms and private deployments. It also relies on multiple storage formats to provide better solutions for mixed workloads and real-time analytics.
We can see that the data warehouse of cloud native architecture has many advantages and characteristics, such as separation of computing and storage, multiple virtual computing clusters, and pluggable storage. Due to time reasons, I will not expand them one by one. I would like to focus on sharing that due to the elastic expansion of the cluster facilitated by the complete separation of computing and storage, the most direct feeling from the user side is billing by volume.
3. Cost remains unchanged and efficiency improves

What kind of new services and experiences will this bring to users? It turned out that a complex query took 10 computing nodes to run for an hour, now we can choose 100 computing nodes to run for 6 minutes. With the same IT cost, the user's efficiency is improved. I believe that such a user experience will bring a more extreme experience and imagination space for digital transformation to customers in many industries, including the financial industry.