foreword
Amazon is the largest online e-commerce company in the United States. It is located in Seattle, Washington. It
is one of the earliest companies to start e-commerce on the Internet. Amazon was established in 1994.
Today I will teach you how to use Python to batch collect product data on the Amazon platform.
Address: https ://www.amazon.cn/
Analyze website data and find the url address
1. Press F12, open the developer tools, and refresh the website
2. Click search, enter the data keyword
3. Find the url address where the data is located

start our code
1. Send a request
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'session-id=460-4132650-8765807; i18n-prefs=CNY; ubid-acbcn=457-7935785-7667244; session-token=Laa3G6hMbBpdAIPYwutQqKxkSISU8fb2jTr0JiczqkeVISvqn2eqjw4N0BAbYfmy8+/S1B3kLvDb9ImsBnbwQHU6JG8EToefDoi69keaL1F6ExYDXCSqFF0hC4fkGAFJlNYYNqfVlvj5ewTVJP1pYgL4JG2tjM5O2Uk7ufiL9s7gvidAMaUj1QtBW5puqmoG; csm-hit=adb:adblk_no&t:1645531896484&tb:s-VMQ97YXPSC1MBACTN14J|1645531895768; session-id-time=2082729601l',
'downlink': '10',
'ect': '4g',
'Host': 'www.amazon.cn',
'Referer': 'https://www.amazon.cn/b/ref=s9_acss_bw_cg_pccateg_2a1_w?node=106200071&pf_rd_m=A1U5RCOVU0NYF2&pf_rd_s=merchandised-search-2&pf_rd_r=KE929JDVF8QRWWDQCWC0&pf_rd_t=101&pf_rd_p=cdcd9a0d-d7cf-4dab-80db-2b7d63266973&pf_rd_i=42689071',
'rtt': '150',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="98", "Google Chrome";v="98"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
}
url = 'https://www.amazon.cn/s?rh=n%3A106200071&fs=true&ref=lp_106200071_sar'
response = requests.get(url=url, headers=headers)
2. Get data
print(response)
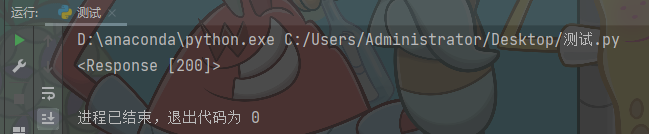
The return result is <Response [200]>: the request is successful
and the result is encapsulated
data_html = response.text
3. Parse the data
selector = parsel.Selector(data_html)
divs = selector.css('.a-section.a-spacing-base')
for div in divs:
# ::text: 提取到标签文本内容
title = div.css('.a-size-base-plus.a-color-base.a-text-normal::text').get()
price = div.css('.a-size-base.a-link-normal.s-underline-text.s-underline-link-text.s-link-style.a-text-normal .a-price .a-offscreen::text').get()
img_url = div.css('.a-section.aok-relative.s-image-square-aspect .s-image::attr(src)').get()
link = div.css('.a-link-normal.s-no-outline::attr(href)').get()
print(title, price, img_url, link)
4. Save data
with open('亚马逊.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([title, price, img_url, link])

5. Turn the page
for page in range(1, 401):
url = f'https://www.amazon.cn/s?i=computers&rh=n%3A106200071&fs=true&page={page}&qid=1645537294&ref=sr_pg_3'

In this way, the complete data is collected: complete source code
. There is also Python data analysis + visualization project case teaching: Amazon platform user order data analysis