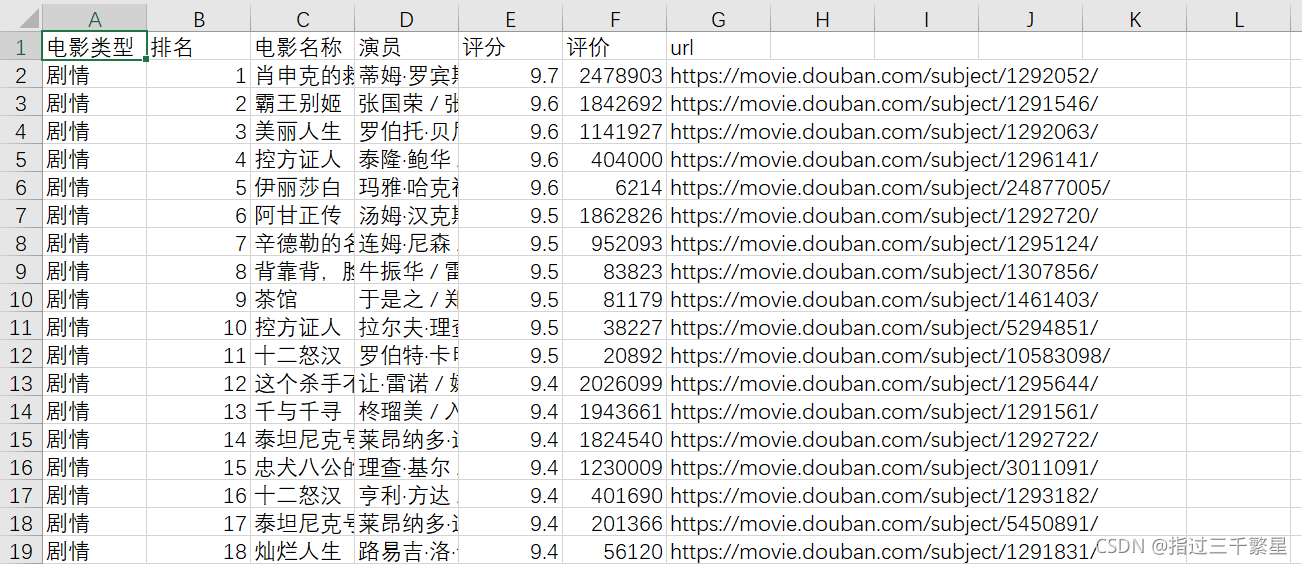
Introduction to requirements
Get all the categories of Douban Movies
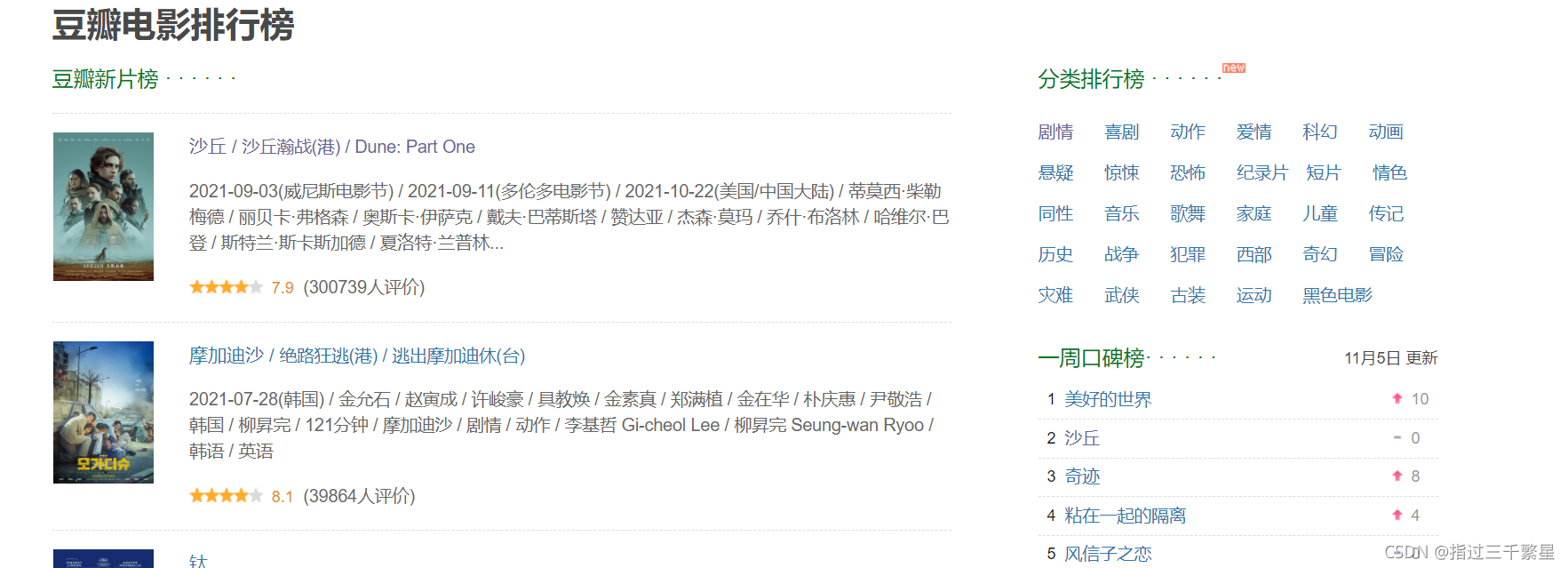
Find the top 20 movies in various categories in order, and get their information, such as movie name, movie poster, number of evaluations, actor list, etc.
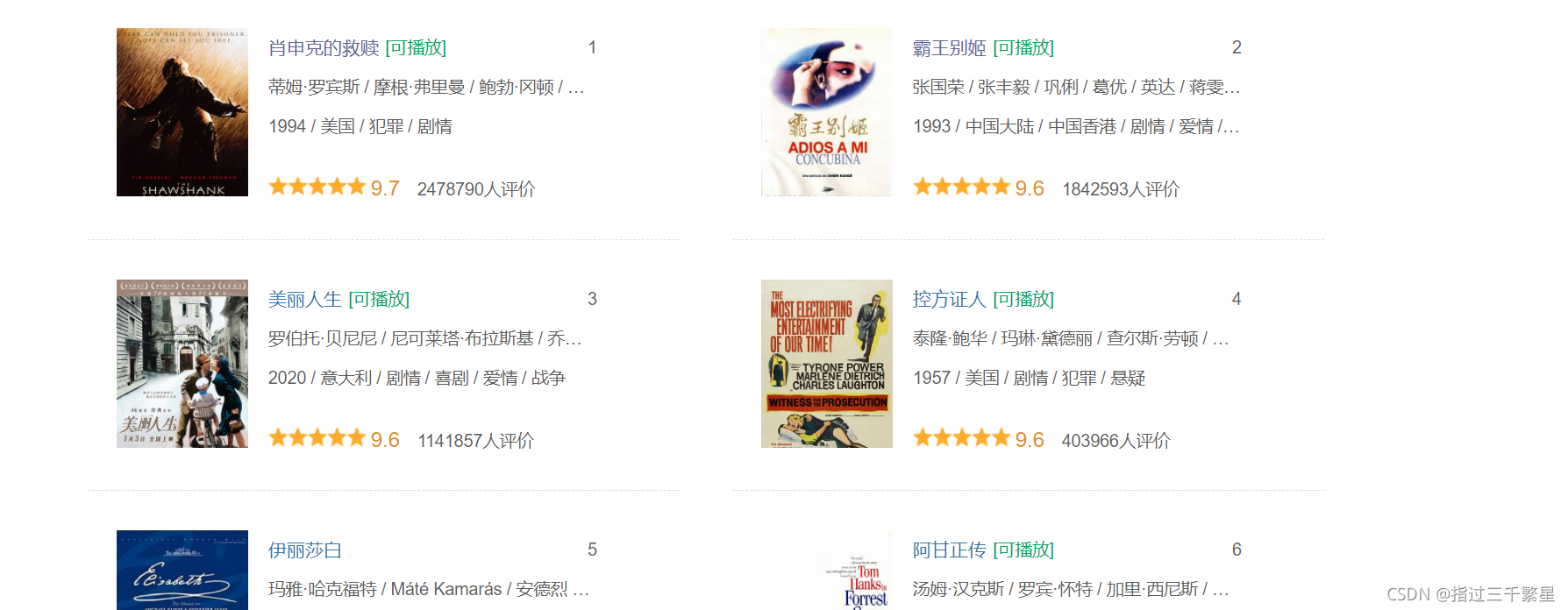
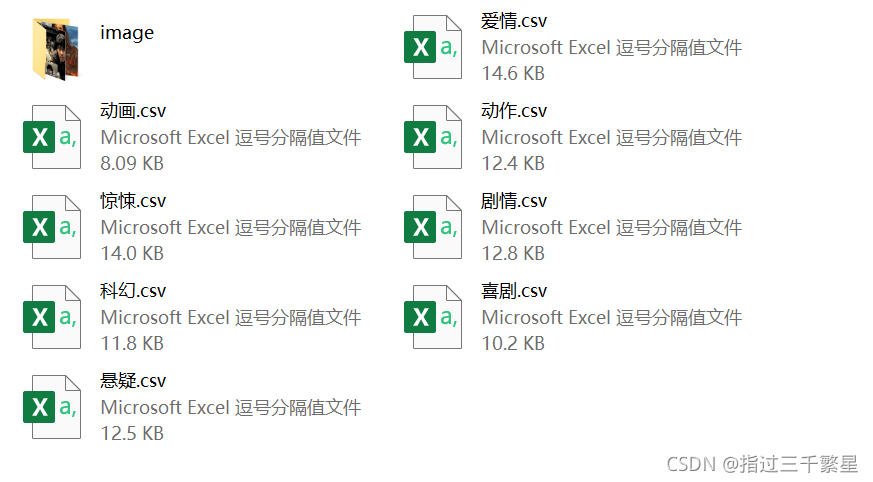
To achieve the desired effect, store the movie information in csv file, all movie posters are stored in the same level folder
Libraries needed
| library | Introduction | The author's blog portal |
|---|---|---|
| csv | Used to write movie information into a csv file | Not yet completed |
| selenium | Dynamically load web page data and find movie information from web page source code | Not yet completed |
| requests | Send a web page access request | Not yet completed |
| you | Folder or save path management | os library |
| bs4 | Parse the source code of the web page and get the desired data information from it | BeautifulSoup library |
| re | Parse parsing web content | re module |
| threading | Multi-threaded efficient execution of tasks | Not yet completed |
Process classification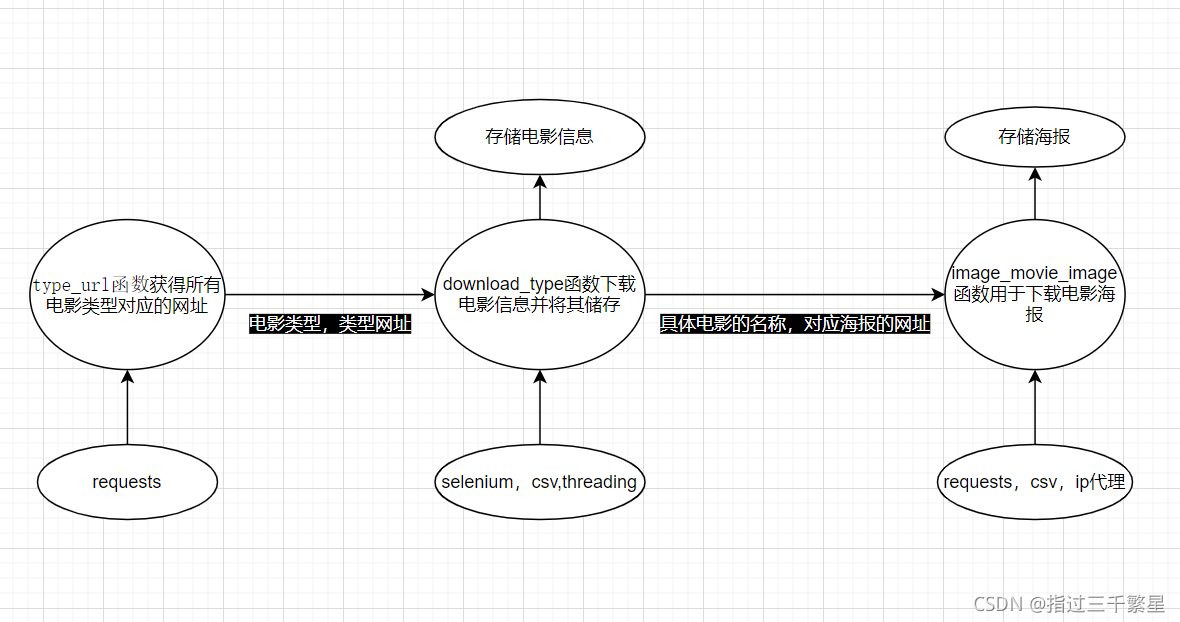
step by step
- Create a movie class
class Movie:
def __init__(self, type):
self.img = None # 电影海报
self.name = None # 名称
self.type = type # 类型
self.rank = None # 排名
self.crew = None # 演员列表
self.rating = None # 评分
self.comment = None # 评价
self.url = None # 网址
def get(self):
return [self.type, self.rank, self.name, self.crew, self.rating, self.comment, self.url]
- Create a function to get the genre of the movie
def type_url():
# 设置请求头,请求得到所有电影类型
headers = {
'user-agent': 'Mozzila/5.0'}
resp = requests.get(start_url, headers=headers)
# 使用bs4库解析网页内容
soup = BeautifulSoup(resp.text, 'html.parser')
# 定位网页信息
type_list = soup.find_all('a', href=re.compile('^/typerank'))
for item in type_list:
# 获取类型名
type_name = item.text
print(type_name)
# 调用函数,下载电影信息
download_type(type_name, item['href'])
time.sleep(3)
- Create a function to get movie posters
def image_movie_image(url, image_name):
image_save_path = Image_path + os.sep + image_name
# 请求电信海报所在的网址
try:
resp = requests.get(url, proxies={
'ip': nums_list[random.randint(0, len(nums_list) - 1)]})
with open(image_save_path, 'wb+')as f:
f.write(resp.content) # 将海报图片写入文件夹
except:
pass
- Create a function to get movie information
def download_type(type_name, url):
driver.get(bath_url + url)
saving_path = save_path + os.sep + type_name + '.csv'
# 五次拖动页面到最底部动态加载电影信息
for i in range(5):
target = driver.find_element(by='id', value='footer')
driver.execute_script('arguments[0].scrollIntoView();', target)
time.sleep(1)
count = 0
try:
with open(saving_path, 'a+', newline='') as f:
csv_f = csv.writer(f) # 创建一个csv对象
csv_f.writerow(headers) # 写入行列标题
for item in driver.find_elements('xpath', '//div[@class="movie-content"]'):
try:
movie = Movie(type_name) # 将创建的类实例化为对象
# 获取每个对象的属性值
movie.url = item.find_element('tag name', 'a').get_attribute('href')
movie.name = item.find_element('class name', 'movie-name-text').text
movie.img = movie.name + '.jpg'
movie.rating = item.find_element(By.CLASS_NAME, 'rating_num').text
movie.crew = item.find_element('class name', 'movie-crew').text
movie.rank = item.find_element('class name', 'rank-num').text
movie.comment = int(re.sub('\D', '', item.find_element('class name', 'comment-num').text))
# 使用movie对象的get方法返回其属性,将其属性按行写入csv文件
csv_f.writerow(movie.get())
# 获取每部电影海报的网址,调用函数,多线程开启下载
image_url = item.find_element(by=By.CLASS_NAME, value='movie-img').get_attribute('src')
threading.Thread(target=image_movie_image, args=(image_url, movie.img,)).start()
# 开启计数,每扒取一部电影次数加一,次数大于20停止该类型电影的扒取
count += 1
if count > 20:
break
time.sleep(1)
except:
pass
except Exception as e:
print(e)
complete implementation
import csv
import threading
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import requests
import re, os, random
driver = webdriver.Chrome() # 创建一个浏览器驱动
save_path = 'E:\\coding\\recourses\\douban1'
if not os.path.exists(save_path): # 不存在目录则创建
os.makedirs(save_path)
Image_path = save_path+os.sep+'image'
bath_url = 'http://movie.douban.com'
start_url = bath_url + '//chart'
headers = ['电影类型', '排名', '电影名称', '演员', '评分', '评价', 'url']
# 获取代理ip
url1 = 'https://www.kuaidaili.com/free/inha/'
response = requests.get(url=url1)
mode = re.compile('(\d+\.\d+\.\d+\.\d+)')
nums_list = mode.findall(response.text)
class Movie:
def __init__(self, type):
self.img = None # 电影海报
self.name = None # 名称
self.type = type # 类型
self.rank = None # 排名
self.crew = None # 演员列表
self.rating = None # 评分
self.comment = None # 评价
self.url = None # 网址
def get(self):
return [self.type, self.rank, self.name, self.crew, self.rating, self.comment, self.url]
def type_url():
# 设置请求头,请求得到所有电影类型
headers = {
'user-agent': 'Mozzila/5.0'}
resp = requests.get(start_url, headers=headers)
# 使用bs4库解析网页内容
soup = BeautifulSoup(resp.text, 'html.parser')
# 定位网页信息
type_list = soup.find_all('a', href=re.compile('^/typerank'))
for item in type_list:
# 获取类型名
type_name = item.text
print(type_name)
# 调用函数,下载电影信息
download_type(type_name, item['href'])
time.sleep(3)
def image_movie_image(url, image_name):
# 使用ip代理
url1 = 'https://www.kuaidaili.com/free/inha/'
response = requests.get(url=url1)
mode = re.compile('(\d+\.\d+\.\d+\.\d+)')
nums_list = mode.findall(response.text)
image_save_path = Image_path + os.sep + image_name
# 请求电信海报所在的网址
try:
resp = requests.get(url, proxies={
'ip':nums_list[random.randint(0, len(nums_list) - 1)]})
with open(image_save_path, 'wb+')as f:
f.write(resp.content) # 将海报图片写入文件夹
except:
pass
def download_type(type_name, url):
driver.get(bath_url + url)
saving_path = save_path + os.sep + type_name + '.csv'
# 五次拖动页面到最底部动态加载电影信息
for i in range(5):
target = driver.find_element(by='id', value='footer')
driver.execute_script('arguments[0].scrollIntoView();', target)
time.sleep(1)
count = 0
try:
with open(saving_path, 'a+', newline='') as f:
csv_f = csv.writer(f) # 创建一个csv对象
csv_f.writerow(headers) # 写入行列标题
for item in driver.find_elements('xpath', '//div[@class="movie-content"]'):
try:
movie = Movie(type_name) # 将创建的类实例化为对象
# 获取每个对象的属性值
movie.url = item.find_element('tag name', 'a').get_attribute('href')
movie.name = item.find_element('class name', 'movie-name-text').text
movie.img = movie.name + '.jpg'
movie.rating = item.find_element(By.CLASS_NAME, 'rating_num').text
movie.crew = item.find_element('class name', 'movie-crew').text
movie.rank = item.find_element('class name', 'rank-num').text
movie.comment = int(re.sub('\D', '', item.find_element('class name', 'comment-num').text))
# 使用movie对象的get方法返回其属性,将其属性按行写入csv文件
csv_f.writerow(movie.get())
# 获取每部电影海报的网址,调用函数,多线程开启下载
image_url = item.find_element(by=By.CLASS_NAME, value='movie-img').get_attribute('src')
threading.Thread(target=image_movie_image, args=(image_url, movie.img,)).start()
# 开启计数,每扒取一部电影次数加一,次数大于20停止该类型电影的扒取
count += 1
if count > 20:
break
time.sleep(1)
except:
pass
finally:
print(movie.name, '完成爬取!')
except Exception as e:
print(e)
type_url()
The author did not run the program completely, and the result obtained was
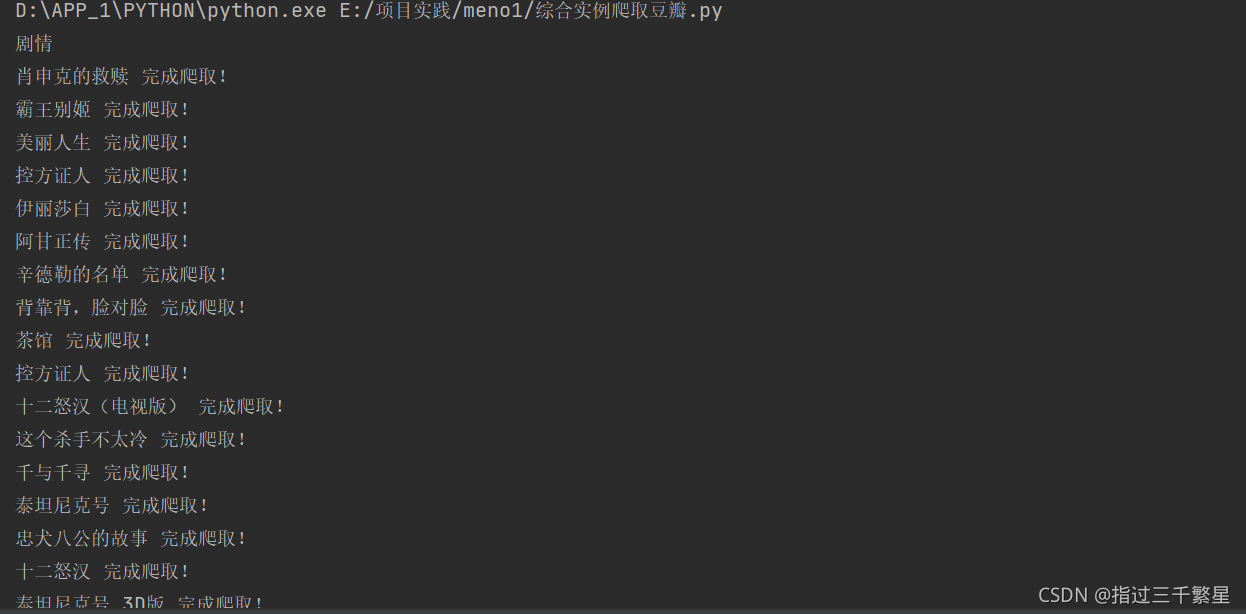
Poster:

Movie Information: