
JDK1.8 source code
Constructor
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
- initialCapacity: The initial size of the table array
- loadFactor: load factor
- concurrencyLevel: Concurrency level, used to determine the number of segments, the number of segments must be greater than or equal to the concurrency level
put execution process
- Calculate the hash value according to the hashCode() of the key
- If the table array is empty, initialize the table array
- When the located Node is null, use CAS to try to put it in, if it succeeds, it exits, and if it fails, it enters the loop again.
- If the Node.hash of the current position is equal to -1, the ConcurrentHashMap is expanding, and the current thread is going to help the transfer
- Use synchronized locking to put elements into a red-black tree or linked list (replace if the key already exists)
- If the length of the linked list is greater than 8, convert to a red-black tree
public V put(K key, V value) {
return putVal(key, value, false);
}
// 当元素存在时,onlyIfAbsent = true 直接返回旧值,不进行替换,否则进行替换
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 数组为空,初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 数组i这个位置的元素为null,并且cas设置成功,返回
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
// 链表的头节点有可能发生变化,再检测一遍
if (tabAt(tab, i) == f) {
// 是链表
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
} // 是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 链表长度 >= 8,并且数组长度 >= 64,链表转为红黑树
// 否则扩容
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// hashmap中元素个数加1
addCount(1L, binCount);
return null;
}
Why does Node.hash >= 0 mean it is a linked list?
Because the node of the red-black tree is TreeBin, the hash value is -2
There is a point to note here
If the length of the linked list is >= 8, and the length of the array is >= 64, the linked list will be converted into a red-black tree, otherwise the capacity will be expanded
get execution process
- Calculate the hash value according to the hashCode() of the key
- The first element located in the slot is the element to be obtained, then return directly
- If it is a red-black tree, get the value according to the tree
- If it is a linked list, get the value according to the linked list
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 所在槽的第一个元素就是要获取的元素
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 从红黑树上获取
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 从链表上获取
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
Why doesn't get need to be locked?
First, when taking the value from the array, the Unsafe api is used to ensure thread safety.
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
Second, Node objects use the volatile keyword to ensure visibility. Once final is assigned, it is also visible to other threads
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
When a rehash occurs, how will the get and put operations behave?
- The hash slot that has not been migrated to can perform get and put operations normally
- For the hash slot being migrated, get requests to normally access the linked list or red-black tree on the bucket, because rehash is to copy the new node to the table, not to move it
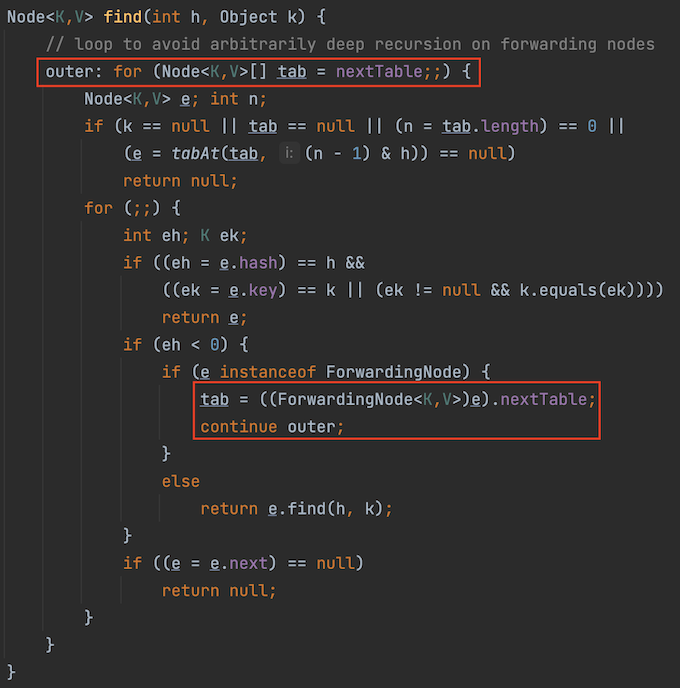
- The hash slot of the migration is completed, the get request goes to the new table to get the element (the node on the migrated slot is the ForwardingNode, and the forwardingNode is used to query the new table), and the put request helps the migration
size method
The idea of counting and getting the total is similar to that of LongAdder, see my LongAdder article
The difference between ConcurrentHashMap1.7 and 1.8
low-level implementation
The implementation of jdk1.7 is an array + linked list . When a hash conflict occurs, the zipper method is used, that is, a linked list. The complexity of searching on the linked list is O(n)
The implementation of jdk1.8 is array + linked list + red-black tree . When a hash conflict occurs, the zipper method is also used,
but when the length of the linked list is greater than 8, the linked list is converted into a red-black tree, and the efficiency of searching on the red-black tree is is O(log(n))
Thread-safe implementation
jdk1.7 ensures thread safety based on Segment segment lock + Unsafe
jdk1.8 guarantees thread safety based on synchronized + CAS + Unsafe
Concurrency
In jdk1.7, each segment is locked independently, and the maximum concurrency that can be supported is the length of the segment array
The granularity of locks in jdk1.8 has become finer, the maximum concurrency that can be supported is the length of the table array, and the concurrency is improved compared to 1.7
Get the total number of elements
jdk1.7 ensures that the total number of elements acquired is accurate by locking
The total number of elements in jdk1.8 is calculated by accumulating the values of baseCount and cell arrays. There will be concurrency problems, and the final value may be inaccurate (similar to the counting idea of LongAdder)
Reference blog
[1]https://blog.csdn.net/zzu_seu/article/details/106698150