Hello everyone, my name is Xiaolin.
Let's talk about MySQL's Buffer Pool today, let's go!
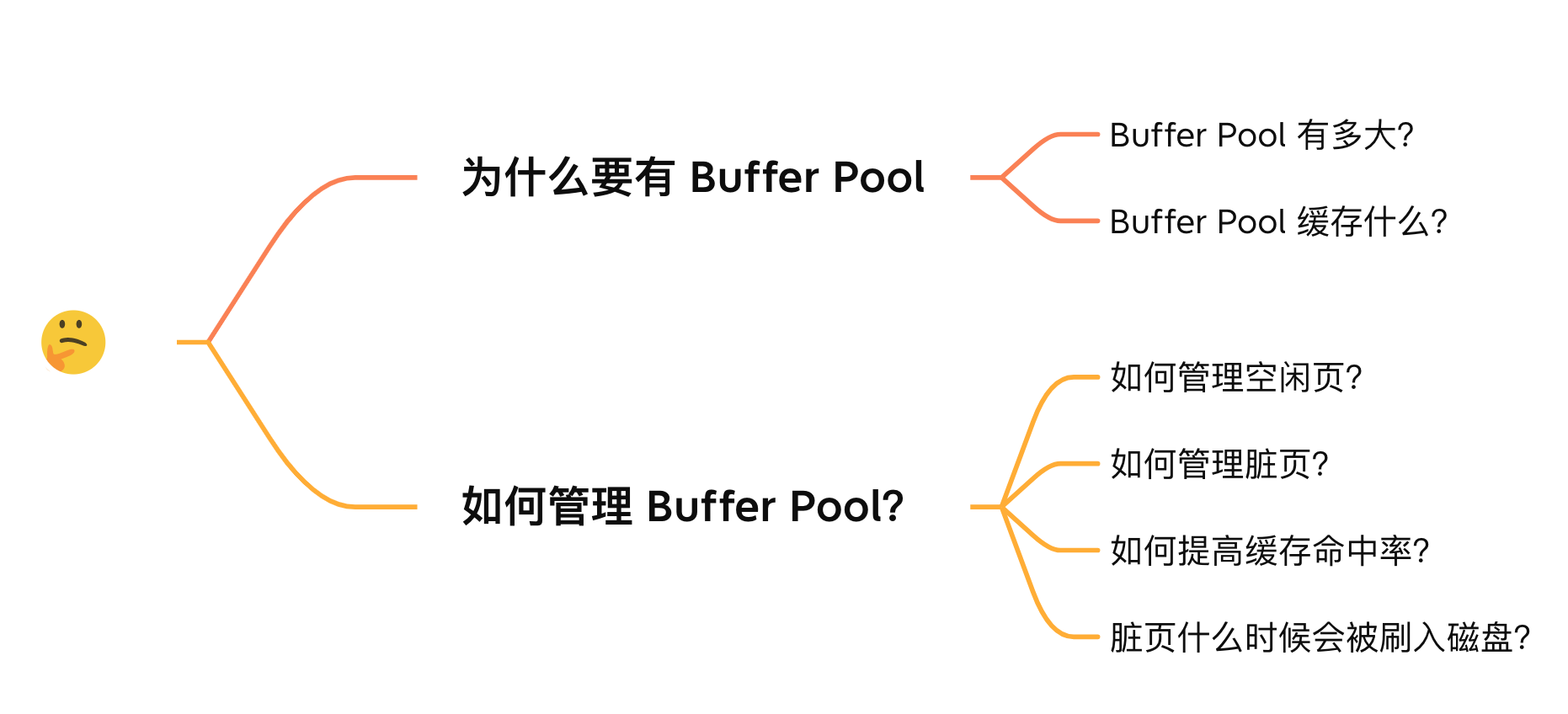
Why have Buffer Pool?
Although MySQL data is stored in the disk, it cannot read the data from the disk every time, so the performance is extremely poor.
To improve query performance, add a cache. Therefore, when the data is fetched from the disk, it is cached in the memory, and the next time the same data is queried, it is directly read from the memory.
To this end, the Innodb storage engine has designed a buffer pool ( Buffer Pool ) to improve the read and write performance of the database.

With the buffer pool:
- When reading data, if the data exists in the Buffer Pool, the client will directly read the data in the Buffer Pool, otherwise it will go to the disk to read.
- When modifying data, first modify the page where the data in the Buffer Pool is located, then set its page as a dirty page, and finally write the dirty page to the disk by the background thread.
How big is the Buffer Pool?
Buffer Pool is a piece of contiguous memory space applied to the operating system when MySQL starts up. By default, there is only Buffer Pool 128MB.
You can set the size of the Buffer Pool by adjusting the innodb_buffer_pool_sizeparameters . Generally, it is recommended to set it to 60%~80% of the available physical memory.
What does the Buffer Pool cache?
InnoDB divides the stored data into several "pages", and uses a page as the basic unit of interaction between disk and memory. The default size of a page is 16KB. Therefore, the Buffer Pool also needs to be divided into "pages".
When MySQL starts, InnoDB will apply for a continuous memory space for the Buffer Pool, and then 16KBdivide pages one by one according to the default size. The pages in the Buffer Pool are called cache pages . At this time, these cache pages are all free, and as the program runs, the pages on the disk will be cached in the Buffer Pool.
Therefore, when MySQL first starts, you will observe that the virtual memory space used is very large, but the physical memory space used is very small. This is because the operating system will trigger a page fault interrupt only after the virtual memory is accessed. , and then establish a mapping relationship between virtual addresses and physical addresses.
In addition to caching "index pages" and "data pages", the Buffer Pool also includes undo pages, insert caches, adaptive hash indexes, lock information, and more.

In order to better manage these cache pages in the Buffer Pool, InnoDB creates a control block for each cache page , and the control block information includes "table space of cache page, page number, cache page address, linked list node", etc. .
The control block also occupies memory space. It is placed at the front of the Buffer Pool, followed by the cache page, as shown below:

The gray area between the control block and the cache page in the above figure is called the fragmentation space.
Why is there fragmentation space?
Think about it, each control block corresponds to a cache page. After allocating enough control blocks and cache pages, the remaining space may not be enough for the size of a pair of control blocks and cache pages. After that, the unused memory space is called fragmentation.
Of course, if you set the size of the Buffer Pool just right, fragmentation may not occur.
Do you only need to buffer one record to query a record?
no.
When we query a record, InnoDB will load the data of the entire page into the Buffer Pool, because the index can only locate the page on the disk, but cannot locate a record in the page. After loading the page into the Buffer Pool, locate a specific record through the page directory in the page.
Questions about what the page structure looks like and how the index queries data can be found in this article: Looking at the B+ tree from a different angle
How to manage Buffer Pool?
How to manage free pages?
Buffer Pool is a continuous memory space. When MySQL runs for a period of time, the cache pages in this continuous memory space are both free and used.
Then when we read data from disk, we can't find free cache pages by traversing this continuous memory space, which is too inefficient.
Therefore, in order to quickly find a free cache page, a linked list structure can be used, and the "control block" of the free cache page is used as the node of the linked list. This linked list is called the Free linked list (free linked list).

In addition to the control block on the Free linked list, there is also a head node, which contains the address of the head node of the linked list, the address of the tail node, and the number of nodes in the current linked list.
Free linked list nodes are control blocks one by one, and each control block contains the address of the corresponding cache page, so equivalent Free linked list nodes correspond to a free cache page.
With the Free linked list, whenever a page needs to be loaded from the disk into the Buffer Pool, a free cache page is taken from the Free linked list, and the information of the control block corresponding to the cache page is filled in, and then the The control block corresponding to the cached page is removed from the Free list.
How to manage dirty pages?
Designing Buffer Pool can not only improve read performance, but also improve write performance, that is, when updating data, it is not necessary to write to disk every time, but the cache page corresponding to the Buffer Pool is marked as dirty page , and then the background Thread writes dirty pages to disk.
In order to quickly know which cache pages are dirty, the Flush linked list is designed . It is similar to the Free linked list. The nodes of the linked list are also control blocks. The difference is that the elements of the Flush linked list are dirty pages.
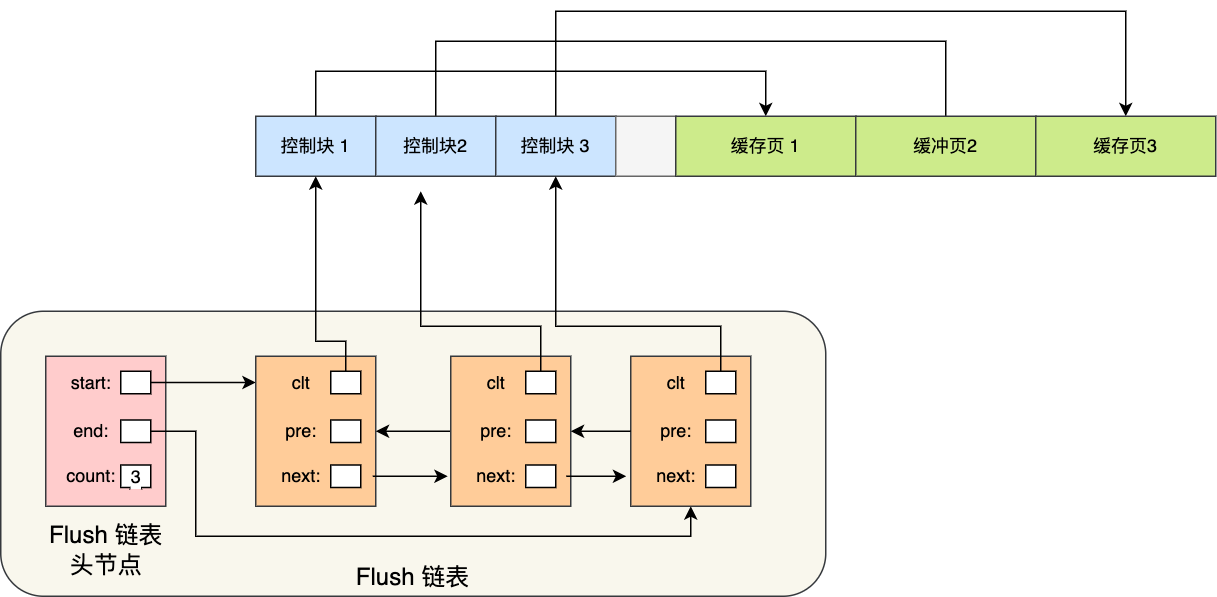
With the Flush linked list, the background thread can traverse the Flush linked list and write dirty pages to disk.
How to improve cache hit rate?
The size of the Buffer Pool is limited. For some frequently accessed data, we hope to stay in the Buffer Pool all the time, while some rarely accessed data hope to be eliminated at certain times, so as to ensure that the Buffer Pool will not be full because of As a result, new data can no longer be cached, and at the same time, frequently used data can be guaranteed to remain in the Buffer Pool.
To achieve this, the easiest to think of is the LRU (Least recently used) algorithm.
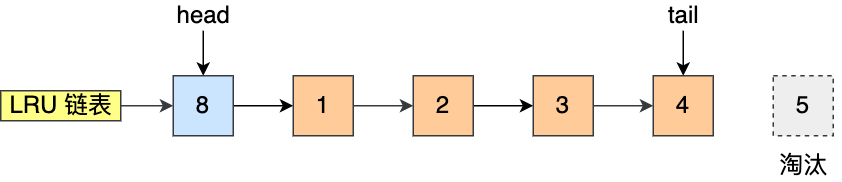
The idea of this algorithm is that the nodes at the head of the linked list are the most recently used, and the nodes at the end of the linked list are the ones that have not been used for the longest time. Then, when the space is not enough, the node that has not been used for the longest time is eliminated to make room.
The implementation idea of the simple LRU algorithm is as follows:
- When the accessed page is in the Buffer Pool, directly move the LRU linked list node corresponding to the page to the head of the linked list.
- When the accessed page is not in the Buffer Pool, in addition to putting the page at the head of the LRU linked list, the node at the end of the LRU linked list should also be eliminated.
For example, in the figure below, suppose the length of the LRU linked list is 5, and the LRU linked list has pages 1, 2, 3, 4, and 5 from left to right.

If page 3 is accessed, because page 3 is in the Buffer Pool, just move page 3 to the head.

If next, page 8 is accessed, because page 8 is not in the Buffer Pool, so you need to eliminate page 5 at the end first, and then add page 8 to the header.
Here we can know that there are three types of pages and linked lists in the Buffer Pool to manage data.

In the picture:
- Free Page (free page), which means that this page is not used and is located in the Free linked list;
- Clean Page (clean page), indicating that this page has been used, but the page has not been modified, located in the LRU linked list.
- Dirty Page (dirty page), which means that this page is "used" and "modified", and its data is inconsistent with the data on the disk. When the data on the dirty page is written to the disk, the memory data is consistent with the disk data, then the page becomes a clean page. Dirty pages exist in both the LRU linked list and the Flush linked list.
Simple LRU algorithm is not used by MySQL, because simple LRU algorithm cannot avoid the following two problems:
- pre-reading failure;
- Buffer Pool pollution;
What is read ahead invalidation?
Let's talk about MySQL's read-ahead mechanism first. The program has spatial locality, and the data close to the currently accessed data will be accessed with a high probability in the future.
Therefore, when MySQL loads a data page, it will load its adjacent data pages together in advance, in order to reduce disk IO.
However, it is possible that the data pages loaded in advance have not been accessed , which means that the pre-reading is done in vain, and this is the pre-reading failure .
If a simple LRU algorithm is used, the pre-read pages will be placed at the head of the LRU linked list, and when the buffer pool space is not enough, the pages at the end need to be eliminated.
If these pre-read pages are never accessed, there will be a very strange problem. The pre-read pages that will not be accessed occupy the front row of the LRU list, and the pages that are eliminated at the end may be frequently accessed. pages, which greatly reduces the cache hit rate.
How to solve the problem of cache hit rate reduction caused by read-ahead invalidation?
We cannot remove the pre-reading mechanism because we are afraid of the failure of pre-reading. In most cases, the locality principle still holds.
To avoid the impact of pre-reading failure, it is best to keep the pre-read pages in the Buffer Pool for as short a time as possible, so that the pages that are actually accessed are moved to the head of the LRU linked list to ensure that they are actually read. The fetched hot data stays in the Buffer Pool for as long as possible .
So how can it be avoided?
MySQL does this by improving the LRU algorithm and dividing the LRU into 2 areas: the old area and the young area .
The young area is in the first half of the LRU list, and the old area is in the second half, as shown below:
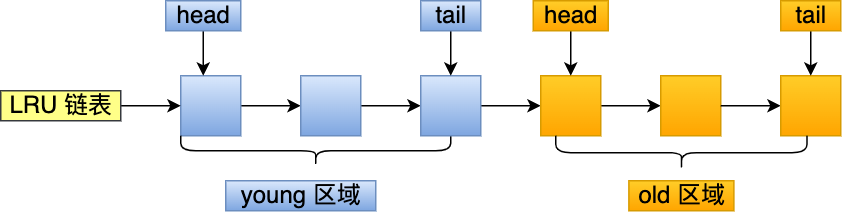
The ratio of the old area to the length of the entire LRU linked list can be set by the innodb_old_blocks_pcparameter , the default is 37, which means that the ratio of the young area to the old area in the entire LRU linked list is 63:37.
After dividing these two areas, the pre-read page only needs to be added to the head of the old area, and when the page is actually accessed, the page is inserted into the head of the young area . If the prefetched page has not been accessed, it will be removed from the old area, so that it will not affect the hot data in the young area.
Next, give you an example.
Suppose there is an LRU linked list of length 10, in which the young area accounts for 70% and the old area accounts for 20%.

Now a page number 20 has been read ahead, this page will only be inserted at the head of the old area, and the page at the end of the old area (number 10) will be eliminated.

If page 20 is never accessed, it doesn't occupy the young area, and it will be eliminated earlier than the data in the young area.
If page 20 is accessed immediately after being pre-read, it will be inserted into the head of the young area, and the page at the end of the young area (No. 7) will be squeezed into the old area as the head of the old area , no pages are eliminated during this process.

Although the impact of read-ahead failure is avoided by dividing the old area and the young area, there is still a problem that cannot be solved, that is, the problem of Buffer Pool pollution.
What is Buffer Pool pollution?
When a certain SQL statement scans a large amount of data , all the pages in the Buffer Pool may be replaced when the space of the Buffer Pool is relatively limited , resulting in the elimination of a large amount of hot data , and the hot data will be used again. When accessing, due to cache misses, a large amount of disk IO will be generated, and MySQL performance will drop sharply. This process is called Buffer Pool pollution .
Note that Buffer Pool pollution is not only a problem that occurs when a large amount of data is queried by the query statement. Even if the result set obtained from the query is small, it will cause Buffer Pool pollution.
For example, in a table with a very large amount of data, execute this statement:
select * from t_user where name like "%xiaolin%";
It may be that the result of this query is only a few records, but because the index will fail in this statement, the query process is a full table scan, and then the following process will occur:
- The page read from the disk is added to the head of the old area of the LRU linked list;
- When a row record is read from a page, that is, when the page is accessed, the page should be placed in the header of the young area;
- Next, perform fuzzy matching between the name field of the row record and the string xiaolin, and add it to the result set if it meets the conditions;
- This goes back and forth until all records in the table are scanned.
After some tossing, the hotspot data in the original young area will be replaced.
For example, suppose you need to scan in batches: 21, 22, 23, 24, 25 these five pages, these pages will be accessed one by one (read the records in the page).
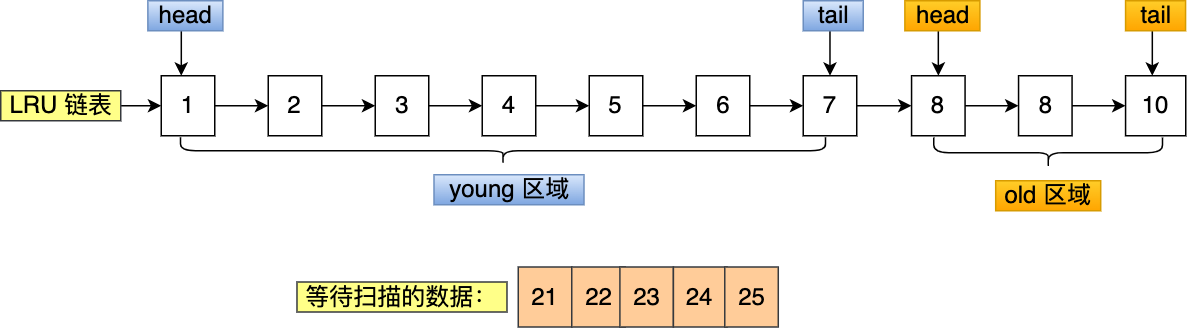
When accessing these data in batches, they will be inserted into the head of the young area one by one.

It can be seen that the hot data pages 6 and 7 originally in the young area have been eliminated, which is the problem of Buffer Pool pollution.
How to solve the problem that the cache hit rate drops due to Buffer Pool pollution?
For a full table scan query like the previous one, many buffer pages are actually accessed only once, but they enter the young area only because they are accessed once, resulting in the replacement of hot data.
The young area in the LRU list is the hotspot data. As long as we raise the threshold for entering the young area, we can effectively ensure that the hotspot data in the young area will not be replaced.
This is what MySQL does. Entering the young area condition adds a time judgment to stay in the old area .
Specifically, when a cache page in the old area is accessed for the first time, the access time is recorded in its corresponding control block:
- If the subsequent access time and the first access time are within a certain time interval , then the cache page will not be moved from the old area to the head of the young area ;
- If the subsequent access time is not within a certain time interval from the first access time , the cached page is moved to the head of the young area ;
This interval is innodb_old_blocks_timecontrolled by and defaults to 1000 ms.
That is to say, only if the two conditions of "visited" and "staying in the old area for more than 1 second" are met at the same time, it will be inserted into the head of the young area , which solves the problem of Buffer Pool pollution.
In addition, MySQL has actually made an optimization for the young area, in order to prevent the young area node from moving to the head frequently. The first 1/4 of the young area is accessed and will not move to the head of the linked list, only the latter 3/4 will be accessed.
When will dirty pages be flushed to disk?
After the introduction of Buffer Pool, when modifying data, first modify the page where the data in the Buffer Pool is located, and then set its page as a dirty page, but the original data is still in the disk.
Therefore, dirty pages need to be flushed to the disk to ensure that the cache and disk data are consistent. However, if the data is flushed to the disk every time the data is modified, the performance will be poor, so the disk is generally flushed in batches at a certain time.
Maybe everyone is worried that if MySQL goes down before the dirty pages have time to be flushed to the disk, won't data be lost?
Don't worry about this, InnoDB's update operation adopts the Write Ahead Log strategy, that is, the log is written first, and then written to the disk, and MySQL has the crash recovery capability through the redo log log.
The following situations will trigger the refresh of dirty pages:
- When the redo log is full, it will actively trigger the flushing of dirty pages to disk;
- When the buffer pool space is insufficient, some data pages need to be eliminated. If the dirty pages are eliminated, the dirty pages need to be synchronized to the disk first;
- When MySQL thinks it is idle, the background thread periodically flushes an appropriate amount of dirty pages to the disk;
- Before MySQL shuts down normally, all dirty pages are flushed to disk;
After we turn on slow SQL monitoring, if you find that **occasionally” there will be some SQL that takes a little longer**, this may be because dirty pages may bring performance overhead to the database when they are flushed to disk, causing the database to Operation jitters.
If this phenomenon occurs intermittently, it is necessary to increase the Buffer Pool space or the size of the redo log log.
Summarize
Innodb storage engine designs a buffer pool ( Buffer Pool ) to improve the read and write performance of the database.
Buffer Pool buffers data in page units. You can adjust the size of the buffer pool through the innodb_buffer_pool_sizeparameter . The default is 128 M.
Innodb manages cache pages through three linked lists:
- Free List (free page linked list), manages free pages;
- Flush List (dirty page linked list), manage dirty pages;
- LRU List, manages dirty pages + clean pages, caches recent and frequently queried data in it, and eliminates infrequently queried data. ;
InnoDB has made some optimizations to LRU. The LRU algorithm we are familiar with usually puts the most recently queried data at the head of the LRU linked list, while InnoDB does two optimizations:
- The LRU linked list is divided into two areas, young and old . Pages added to the buffer pool are inserted into the old area first; when the page is accessed, it enters the young area, in order to solve the problem of read-ahead failure.
- When the "page is accessed" and the "old area stay time exceeds the
innodb_old_blocks_timethreshold (default is 1 second)", the page will be inserted into the young area, otherwise it will be inserted into the old area, the purpose is to solve batch data access, a large amount of hot data elimination issue.
You can set the proportion of young area and old area by adjusting the innodb_old_blocks_pcparameters .
After enabling slow SQL monitoring, if you find that "occasionally" some SQL that takes a little longer appears, this may be due to database performance jitter when dirty pages are flushed to disk. If this phenomenon occurs in a short period of time, it is necessary to increase the buffer pool space or the size of the redo log log.