Use AI to host mass-produced original Korean girl groups playing songs and mixing videos on the spot? That's right.
At present, many self-media accounts are posting mixed videos of Korean girl groups. On the one hand, the audience is girls who love beauty, and they enjoy seeing beauty. On the other hand, otaku and LSPs have the same feeling of watching Korean girl groups as watching island romance movies.
I have watched so many mixed-cut videos and found that they can be directly merged with algorithms, and combined with Python's Moviepy module, the mixed-cut video can be automatically generated, and the generated mixed-cut video is relatively random (of course, it is absolutely original) , the efficiency is also very high (one out of 10 minutes).

I experimented with T-ara's "Day By Day" live sing-along video and it worked. Although there are still some places where the fit is not perfect, the corresponding algorithm will be updated in subsequent versions to achieve perfection.
The current version is version 1.0 with limited functions, and the script will continue to be updated based on the updated algorithm in the future. Here are the general production ideas and methods and the original questions you want to ask.
Since no one cares about serious technical skills, let's try it out with such a number.
Software, hardware and skill requirements
- The best CPU is I7-8750 or above, otherwise the overall production will be very slow
- Python version 3.6 and above
- The Moviepy module does not support GPU temporarily, so the graphics card is ignored
- You need to be able to write crawlers and capture video materials.
- You need to master the regular article washing methods, otherwise the video content cannot be done
- It is necessary to master the normal operation of the window system, otherwise some operations cannot be completed.
- You need to be able to operate the Moviepy module, but if you don't, see the corresponding introduction and operation methods in my column
- 1-N mobile phone numbers are required to apply for Baidu AI's free API usage
- need patience
data collection
If the data is obtained, go to a certain tube to download it directly, eliminating the need to remove the watermark, and many films are of high quality, 1080P and 2, 3, and 4K are very common.
Basic material preparation
This is relatively simple for the previous "Monthly Production of 10,000 Chinese Medicine Popular Science Short Video Methods, Python Programming AI Tutorial".
A watermark is enough. After all, people are here to listen to songs and watch girls. Adding too much mess will affect the effect.
process and code
Knowing the business process production process helps to understand the code, or the process understands the code and it's easy.
First look at the overall project directory, and then step by step.
Basic data application part
import os
from moviepy.editor import *
import time
import re
import pandas as pd
import json
import random
import glob
# 字符串时、分、秒转换成秒函数
def str2sec(x):
h, m, s = x.strip().split(':')
return int(h)*3600 + int(m)*60 + int(s)
# 字符串时、分、秒、毫秒转换成秒函数
def str2sec_(x):
if x != "-":
h, m, s = x.strip().split(':')
return str(int(h)*3600 + int(m)*60 + int(s))
else:
return x
# 避免出错生成新的拼接素材清空前面的内容
path = "temp_video/"
for infile in glob.glob(os.path.join(path, '*.mp4')):
os.remove(infile)
# 将所有需要剪辑放到 source_video 文件夹下
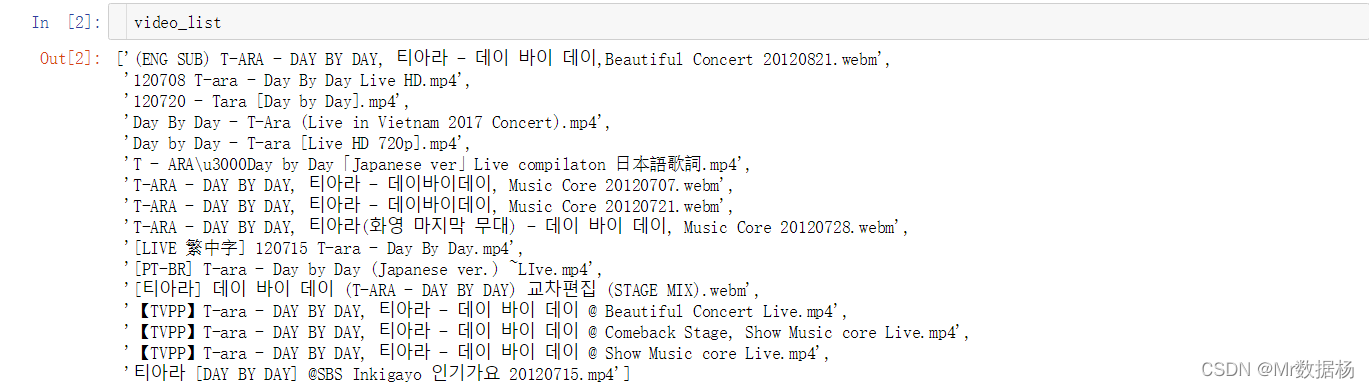
video_list = os.listdir("source_video/")
video_list = [i for i in video_list if 'txt' not in i]
video_list = [i for i in video_list if 'xlsx' not in i]
Algorithm Automation Integration Algorithm
Omit it here, use the waveform algorithm of sound to synchronize all videos to a timeline, find a basic base_video (as you will see later, that is the main video), and other material videos will match the timeline to the timeline according to the audio waveform algorithm On, automatic acceleration (the overall video time of the material < base_video video time) or automatic deceleration (the overall video time of the material > base_video video time) operation.
# video_base 基础时间线视频
video_base = random.choice(video_list)
# 在原有的 video_list 剔除 video_base
video_list.remove(video_base)
# 按照 video_base 的时间统一处理其他视频,将时间进行对等
base_duration = locals()[video_base].duration
for each in video_list:
# 计算每个视频的时长
each_duration = locals()[each].duration
# 倍速播放倍数,视频时间/音频时间就是视频加速的时间
factor = each_duration/base_duration
# 倍速播放持续时间 ,可以为空表使全部
final_duration = None
locals()[each] = locals()[each].fx(vfx.speedx,factor,final_duration)
Loop to create variables, crop, reset resolution
num_list = list(range(len(data_list)))
video_dict = data_list.to_dict('records')
# 构建变量名称,调用使用 locals()[xxxx]方法
video_list = []
for num,data in zip(num_list,video_dict):
locals()["video_temp_"+str(num)] = VideoFileClip("source_video/"+ data["file_name"])
# 对裁剪视频进行简介操作
# 统一分辨率
locals()["video_temp_"+str(num)] = locals()["video_temp_"+str(num)].resize((1920, 1080))
# 按照字典的起止时间裁剪
start_time = 0 if data["start"] == "-" else data["start"]
end_time = locals()["video_temp_"+str(num)].duration if data["end"] == "-" else data["end"]
# 视频按照裁剪时间重新定义变量
locals()["video_temp_"+str(num)] = locals()["video_temp_"+str(num)].subclip(start_time,end_time)
video_list.append("video_temp_"+str(num))
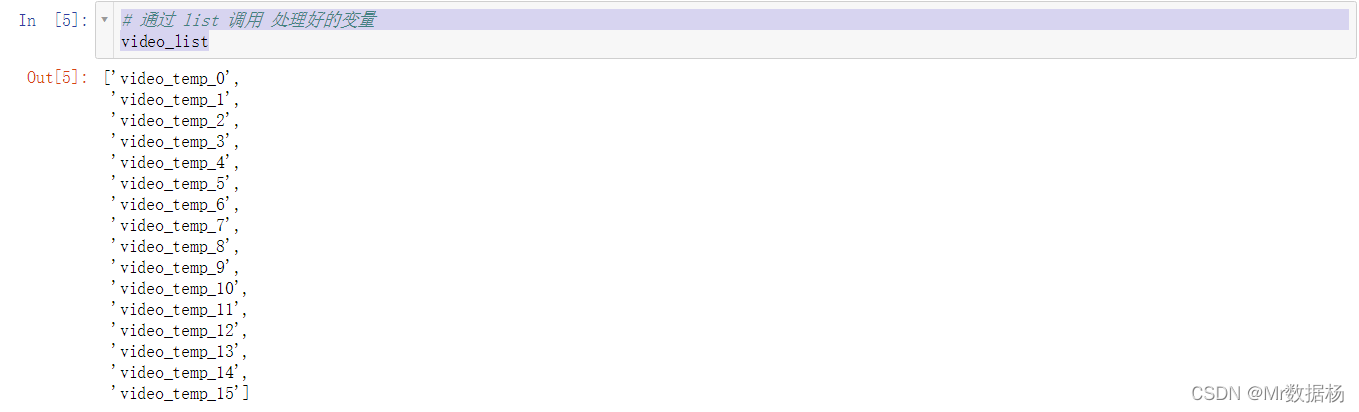
# 通过 list 调用 处理好的变量
video_list
Start cropping randomly
time_ = 0
start_time = 0
time_list = [0]
# 判断时间永远小于要做的视频
while time_ <= stop_time:
# 视频随机切割点
cut_time = random.randint(5,15)
start_time = start_time + cut_time
time_list.append(start_time)
# 最终计算变量
time_ = time_ + cut_time
# 剔除超出的部分时间
time_list = time_list[:-2]
# 时间两两组合成需要拆的部分视频
time_list = [time_list[i:i+2] for i in range(0, len(time_list), 1)]
# 为最后一个元素添加 结束时间 stop_time
time_list[-1] = [time_list[-1][0],stop_time]
# 将之前剔除的视频重新添加回来
video_list.append(video_base)
# 将所有片段进行拆分
n = 1
for time_ in time_list:
# cut_video 是视频名称 使用 locals()[cut_video] 调用
cut_video = locals()[random.choice(video_list)]
cut_video = cut_video.subclip(time_[0],time_[1])
# 静音操作
cut_video = cut_video.fx(afx.volumex, 0)
cut_video = cut_video.write_videofile("temp_video/{}.mp4".format(n))
n = n + 1

video synthesis
# 对文件进行数字排序避免 1 10 23456789的情况发生顺序错误
each_dir = "temp_video/"
cut_list = sorted(os.listdir(each_dir),key = lambda i:int(re.match(r'(\d+)',i).group()))
# 视频合成 cvc_video
L = []
for i in cut_list:
cut_video = VideoFileClip("temp_video/" + i)
L.append(cut_video)
cvc_video = concatenate_videoclips(L)
# 视频中添加水印
logo = (
ImageClip("./base_data/水印1.png")
.set_duration(cut_video.duration) # 水印持续时间
.resize(height=200) # 水印的高度,会等比缩放
.set_pos(("left", "top")) # 水印的位置
)
# 文件进行保存到结果文件中
cvc = CompositeVideoClip([cvc_video,logo])
# 视频和音频合成在一起
audio = AudioFileClip('temp_data/audio.mp3')
video_result = cvc.set_audio(audio)
video_result.write_videofile("{}.mp4".format(str(int(time.time()))))

Different versions of the finished product generated according to the timestamp