一.作者思路
作者是为了增强使用推荐系统的鲁棒性并以矩阵分解为例,一般增强鲁棒性的方式有adversarial training,它的原理是在模型参数上添加干扰来训练达到增加推荐系统鲁棒性的目的,但是adversarial training有一定的缺陷(在参数上加干扰不太现实),所以作者反其道行之,在adversarial training上使用“正向”干扰来增加推荐系统的鲁棒性。
故逐一介绍以下三个方面的内容:
- 推荐系统的矩阵分解相关内容;
- adversarial training
- adversarial poisoning training (APT)
1.使用矩阵分解的推荐系统
arg min U , V ∑ ( i , j ) ∈ Ω ( r i , j − U i V j T ) 2 + λ ( ∥ U ∥ F 2 + ∥ V ∥ F 2 ) (1) \arg \min_{U,V} \sum_{(i,j)\in \Omega}(r_{i,j}-U_iV_j^{\mathrm{T}})^2+\lambda(\|U\|_F^2+\|V\|_F^2) \tag 1 argU,Vmin(i,j)∈Ω∑(ri,j−UiVjT)2+λ(∥U∥F2+∥V∥F2)(1)
2.adversarial training
min θ R max Δ , ∥ Δ ∥ ≤ ϵ ( L ( D , θ R ) + λ a d v L ( D , θ R + Δ ) ) (2) \min_{\theta_R} \max_{\Delta,\|\Delta\|\leq\epsilon}(L(D,\theta_R)+\lambda_{\mathrm{adv}}L(D,\theta_R+\Delta)) \tag2 θRminΔ,∥Δ∥≤ϵmax(L(D,θR)+λadvL(D,θR+Δ))(2)
理解:当 θ R \theta_R θR固定后,在小于 ϵ \epsilon ϵ的范围内找一个干扰 Δ \Delta Δ使得添加干扰后的loss最大,然后固定干扰,重新训练 θ R \theta_R θR.经过这样的训练,使得推荐系统适应噪声来增加其鲁棒性.
缺陷:攻击方在评分和参数上动手脚比较不现实,所以不能反应真实攻击的效果.
3.APT
基于adversarial training的思想,换一种思路:攻击者可以制作有害的用户来最大化推荐系统的误差,那防卫者可以制作正向的用户最小化误差来增强推荐系统的鲁棒性.
min θ R min D ∗ , ∣ D ∗ ∣ = n ∗ L ( D ∪ D ∗ , θ R ) (3) \min_{\theta_R} \min_{D^*,|D^*|=n^*}L(D \cup D^*,\theta_R) \tag 3 θRminD∗,∣D∗∣=n∗minL(D∪D∗,θR)(3)
note: D ∗ D^* D∗为制作的正向用户(又称EMR用户),个数为 n ∗ n^* n∗个.
那么有以下几个问题:
- 如何产生EMR用户,产生的原则是什么?
- 如何挑选EMR用户?
- 如何对挑选的EMR用户的item打分?
3.1 寻找EMR用户
选取原则:评估每一个用户在经验风险的影响来产生EMR用户;
影响可以用影响函数衡量:
I p e r t , l o s s ( z , z t e s t ) = − 1 n ∇ θ L ( z t e s t , θ ^ ) T H θ ^ − 1 ∇ z ∇ θ L ( z , θ ^ ) δ (4) I_{\mathrm{pert,loss}}(z,z_{\mathrm{test}})=-\frac{1}{n}\nabla_{\theta}L(z_{\mathrm{test}},\hat \theta)^{\mathrm{T}}\mathbf{H}_{\hat \theta}^{-1}\nabla_z \nabla_{\theta }L(z,\hat \theta)\delta \tag 4 Ipert,loss(z,ztest)=−n1∇θL(ztest,θ^)THθ^−1∇z∇θL(z,θ^)δ(4)
( 4 ) (4) (4)式代表了对训练集某点 z z z添加扰动 δ \delta δ,对测试集的某点 z t e s t z_{\mathrm{test}} ztest的影响;
对于 ( 4 ) (4) (4)式由来理解,附上自己的个人理解:https://blog.csdn.net/qq_16600319/article/details/121436462
根据需求,将 ( 4 ) (4) (4)式相应的部分进行更改: L ( z t e s t , θ ^ ) = L E R ( θ ^ R ) L(z_{\mathrm{test}},\hat \theta)=L_{ER}(\hat \theta_R) L(ztest,θ^)=LER(θ^R)
故第 ( 4 ) (4) (4)式为:
I p e r t , l o s s ( z , z t e s t ) = − 1 n ∇ θ L E R ( θ ^ R ) T H θ ^ R − 1 ∇ z ∇ θ R L ( z , θ ^ R ) (5) I_{\mathrm{pert,loss}}(z,z_{\mathrm{test}})=-\frac{1}{n}\nabla_{\theta}L_{ER}(\hat \theta_R)^{\mathrm{T}}\mathbf{H}_{\hat \theta_R}^{-1}\nabla_z \nabla_{\theta_R}L(z,\hat \theta_R) \tag 5 Ipert,loss(z,ztest)=−n1∇θLER(θ^R)THθ^R−1∇z∇θRL(z,θ^R)(5)
未完待续…
附录
1.关于机器学习
问题1:什么是empirical risk?
训练集上的期望损失: R e m p = 1 N ∑ i = 1 n L ( y ^ , y ) R_{emp}=\frac{1}{N} \sum_{i=1}^{n}L(\hat{y},y) Remp=N1∑i=1nL(y^,y),是由于使用的数据集只是现实世界数据的一部分,所以训练出来存在一定的误差?是这么理解的吗?
2.关于矩阵分解
问题2:为什么矩阵分解的 U V T \mathbf{U}\mathbf{V}^{\mathrm{T}} UVT,后面那个要是个转置?不能分解为两个不需要转置的矩阵相乘吗?有何意义?
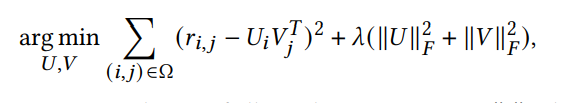
问题3:老师说,矩阵分解的latent factor一般取2、3,如果推荐系统使用的矩阵分解为满秩分解,如果latent factor取3,岂不是默认user-item矩阵的秩为3?如何更加精确的找到latent factor,而不是靠人为设置呢?个人想法:user-item矩阵不像数学书上的矩阵一样,每一个数据都是精心设计的,也就是说,user-item的数据存在着误差,而且数据量很大,从这样一个不精确的数据大矩阵中找到它的秩是一件非常困难的事,就像有许许多多的方程,一个方程的系数稍微有一点变化就产生了另外一个方程,如何将这样的方程归类为同一个呢?如果得到了这样一个精简的矩阵,是否能直接采用理论上的矩阵满秩分解而不需要默认设置latent factor?
问题4:根据自己上课得知,矩阵分解存在满秩分解、奇异值分解、极分解、谱分解、正交三角分解等,为什么要用满秩分解,而不是其他的分解?它们是分解场景有所不同吗?矩阵分解实际应用背景又是什么呢?