本次Hive使用Hive3.1.2。
本次规划为三台虚拟机结点,其中在hp301上安装mysql和hive。
| 主机名 | IP地址 | |
|---|---|---|
| hp301 | 192.168.150.31 | mysql/hive |
| hp302 | 192.168.150.32 | |
| hp303 | 192.168.150.33 |
使用Hive需要用到的环境是Hadoop,本次使用的是Hadoop3.3.1,其安装、使用过程详见本博客Hadoop3系列:Hadoop3详细教程
使用Hive需要在Linux虚拟机上安装Mysql,安装过程详见,本博客关于在Linux上安装和卸载MySQL的连接:Linux下MySQL安装与卸载
完成以上操作后,我们可以进行Hive的安装。
以下为详细安装步骤:
1.下载apache-hive-3.1.2-bin.tar.gz上传到hp301 /apps下。
2.解压至/usr/local下
tar -zxvf /apps/apache-hive-3.1.2-bin.tar.gz -C /usr/local
3.为方便后续使用,对其创建一个软连接:
ln -s /usr/local/apache-hive-3.1.2-bin/ /usr/local/hive3
4.配置Hive的环境变量:
在/etc/profile.d下新建一个hive.sh
vi/etc/profile.d/hive.sh
在其中书写以下代码:
export HIVE_HOME=/usr/local/hive3
export PATH=$PATH:$HIVE_HOME/bin
使用source命令,使环境变量生效:
source /etc/profile.d/hive.sh
6.修改配置文件
将/usr/local/hive3/conf/hive-env.sh.template改名为hive-env.sh
并在后面追加:
export JAVA_HOME=$JAVA_HOME
export HADOOP_HOME=$HADOOP_HOME
export HIVE_HOME=$HIVE_HOME
新建一个hive-site.xml,里面填写:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!--规划mysql中存储元数据的数据库名为metastore,当初始化数据时不存在时自动创建-->
<value>jdbc:mysql://hp301:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- jdbc Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--数据库用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--数据库密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Hive123+</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
7.添加Java访问MySQL的jar包
下载mysql-connector-java-5.1.47-bin.jar并上传到linux服务器,然后将其复制到/usr/local/hive3/lib下
8.初始化Hive数据库,执行命令:
schematool -initSchema -dbType mysql
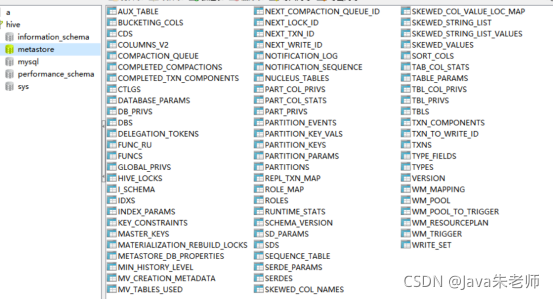
此时使用navicat查看hp301的数据库,会发现多了一个metastrore的数据库,库中所有的表即使Hive存放元数据的表结构:
9.使用Hive
启动hadoop
start-all.sh
hadoop成功启动之后,可以启动hive客户端:
hive
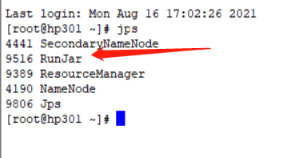
如图所示的命令行效果:

可以通过另一个连接查看进程,Hive实际上就是一个RunJar进程: