如有错误,恳请指出。
文章目录
paper:Training data-efficient image transformers & distillation through attention

摘要:
纯基于注意力的神经网络被证明可以解决图像分类等图像理解任务,但是这些高性能的网络结构通常需要使用大型的基础设施预先训练了数亿个图像,因此限制了他们的采用。
为此,对于这种设计庞大的预训练量,作者提出了一种convolution-free transformers的结构,其只在Imagenet上进行训练,就具有竞争力。在不需要其他额外数据进行预训练的情况下,在ImageNet上达到了top-1 accuracy of 83.1%的效果。
此外,作者还引入了师生策略,依赖于一个蒸馏标记(distillation token),确保学生通过注意力从老师那里学习。当卷积网络作为教室时,效果达到了85.2%的准确率。
1. Introduction
Vit模型取得了巨大的成功,然而其结论是,transformers在数据量不足的情况下不能很好地概括,这些模型的训练涉及大量的计算资源。
为此作者将Imagenet作为唯一的训练集,在2 - 3天(53小时的预训练和可选的20小时微调)内在单个8-GPU节点上训练一个视觉transformers,将其称为:DeiT(Data-efficient image Transformers)
作者还介绍了一种基于token的策略,专门用于transformers,用DeiT⚗表示,并表明它可以有效地取代通常的蒸馏。
主要贡献:
1)DeiT不包含卷积层,可以在没有外部数据的情况下实现与ImageNet上的最新技术相媲美的结果。
2)引入了一种基于distillation token的新蒸馏过程,它扮演着与class token相同的角色,只不过它的目的是再现教师估计的标签,两个标记都通过注意力在转换器中交互。
3)通过蒸馏,图像transformers从一个convnet学到的比从另一个性能相当的transformers学到的更多。
4)在Imagenet上预先学习的模型在转移到不同的下游任务时是有竞争力的,比如细粒度分类,在几个流行的公共基准测试中:CIFAR-10、CIFAR-100、Oxford-102 flowers、Stanford Cars、iNaturalist-18/19
2. Related work
之前没有怎么接触过蒸馏的概念,利用这一章简要记录一下。
知识蒸馏指的是学生模式利用来自强大教师网络的“软”标签的训练范式。这是来至老师网络的softmax函数的输出向量,而不仅仅是给出了一个“hard”标签的分数最大值。也就说,一般训练一个网络是利用真实标签这种硬标签来训练参数,而现在通过将训练好的教师网络的输出值作为学生网络的训练标签,这是一种软标签的形式。这样的训练可以提高学生模型的性能(或者,它可以被看作是将教师模型压缩为更小的模型——学生模型。
一方面,教师的软标签会有类似于平滑标签的效果,而平滑的标签不仅仅可以让学生网络学习到什么的对的,还能学习到什么是错的,这些错误的样本与正确样本的相识程度等等方面。另一方面,教师的监督考虑了数据增强的影响,这有时会导致真实标签与图像之间的错位。如果猫不再在数据增强的裁剪中,它会隐式地更改图像的标签。KD散度分布可以将归纳偏差以一种软的方式转移到学生模型中。
其他内容可以参考其他博客:
eg:https://blog.csdn.net/nature553863/article/details/80568658
3. Distillation through attention
3.1 Soft distillation
Soft distillation的公式表达:
L g l o b a l S o f t d i s t i l l a t i o n = ( 1 − λ ) L C E ( ψ ( Z s ) , y ) + λ τ 2 K L ( ψ ( Z s ) / τ , ψ ( Z t ) / τ ) L_{global}^{Soft distillation} = (1-λ)L_{CE}(ψ(Z_{s}),y) + λτ^{2}KL(ψ(Z_{s})/τ,ψ(Z_{t})/τ) LglobalSoftdistillation=(1−λ)LCE(ψ(Zs),y)+λτ2KL(ψ(Zs)/τ,ψ(Zt)/τ)
其中: Z t Z_{t} Zt表示的是教师网络的输出概率, Z s Z_{s} Zs表示学生网络的输出概率, τ τ τ表示蒸馏温度, λ λ λ表示Kullback-Leibler散度损失与交叉熵损失之间的权重因子, y y y表示真实标签, ψ ψ ψ表示softmax函数
公式很容易可以理解,loss为学生网络与真实标签的损失加上学生网络输出值与教师网络输出值的标签分布差异。一方面希望学生网络的输出值与真实标签相近,同时还希望其与教师网络的输出分布相近,这样才可以学习到教师网络对某些错误数据与正确数据的相识情况。
3.2 Hard-label distillation
Hard-label distillation的公式表达:
L g l o b a l h a r d D i s t i l l = 1 2 L C E ( ψ ( Z s ) , y ) + 1 2 L C E ( ψ ( Z s ) , y t ) L_{global}^{hardDistill} =\frac{1}{2}L_{CE}(ψ(Z_{s}),y) + \frac{1}{2}L_{CE}(ψ(Z_{s}),y_{t}) LglobalhardDistill=21LCE(ψ(Zs),y)+21LCE(ψ(Zs),yt)
其中: y t = arg max Z t y_{t} = \argmax Z_{t} yt=argmaxZt
公式同样比较好理解,一方面使得学生网络与真实标签的损失最小,同时也希望与教师网络得出来的标签损失最小,这两个损失各占一半的权重。
对于给定的图像,与教师相关的硬标签可能会根据具体的数据增强而改变,而这种选择比传统的选择更好,教师预测与真实labely扮演相同的角色。还要注意,硬标签也可以通过标签平滑转换为软标签。
3.3 Distillation token
作者向初始嵌入(patches and class token)添加一个新的token,即distillation token。distillation token与class token的使用类似,它通过自注意与其他嵌入(embedding)交互,并由最后一层之后的网络输出。蒸馏嵌入允许模型从老师的输出中学习,就像在常规蒸馏中一样,同时保持对class embedding的补充。
结构如图所示:
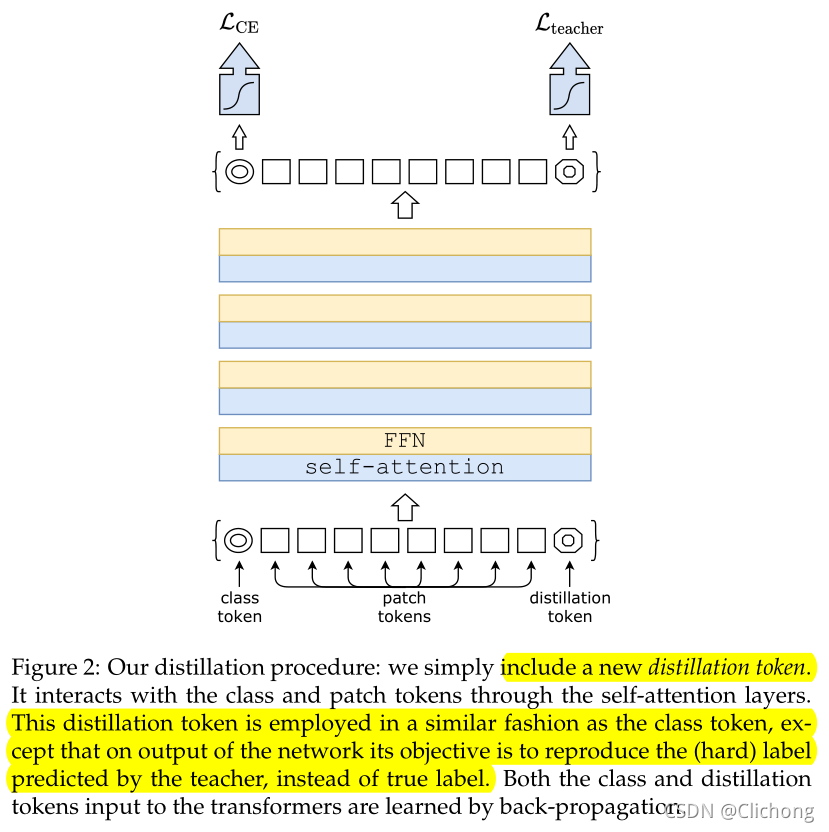
这个distillation token与class token的使用方式类似,只是在网络的输出上,它的目标是再现教师预测的(硬)标签,而不是真标签。distillation token与class token这两者都是通过反向传播来学习的。
研究者观察到,学得的 class token 和蒸馏 token 收敛到不同的向量:token 之间的余弦相似度等于 0.06。由于class embeddings和distillation embeddings是在每一层上进行计算的,因此它们在网络中变得越来越相似,一直到最后一层时相似度达到非常高(cos=0.93),但仍低于 1。这种情况在预期之中,因为它们的目的是生成相似但不同的目标。
distillation token的确向模型中添加了一些东西,而不是简单地添加一个与同一个目标标签相关联的额外class token。作者使用了带有两个class tokens的transformer,而不是一个教师的伪标签。即使随机地独立初始化它们,在训练时它们也收敛到同一个向量(cos=0.999),并且输出的embedding也是拟相同的。这个额外的class token不会对分类性能带来任何影响。相比之下,这样的蒸馏策略比香草蒸馏基线提供了显著的改进。
3.4 Fine-tuning with distillation
在微调阶段,对于高分辨率是,同时使用真实标签与教师预测值。对于教师网络使用相同的目标分辨率。当只使用真实标签时,会降低了教师网络的性能且导致性能下降
3.5 Joint classifiers
在测试时,由transformer产生的class embeddings或distillation embeddings都与线性分类器相关联,并能够推断图像标签。作者的参考方法是这两个分离头的后期融合,添加两个分类器的softmax输出来进行预测。
对于vit来说,这里进行分类预测的不是所以的patch,而是197个patch中的第一个patch,也就是那个第0个位置的class token,现在将其提出出来进行最后的分类预测。由上诉我们见到,一个patch所包含的信息维度是768,所以现在只需要简单的将这768维的信息变成一个dim = class_nums就可以了。
而DeiT使用的embedding为两个而已,将两个embedding信息通过两个预测头,得到的结果进行softmax再相加来进行预测。与Vit相对比就是[2, 768]->[2, dim],
softmax(dim1) + softmax(dim2) = output,也就是最后的预测结果。
4. Result
蒸馏方法生产的vision transformer,在准确性和吞吐量之间的权衡,成为与最好的卷积网络相等。有趣的是,在准确性和吞吐量之间的权衡方面,经过蒸馏的模型优于它的老师。在ImageNet-1k上的最佳模型的top-1精度为85.2%,优于在JFT-300M上以384分辨率(84.15%)预训练的最佳vitb模型。作为参考,目前的88.55%的额外训练数据是通过在JFT-300M分辨率下的JFT-300M上训练的vi模型(600M参数)获得的。
-
不同教师架构下的蒸馏结果:
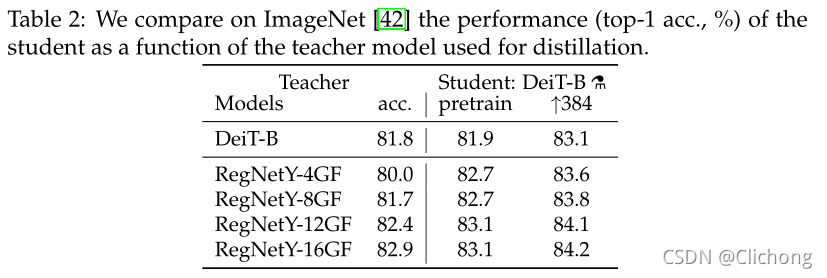
结果表明,convnet是一个更好的老师可能是由于transformers通过蒸馏继承的归纳偏差 -
不同蒸馏策略的性能表现:
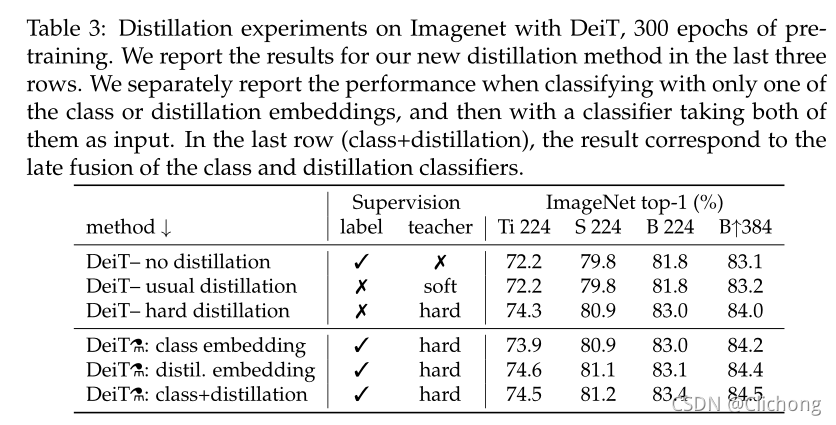
可以看见,使用两个token明显优于单独使用任意一个的token,表明两个token提供了对分类有用的互补信息。 -
与其他模型的性能对比:
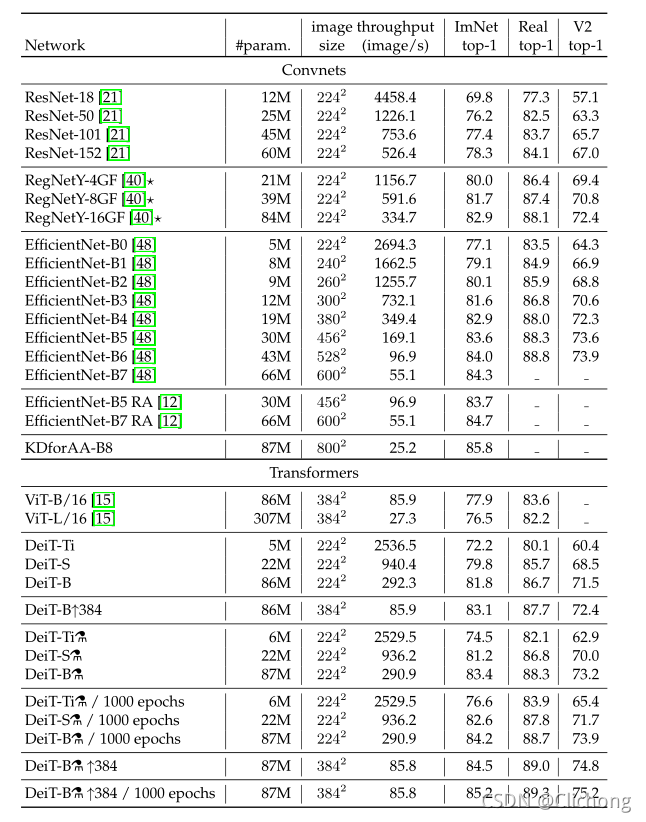
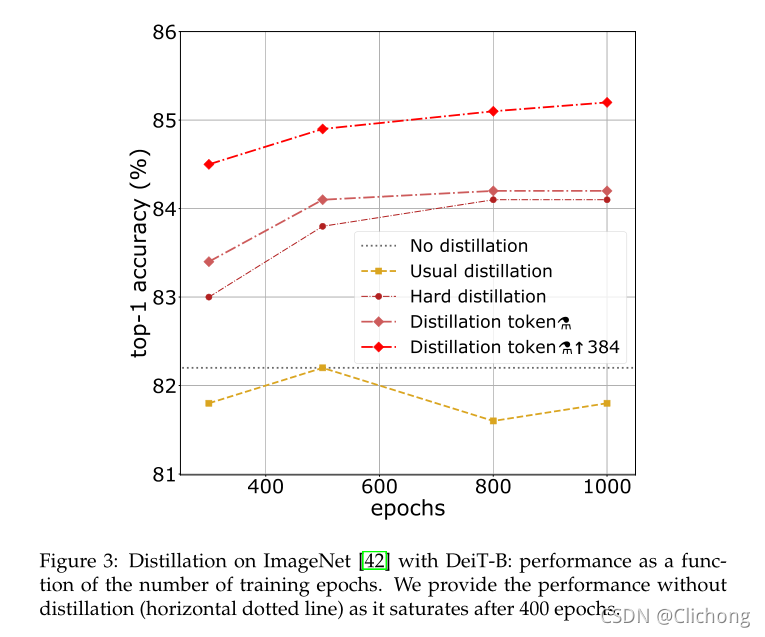
-
迁移学习到下游任务的性能:
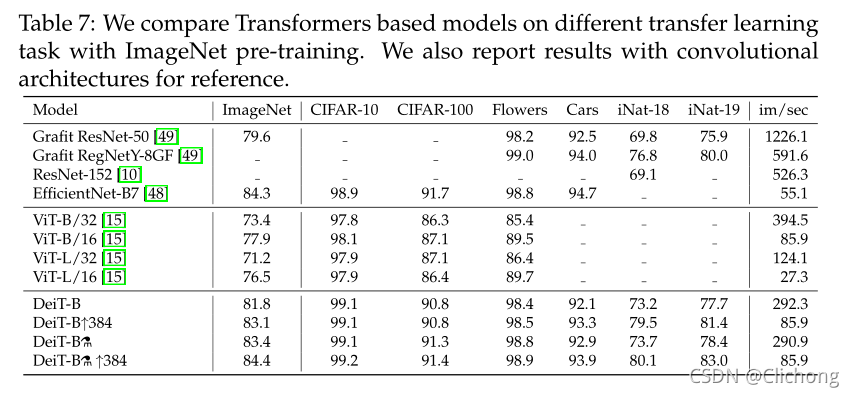
DeiT 的结果和最佳卷积的结果相当,这和此前在 ImageNet 数据集上的结论是一致的。相比之下,可以看见Vit模型的泛化能力不是很强。
总结:
DeiT提出了一种新的蒸馏思想,通过增加了一个distillation token与class token共同训练,最后通过distillation embedding与class embedding的共同作用进行预测结果。这样做的效果是可以不需要额外的大量预训练就可以达到与SOTA的convnet的类型效果。