分布式事务介绍
什么是事务(原一隔持)
数据库事务(简称:事务,Transaction)是指数据库执行过程中的一个逻辑单位,由一个有限的数据
库操作序列构成[由当前业务逻辑多个不同操作构成]。
事务拥有以下四个特性,习惯上被称为ACID特性:
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,
要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状
态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间
状态不能被观察到(这层语义也有说应该属于原子性)。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这
一个操作在被数据库所执行一样。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,
此操作将不可逆转。
本地事务
起初,事务仅限于对单一数据库资源的访问控制,架构服务化以后,事务的概念延伸到了服务中。
倘若将一个单一的服务操作作为一个事务,那么整个服务操作只能涉及一个单一的数据库资源,这
类基于单个服务单一数据库资源访问的事务,被称为本地事务(Local Transaction)。
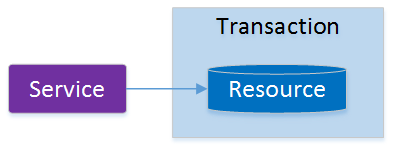
什么是分布式事务
分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布
式系统的不同节点之上,且属于不同的应用,分布式事务需要保证这些操作要么全部成功,要么全
部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
分布式事务应用架构
本地事务主要限制在单个会话内,不涉及多个数据库资源。但是在基于SOA(Service-Oriented
Architecture,面向服务架构)的分布式应用环境下,越来越多的应用要求对多个数据库资源,多个
服务的访问都能纳入到同一个事务当中,分布式事务应运而生。
单一服务分布式事务
最早的分布式事务应用架构很简单,不涉及服务间的访问调用,仅仅是服务内操作涉及到对多个数
据库资源的访问。
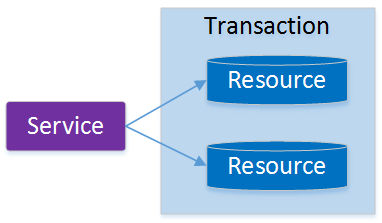
多服务分布式事务
当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式
事务来协调所有的事务参与者。
对于上面介绍的分布式事务应用架构,尽管一个服务操作会访问多个数据库资源,但是毕竟整个事
务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越
多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制
流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这
样一个跨越多个服务的分布式事务:
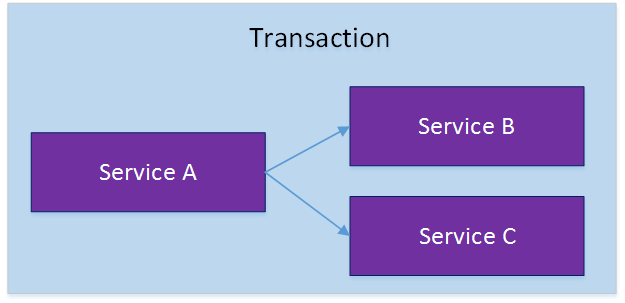
多服务多数据源分布式事务
如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对
此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布
式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调
用的那个服务。
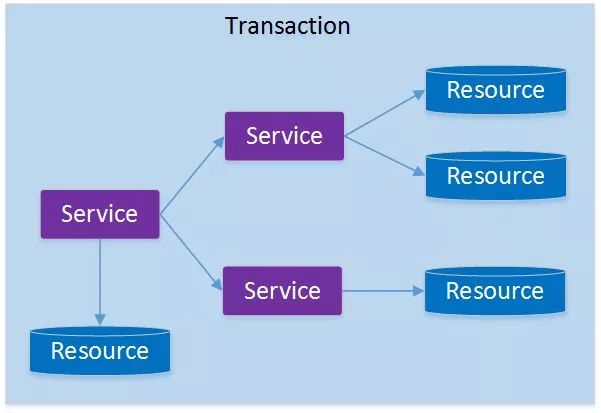
较之基于单一数据库资源访问的本地事务,分布式事务的应用架构更为复杂。在不同的分布式应用
架构下,实现一个分布式事务要考虑的问题并不完全一样,比如对多资源的协调、事务的跨服务传
播等,实现机制也是复杂多变。
事务的作用:
保证每个事务的数据一致性。CAP定理
CAP 定理,又被叫作布鲁尔定理。对于设计分布式系统(不仅仅是分布式事务)的架构师来说,CAP 就是你的入门理论。
C (一致性):对某个指定的客户端来说,读操作能返回最新的写操作。
对于数据分布在不同节点上的数据来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强
一致,如果有某个节点没有读取到,那就是分布式不一致。
A (可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的
响应。
合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里
的正确指的是比如应该返回 50,而不是返回 40。
P (分区容错性):当出现网络分区后,系统能够继续工作。打个比方,这里集群有多台机器,有台机器网络出现了问题,但是这个集群仍
然可以正常工作。
熟悉 CAP 的人都知道,三者不能共有,如果感兴趣可以搜索 CAP 的证明,在分布式系统中,网络无法 100% 可靠,分区其实是一个必然
现象。
如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证一致性,这个时候必须拒绝请求,但是 A 又不允许,所以分布式系统
理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
对于 CP 来说,放弃可用性,追求一致性和分区容错性,我们的 ZooKeeper 其实就是追求的强一致。
对于 AP 来说,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的 BASE
也是根据 AP 来扩展。
顺便一提,CAP 理论中是忽略网络延迟,也就是当事务提交时,从节点 A 复制到节点 B 没有延迟,但是在现实中这个是明显不可能的,
所以总会有一定的时间是不一致。
同时 CAP 中选择两个,比如你选择了 CP,并不是叫你放弃 A。因为 P 出现的概率实在是太小了,大部分的时间你仍然需要保证 CA。
就算分区出现了你也要为后来的 A 做准备,比如通过一些日志的手段,是其他机器回复至可用。

1.基于XA协议的两阶段提交(2PC)
2.补偿事务(TCC)
3.本地消息表(异步确保)
4.MQ事务消息
5.Seata 2PC->改进
2019 年 1 月,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback),和社区一起共建开源分布式事务解
决方案。Fescar 的愿景是让分布式事务的使用像本地事务的使用一样,简单和高效,并逐步解决开发者们遇到的分布式事务方面的所有难
题。
Fescar 开源后,蚂蚁金服加入 Fescar 社区参与共建,并在 Fescar 0.4.0 版本中贡献了 TCC 模式。
为了打造更中立、更开放、生态更加丰富的分布式事务开源社区,经过社区核心成员的投票,大家决定对 Fescar 进行品牌升级,并更名
为 Seata,意为:Simple Extensible Autonomous Transaction Architecture,是一套一站式分布式事务解决方案。
Seata 融合了阿里巴巴和蚂蚁金服在分布式事务技术上的积累,并沉淀了新零售、云计算和新金融等场景下丰富的实践经验。
Seata介绍
解决分布式事务问题,有两个设计初衷
对业务无侵入:即减少技术架构上的微服务化所带来的分布式事务问题对业务的侵入
高性能:减少分布式事务解决方案所带来的性能消耗
seata中有两种分布式事务实现方案,AT及TCC
-
AT模式主要关注多 DB 访问的数据一致性,当然也包括多服务下的多 DB 数据访问一致性问题,是2PC的改进
-
TCC 模式主要关注业务拆分,在按照业务横向扩展资源时,解决微服务间调用的一致性问题

AT模式
Seata AT模式是基于XA事务演进而来的一个分布式事务中间件,XA是一个基于数据库实现的分布式事务协议,本质上和两阶段提交一样,需要数据库支持,Mysql5.6以上版
本支持XA协议,其他数据库如Oracle,DB2也实现了XA接口

Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
Transaction Manager(TM): 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。

数据源要换成seata数据源,seata数据源会绑定undo_log表的操作,这张日志表会记录每次操作前和操作后的数据,并且会有xid产生,也会一起记录进去,
生成行级锁,释放当前链接。如果本地操作没有问题,就汇报给TC,如果所有的RM都没问题,就删了日志表,如果失败会根据快照rollback。


TCC模式
seata也针对TCC做了适配兼容,支持TCC事务方案,原理前面已经介绍过,基本思路就是使用侵入业务上的补偿及事务管理器的协调来达到全局事务的一起提交及回滚。

AT模式: AT 模式的一阶段、二阶段提交和回滚(借助undo_log表来实现)均由 Seata 框架自动生成,用户只需编写“业务SQL”,便能轻
松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
TTC模式: 相对于 AT 模式,TCC 模式对业务代码有一定的侵入性,但是 TCC 模式无 AT 模式的全局行锁,TCC 性能会比 AT模式高很
多。适用于核心系统等对性能有很高要求的场景。
https://blog.csdn.net/ZHOU_VIP/article/details/118793722
扩展:https://blog.csdn.net/seanxwq/article/details/115208579
AT 模式如何做到对业务的无侵入
一阶段:
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新
业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
二阶段提交:
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
总结
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。但AT模式存在的不足就是 当操作的数据 是共享型数据,会存在脏写的问题,所以如果是 用户独有数据可以使用AT模式。
https://github.com/seata/seata-samples/blob/master/doc/quick-integration-with-spring-cloud.md
Spring Cloud快速集成Seata
1. 添加依赖

2. 添加Seata 配置文件
registry.conf
该配置用于指定 TC 的注册中心和配置文件,默认都是 file; 如果使用其他的注册中心,要求 Seata-Server 也注册到该配置中心上
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
file.conf
该配置用于指定TC的相关属性;如果使用注册中心也可以将配置添加到配置中心
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#vgroup->rgroup
vgroup_mapping.my_test_tx_group = "default"
#only support single node
default.grouplist = "127.0.0.1:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
}
## transaction log store
store {
## store mode: file、db
mode = "file"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
committing-retry-delay = 30
asyn-committing-retry-delay = 30
rollbacking-retry-delay = 30
timeout-retry-delay = 30
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}
需要注意的是 service.vgroup_mapping这个配置,在 Spring Cloud 中默认是${spring.application.name}-fescar-service-group,可以通过指定
application.properties的 spring.cloud.alibaba.seata.tx-service-group这个属性覆盖,但是必须要和 file.conf 中的一致,否则会提示 no available server to
connect

3. 注入数据源
Seata 通过代理数据源的方式实现分支事务;MyBatis 和 JPA 都需要注入 io.seata.rm.datasource.DataSourceProxy, 不同的是,MyBatis 还需要额外注
入 org.apache.ibatis.session.SqlSessionFactory
MyBatis
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource dataSource() {
return new DruidDataSource();
}
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
return sqlSessionFactoryBean.getObject();
}
}
4. 添加undo_log表
在业务相关的数据库中添加 undo_log 表,用于保存需要回滚的数据
CREATE TABLE `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8
5. 启动Seata-Server
在 https://github.com/seata/seata/releases 下载相应版本的 Seata-Server,修改 registry.conf为相应的配置(如果使用 file 则不需要修改),解压并通过以下命令启动:
sh ./bin/seata-server.sh
6. 使用@GlobalTransactional开启事务
在业务的发起方的方法上使用@GlobalTransactional开启全局事务,Seata 会将事务的 xid 通过拦截器添加到调用其他服务的请求中,实现分布式事务
在所有微服务工程中,不一定所有工程都需要使用分布式事务,我们可以创建一个独立的分布式事务工程,指定微服务需要支持分布式事务的时候,
直接依赖独立的分布式工程即可。
搭建一个changgou-common-fescar提供fescar分布式事务支持。

pom.xml
<properties>
<fescar.version>0.4.2</fescar.version>
</properties>
<dependencies>
<dependency>
<groupId>com.changgou</groupId>
<artifactId>changgou_common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.alibaba.fescar</groupId>
<artifactId>fescar-tm</artifactId>
<version>${fescar.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fescar</groupId>
<artifactId>fescar-spring</artifactId>
<version>${fescar.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter</artifactId>
</dependency>
</dependencies>将配置文件夹中的所有配置文件拷贝到resources工程下,如下图:

其中file.conf有2个配置

service.vgroup_mapping.my_test_tx_group 映射到相应的 Fescar-Server 集群名称,然后再根据集群名称.grouplist 获取到可用服务列表。
TM和ProxyDataSource
核心在于对业务sql进行解析,转换成undolog,并同时入库,此时需要创建一个代理数据源,用代理数据源来实现。
要想实现全局事务管理器,需要添加一个@GlobalTransactional注解,该注解需要创建一个解析器,GlobalTransactionScanner,它是一个全局事务扫描器,用来解析带有@GlobalTransactional注解的方法,然后采用AOP的机制控制事务。
每次微服务和微服务之间相互调用,要想控制全局事务,每次TM都会请求TC生成一个XID,每次执行下一个事务,也就是调用其他微服务的时候都需要将该XID传递过去,所以我们可以每次请求的时候,都获取头中的XID,并将XID传递到下一个微服务。
TM和ProxyDataSource实现
创建FescarAutoConfiguration类,代码如下:
package com.changgou.fescar.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.fescar.rm.datasource.DataSourceProxy;
import com.alibaba.fescar.spring.annotation.GlobalTransactionScanner;
import com.changgou.fescar.filter.FescarRMRequestFilter;
import com.changgou.fescar.interceptor.FescarRestInterceptor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
import org.springframework.http.client.ClientHttpRequestInterceptor;
import org.springframework.web.client.RestTemplate;
import javax.sql.DataSource;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Collection;
import java.util.List;
/**
* * 创建数据源
* * 定义全局事务管理器扫描对象
* * 给所有RestTemplate添加头信息防止微服务之间调用问题
*/
@Configuration
public class FescarAutoConfiguration {
public static final String FESCAR_XID = "fescarXID";
/***
* 创建代理数据库
* @param environment
* @return
*/
@Bean
public DataSource dataSource(Environment environment){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(environment.getProperty("spring.datasource.url"));
try {
dataSource.setDriver(DriverManager.getDriver(environment.getProperty("spring.datasource.url")));
} catch (SQLException e) {
throw new RuntimeException("can't recognize dataSource Driver");
}
dataSource.setUsername(environment.getProperty("spring.datasource.username"));
dataSource.setPassword(environment.getProperty("spring.datasource.password"));
return new DataSourceProxy(dataSource);
}
/***
* 全局事务扫描器
* 用来解析带有@GlobalTransactional注解的方法,然后采用AOP的机制控制事务
* @param environment
* @return
*/
@Bean
public GlobalTransactionScanner globalTransactionScanner(Environment environment){
String applicationName = environment.getProperty("spring.application.name");
String groupName = environment.getProperty("fescar.group.name");
if(applicationName == null){
return new GlobalTransactionScanner(groupName == null ? "my_test_tx_group" : groupName);
}else{
return new GlobalTransactionScanner(applicationName, groupName == null ? "my_test_tx_group" : groupName);
}
}
/***
* 每次微服务和微服务之间相互调用
* 要想控制全局事务,每次TM都会请求TC生成一个XID,每次执行下一个事务,也就是调用其他微服务的时候都需要将该XID传递过去
* 所以我们可以每次请求的时候,都获取头中的XID,并将XID传递到下一个微服务
* @param restTemplates
* @return
*/
@ConditionalOnBean({RestTemplate.class})
@Bean
public Object addFescarInterceptor(Collection<RestTemplate> restTemplates){
restTemplates.stream()
.forEach(restTemplate -> {
List<ClientHttpRequestInterceptor> interceptors = restTemplate.getInterceptors();
if(interceptors != null){
interceptors.add(fescarRestInterceptor());
}
});
return new Object();
}
@Bean
public FescarRMRequestFilter fescarRMRequestFilter(){
return new FescarRMRequestFilter();
}
@Bean
public FescarRestInterceptor fescarRestInterceptor(){
return new FescarRestInterceptor();
}
}
注意:如果自定义fescar.group.name需要和file.conf中的名字保持一致。
创建FescarRMRequestFilter,给每个线程绑定一个XID,代码如下:
package com.changgou.fescar.filter;
import com.alibaba.fescar.core.context.RootContext;
import com.changgou.fescar.config.FescarAutoConfiguration;
import org.slf4j.Logger;
import org.springframework.util.StringUtils;
import org.springframework.web.filter.OncePerRequestFilter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
*
*/
public class FescarRMRequestFilter extends OncePerRequestFilter {
private static final Logger LOGGER = org.slf4j.LoggerFactory.getLogger( FescarRMRequestFilter.class);
/**
* 给每次线程请求绑定一个XID
* @param request
* @param response
* @param filterChain
*/
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String currentXID = request.getHeader( FescarAutoConfiguration.FESCAR_XID);
if(!StringUtils.isEmpty(currentXID)){
RootContext.bind(currentXID);
LOGGER.info("当前线程绑定的XID :" + currentXID);
}
try{
filterChain.doFilter(request, response);
} finally {
String unbindXID = RootContext.unbind();
if(unbindXID != null){
LOGGER.info("当前线程从指定XID中解绑 XID :" + unbindXID);
if(!currentXID.equals(unbindXID)){
LOGGER.info("当前线程的XID发生变更");
}
}
if(currentXID != null){
LOGGER.info("当前线程的XID发生变更");
}
}
}
}
创建FescarRestInterceptor过滤器,每次请求其他微服务的时候,都将XID携带过去。
package com.changgou.fescar.interceptor;
import com.alibaba.fescar.core.context.RootContext;
import com.changgou.fescar.config.FescarAutoConfiguration;
import feign.RequestInterceptor;
import feign.RequestTemplate;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpRequest;
import org.springframework.http.client.ClientHttpRequestExecution;
import org.springframework.http.client.ClientHttpRequestInterceptor;
import org.springframework.http.client.ClientHttpResponse;
import org.springframework.util.StringUtils;
import java.io.IOException;
import java.util.Collections;
/**
*
*/
public class FescarRestInterceptor implements RequestInterceptor, ClientHttpRequestInterceptor {
@Override
public void apply(RequestTemplate requestTemplate) {
String xid = RootContext.getXID();
if(!StringUtils.isEmpty(xid)){
requestTemplate.header( FescarAutoConfiguration.FESCAR_XID, xid);
}
}
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
String xid = RootContext.getXID();
if(!StringUtils.isEmpty(xid)){
HttpHeaders headers = request.getHeaders();
headers.put( FescarAutoConfiguration.FESCAR_XID, Collections.singletonList(xid));
}
return execution.execute(request, body);
}
}
分布式事务测试
微服务添加依赖
因为所有微服务都有可能使用分布式事务,所以我们可以在每个微服务工程中添加fescar的依赖,当然,搜索工程排除,因为它不需要依赖数据库,代码如下:

测试
在订单微服务的OrderServiceImpl的add方法上增加@GlobalTransactional(name = “add”)注解,代码如下:

这里涉及到几个微服务的调用,我们先查询下数据库数据,然后再测试一次,如果输出添加订单完成和库存减少完毕则表明订单微服务和商品微服务的事务已经完成,
这时候我们在添加积分的方法中制造一个异常,如果积分添加异常,而商品微服务中数据没发生变化,则表明分布式事务控制成功。
修改用户微服务,在添加用户积分的地方制造异常,代码如下:

启动Fescar-server,打开seata包/fescar-server-0.4.2/bin,双击fescar-server.bat启动fescar-server,如下:

测试前后结果一致

参考: