(一)关于二级索引
因为Hbase的rowkey是唯一索引,无法满足大部分的需求,不能走rowkey索引,导致性能较差
所以要构建二级索引来代替全表扫描
(二)如何实现二级索引
Phoenix底层封装了大量的协处理器来实现二级索引的构建
- 1.根据数据存储需求 创建原始表 将数据写入表中
- 2 根据业务需求 构建二级索引 Phoenix自动创建索引
-create index indexName on tbName(colName);
-rowkey:name_id
- 3查询数据时,Phoenix根据过滤条件是否存在二级索引,优先判断走二级索引代替全表扫描
- 4原始数据表发生数据变化时,==Phoenix会自动更新索引表的数据==
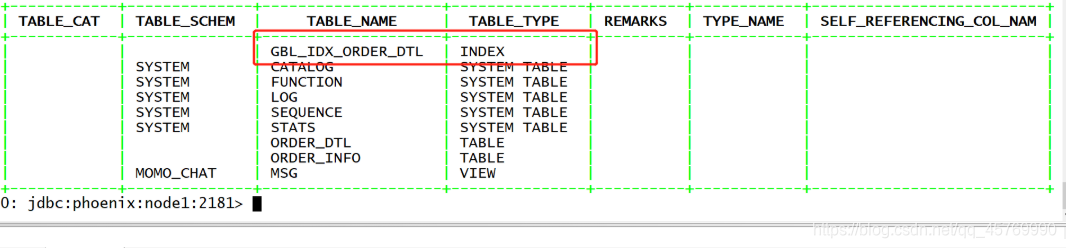
(二)全局索引的设计
什么是全局索引?
- 当为某一列创建全局索引时,Phoenix自动创建一张索引表,将创建索引的这一列加上原表的rowkey作为新的rowkey
-
原始数据表
rowkey:id name age
需求:根据name进行数据查询
创建索引
create index index01 on tbname(name);
Phoenix自动构建索引
rowkey:name_id col:占位值

查询:先走索引表 再走数据表
特点:默认只能对构建索引的字段做索引查询,如果查询中包含了不是索引的字段或者条件不是索引字段,不走索引
强制走索引
explain select /*+ INDEX(ORDER_DTL GBL_IDX_ORDER_DTL) */ * from ORDER_DTL where "user_id" = '8237476';
删除索引
drop index GBL_IDX_ORDER_DTL on ORDER_DTL;
(三)覆盖索引
什么是覆盖索引?
在构建全局索引时,将经常作为查询条件的列放入索引表中,直接通过索引表来返回数据结果
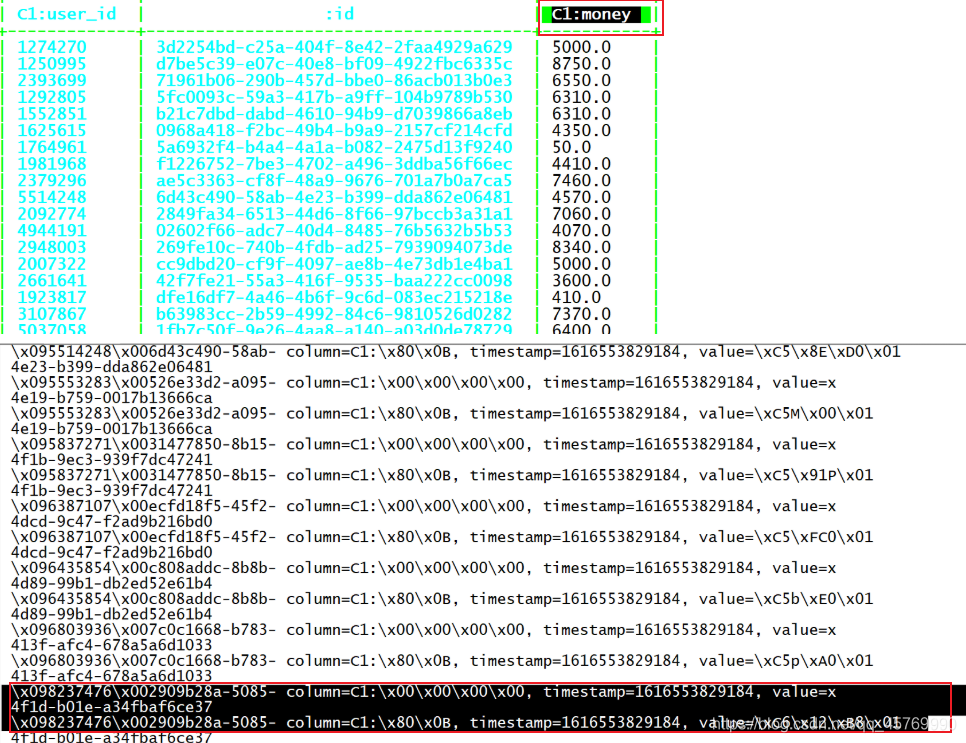
覆盖索引的实现
创建全局+覆盖:include(age)
create index index01 on tbname(name) include(age);
自动构建索引表
rowkey:name_id col:age
特点:
基于全局索引构建,将常用的查询结果放入索引表中,直接从索引表返回结果
适合于查询条件比较固定,数据量比较小的场景下
不建议将大部分列都放入覆盖索引,导致索引表过大,性能降低
总结:覆盖索引是基于全局索引实现的