With the rapid development of cloud computing, more and more small and medium enterprises have purchased cloud database service systems to replace self-built databases. However, most users only stay at the use level after purchasing the cloud database service system, and often encounter the problem of database system performance degradation during use. Due to the lack of experience in database management system performance optimization, it is difficult for users to find that the database system performance is caused. The reasons for the decline are effectively solved, which requires the cloud service provider to adjust the database system parameters for users in a timely manner to ensure that the performance of the database is maintained in a better state. For cloud service providers with hundreds of thousands of user instances, it is unrealistic to rely entirely on database experts for database parameter tuning. How to use AI technology to solve database system performance problems is becoming more and more important and urgent.
Recently, Tencent and Huazhong University of Science and Technology jointly released the latest research paper "An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning", which first proposed an end-to-end cloud database automatic performance based on deep reinforcement learning The optimization system CDBTune, which can establish an optimization model in the absence of relevant experience data training, provides cloud database users with online automatic database performance optimization services. The performance tuning results for the first time fully surpass database experts , which will greatly improve database operation and maintenance efficiency . The paper has been included in the top international database conference SIGMOD, and will be publicly published at the SIGMOD 2019 International Conference in Amsterdam, Netherlands on June 30. This achievement was completed by the team of Professor Zhou Ke from Wuhan Optoelectronics National Research Center of Huazhong University of Science and Technology and the CDB database team of the Cloud Architecture Platform Department of Tencent's Technology Engineering Business Group. Doctoral student Zhang Ji is the first author.
For this paper, the SIGMOD review committee gave a very high evaluation:
The paper is on the exciting new area of tuning databases with machine learning. Specifically using reinforcement learning. It does not just throw machine learning techniques but it does a good effort to explain how the techniques exactly match to the particular problem, what are the analogies with more traditional machine learning terminology, etc. Given that not everyone is knowledgeable in these techniques in the DB community this works in an educational way as well and is very much appreciated.
(This article is about the use of machine learning methods to optimize the database technology, which is an exciting new field. Especially it uses reinforcement learning methods. This article is not only a simple machine learning technology, but also very It is a good explanation of how machine learning is fully matched to specific problems, and it also explains the analogy between traditional machine learning terms. Since not everyone in the database community is well aware of these technologies, this is also one Kind of teaching method, so we appreciate this article very much.)
The AI frontline immediately contacted the CDB database team of Tencent's TEG Cloud Architecture Platform Department for an exclusive interview. The content is organized as follows:
Why is CDBTune born?
With the continuous rapid growth of the self-research business and the scale of database instances on Tencent Cloud, the team found that for many users of Tencent database CDB, due to the lack of rich database performance optimization experience, it is difficult to find the cause of the decline in database performance and effectively solve it. . For the CDB team, it is costly and unrealistic to rely entirely on database experts for database parameter tuning.
Before CDBTune, the industry also had similar work on automatic database performance tuning. There are roughly two directions:
The first direction mainly uses the heuristic search method to reduce the high-dimensional configuration space. This method does not use any historical experience data, so it needs to start from 0 at the beginning of each tuning task, and the tuning efficiency is low.
Another direction is to use traditional machine learning methods in a pipeline, which leads to a certain error in the recommended configuration. Moreover, a large amount of high-quality empirical data is required for model training, which raises the learning threshold.
The main goal of CDBTune is to solve two problems: lower the learning threshold and improve the efficiency of tuning.
How CDBTune works
The working process of CDBTune is mainly divided into two steps: offline training and online tuning. Offline training is to use some standard load generators to pressure test the database, collect training data, and train a preliminary configuration recommendation model. When users or system administrators have database performance optimization requirements, they can submit an online parameter tuning request through the corresponding interactive interface. At this time, the cloud controller sends an online parameter tuning request to the intelligent optimization system, and adjusts the previous parameters according to the user’s real load. The established preliminary model is fine-tuned, and then the corresponding parameter configuration recommended after the fine-tuning of the model is set in the database. Repeat the above process until the performance of the database to be adjusted meets the needs of the user or system administrator, and then stop the adjustment.
CDBTune system interaction diagram
Regarding why reinforcement learning is used in the system, the CDB database team stated that reinforcement learning can train the model while generating data, and reinforcement learning can learn from success or failure, so it has an impact on the quality of the previous training samples. The requirements will not be very high, which reduces the threshold for learning modeling. In the CDBTune system, reinforcement learning mainly optimizes the configuration of the recommendation network through excitation signals (changes in database performance), so that the recommended configuration parameters are more reasonable.
Reinforcement learning and database performance optimization diagram
CDBTune performanceCDB 团队主要采用并发和延时两个指标来衡量数据库的性能。论文从整体性能比较(推荐时间、推荐结果),不同可调参数个数的影响比较,在弹性云环境下(用户内存和磁盘空间变化)CDBTune 的适应能力等三大方面对 CDBTune 进行考量。
推荐耗时比较
为了了解不同步骤在训练和调优过程中所需要的耗时,团队记录了每个步骤的平均运行时间。每个步骤的运行时间为 5 分钟,主要又细分为 5 个部分(不包括重启 CDB 的 2 分钟),如下所示:
(1)压力测试时间(152.88 秒):工作负载的运行时间 用于收集数据库当前度量的工作负载生成器的运行时间。
(2)度量收集时间(0.86 ms):从内部度量获取状态向量并通过外部指标计算奖励的运行时间。
(3)模型更新时间(28.76 ms):在一次训练过程中神经网络前向计算和反向传播的运行时间。。
(4)推荐时间(2.16 ms):从输入数据库状态到输出推荐配置的运行时间。
(5)部署时间(16.68 秒):从输出推荐配置到根据 CDB 的 API 接口部署配置的运行时间。
对于离线训练,CDBTune 在 266 种推荐配置上训练完成需要大约 4.7 小时,在 65 种推荐配置上训练需要 2.3 小时。请注意,配置数会影响离线训练时间,但不会影响在线调优的时间。对于在线调优,每个调优请求分 5 步执行 CDBTune,总的耗时为 25 分钟。
另外,团队将 CDBTune 的在线调优效率与 OtterTune、BestConfig 和 DBA 进行对比,结果如下表所示。

其中,只有 CDBTune 需要离线训练,但它只需要进行一次训练就可以使用该模型进行在线调优,而 OtterTune 在每一次收到在线调优请求的时候都需要重新训练模型,BestConfig 则需要进行在线搜索。如下表所示,对于每个调优请求,OtterTune 需要 55 分钟,BestConfig 需要大约 250 分钟,DBA 需要 8.6 小时,而 CDBTune 只需要 25 分钟。在对比实验中,研发团队邀请了 3 位 DBA 来调整参数并选择其中的最佳结果。 DBA 需要大约 2 个小时才能开始执行工作负载重放并找到影响数据库性能的因素(例如,分析源代码中最耗时的函数,然后定位原因,并找到相对应可以调整的配置),这个过程通常需要丰富的经验和大量的时间。
推荐性能比较
如下图所示,CDB 团队在多种不同负载和不同类型的数据库下进行的大量实验证明,CDBTune 性能优化结果明显优于目前已有数据库调优工具和 DBA 专家。即使在弹性云环境下,用户购买数据库内存或磁盘大小发生变化,或负载发生变化(类型不变)的情况下,实验证明 CDBTune 依然保持了较好的适应能力。更多对比结果和数据在论文中有详细说明。
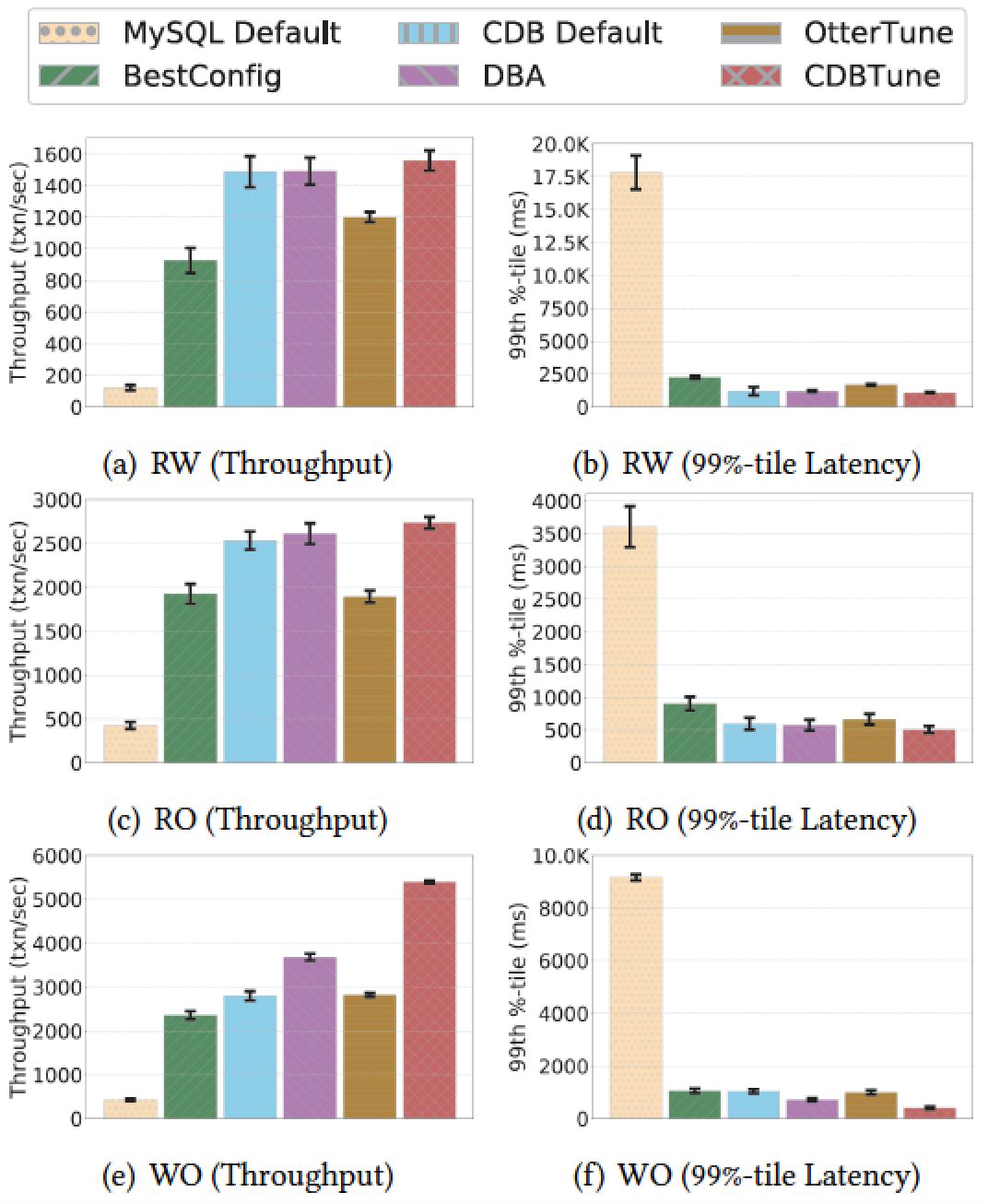
CDBTune 性能测试结果 1:性能比较
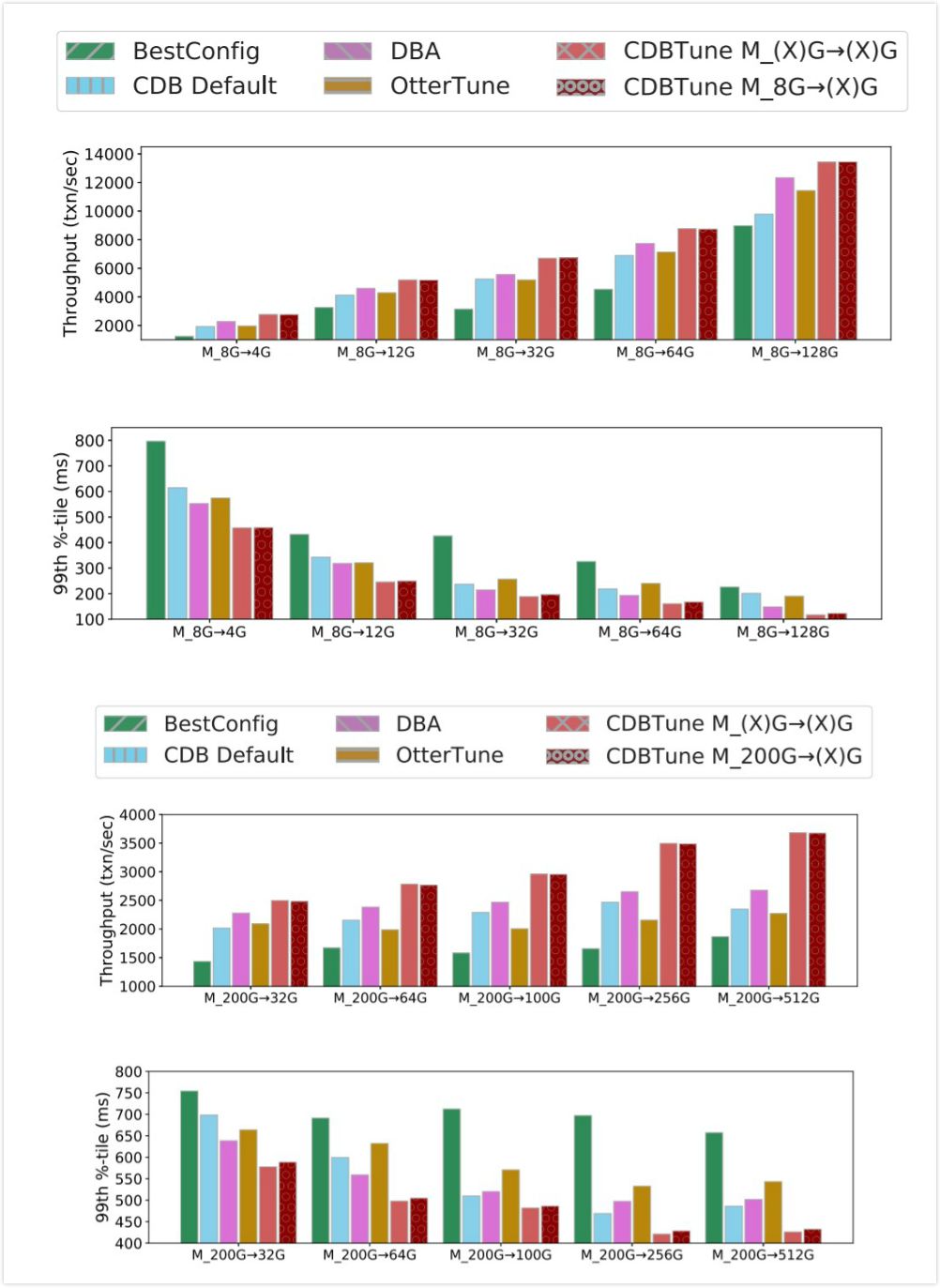
CDBTune 性能测试结果 2:内存 / 磁盘容量变化对模型的影响
据了解,CDBTune 不仅仅适用于云数据库,对于本地数据库同样也表现出了优异的性能,实验结果可以查阅论文的附录部分。
下一步计划
目前 CDBTune 在在线推荐配置时还需要花大约 25 分钟左右的时间,CDB 团队希望进一步压缩该时间,降低用户等待时间,从而提高用户体验。另外,目前团队正在进行 CDBTune 的产品化工作,相信过不了多久大家就可以在腾讯云上体验这项研究成果,研究团队也将继续寻求技术突破,以期在数据库调参领域取得更多成果。