The cumulative calculation statistical characteristic function in the pandas library:
1、cumsum()
Give the sum of the first 1, 2, ..., n numbers in turn
2 od buy ()
Give the product of the first 1, 2, ..., n numbers in turn
3、cummax()
Give the maximum value of the first 1, 2, ..., n numbers in turn
4、cummin()
Give the minimum of the first 1, 2, ..., n numbers in turn
note:
The cum series function appears as a method of the DataFrame or series object
Naming format: D.cumsm()
The rolling calculation statistical feature function in the pandas library:
1、rolling_sum()
Calculate the sum of data samples (calculated by column)
2、rolling_mean()
Calculate the arithmetic mean of the data sample
3 、 rolling_var ()
Calculate the variance of the data sample
4、rolling_std()
Calculate the standard deviation of the data sample
5、rolling_corr()
Calculate the spearman (Pearson) correlation coefficient matrix of the data sample
6 、 rolling_cov ()
Calculate the covariance matrix of the data sample
7、rolling_skew()
Calculate the skewness of the sample value (third moment)
8、rolling_kurt()
Calculate the kurtosis of the sample value (fourth moment)
note:
The rolling_ series function is a pandas function, not a method of the DataFrame or series object. Therefore, the format of the rolling_ series function is: pd.rolling_mean(Dk) , which means that the mean value is calculated once every k columns.
Examples:
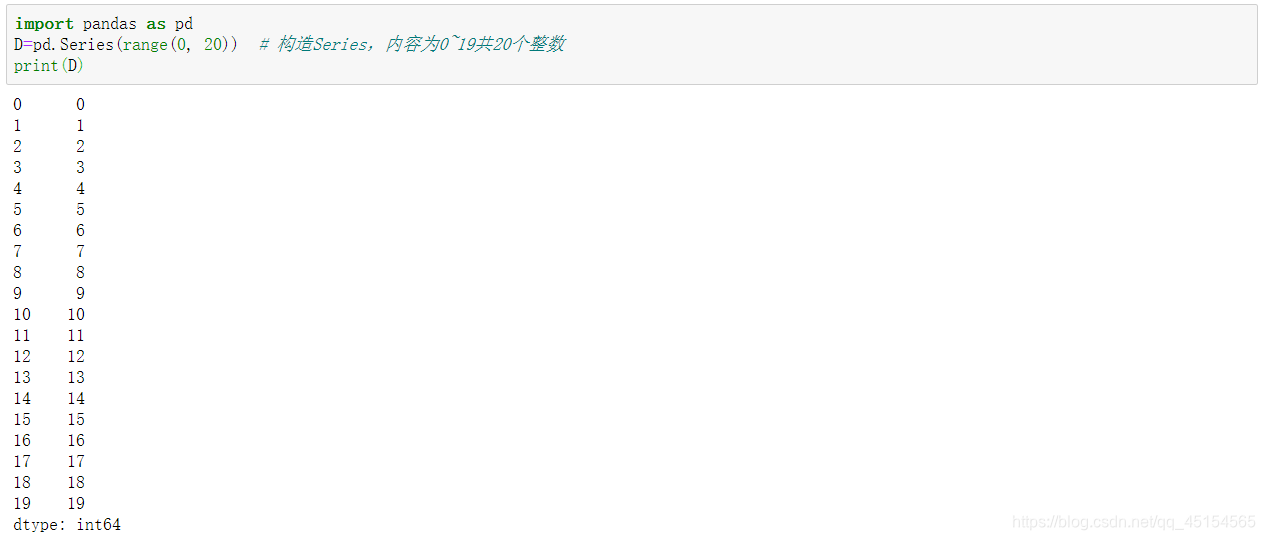
import pandas as pd
D=pd.Series(range(0, 20)) # 构造Series,内容为0~19共20个整数
print(D)
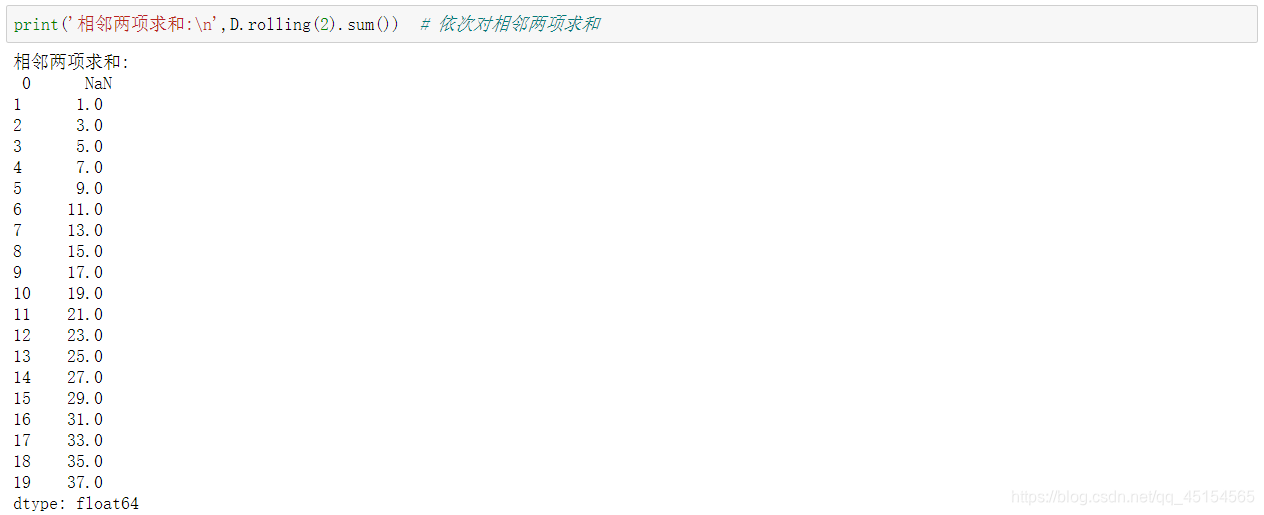
print('前n项和:\n',D.cumsum()) # 给出前n项和

print('相邻两项求和:\n',D.rolling(2).sum()) # 依次对相邻两项求和