Hello everyone, I am zeroing~
1 Introduction
When talking about image text OCR recognition before, I wrote an article introducing a Python package pytesseract , for details, please refer to
Introduce a Python package, a few lines of code can realize OCR text recognition! In this article, the pytesseract package is based on the Tesseract package. Although this package supports multilingual text recognition, the accuracy of text recognition in different languages is different. For example, the accuracy of English recognition is high, while the Chinese text is low;
English character recognition is basically no error as a whole, but for Chinese characters in pictures, garbled characters and recognition failures often appear.
2. Introduction to EasyOCR
Today, I will introduce a new Python package EasyOCR for text OCR . This package is developed based on the trained Deep Learning model. The model contains functions: text detection, text recognition
The EasyOCR package has been open source for less than 10 months, but there are already 10k+ stars on Github. So far, after four version iterations, it has the following characteristics:
- 1. So far, it supports text recognition in 70+ languages, including but not limited to English, Chinese, Japanese, Korean, etc.;
- 2. Due to deep learning technology, the recognition accuracy is very high; for normal picture text recognition, the accuracy rate can reach 100%;

- 3. It is not only suitable for single language, but also for multiple languages (for example, three languages of Chinese, English, and Japanese need to be recognized at the same time in a picture);

- 4. Support GPU acceleration, GPU recognition speed is 6~7 times faster than CPU; (you need to configure cuda, pytorch, torchvision Python environment in advance);
Image contrast has only traditional OCR text recognition addition, EasyOCR further includes text detection function (image block in the recognized text, positioned in the picture to 左上、右上、右下、左下the coordinates of the order back), to the following figure:

The final output is the above figure EasyOCR right of text information , left behind in the red frame is processed to add the
3. Use of EasyOCR
A brief introduction to the EasyOCR package is given above, and the basic usage of it is introduced below.
installation
EasyOCR has been uploaded to Pypi, and the installation can be completed through the pip command
pip install easyocr
The EasyOCR model is trained based on the pytorch framework. When easyocr downloads, it will download some additional python packages, such as pytorch, torchvision, etc., which will take a little longer ( note that easyocr installs the cpu version of pytorch by default and requires gpu configuration Friends can search pytorch-gpu related tutorials for configuration );
Instructions
Although the EasyOCR installation steps are very simple, only one line of code; but during the use process, there will be problems such as package version mismatch and missing environment items . During the use process, I encountered two problems that could not be used due to environmental errors. I posted here The solution is attached below. Friends who meet can refer to it. Of course, if you don’t meet it, it’s better.
1,from ._remap import _map_array
ImportError: DLL load failed: The specified module could not be found
The problem is caused by the loss of the C++ runtime package. The solution is to enter the following command in the terminal to install
pip install msvc-runtime
**2,train error : ImportError: cannot import name ‘Optional’ **
This problem is caused by the inconsistency of pytorch and torchvision versions. The torchvision version installed by default when easyocr is installed is 0.5.0, and the compatible version of pytorch should be 1.4.0, but when installing through the following command
pip install torch==1.14.0
The installation will fail, the solution: use another installation command
pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.htm
easyocr all functions are encapsulated into a class Reader, three methods may be invoked by the class which readtext、detect、recognizeis achieved,
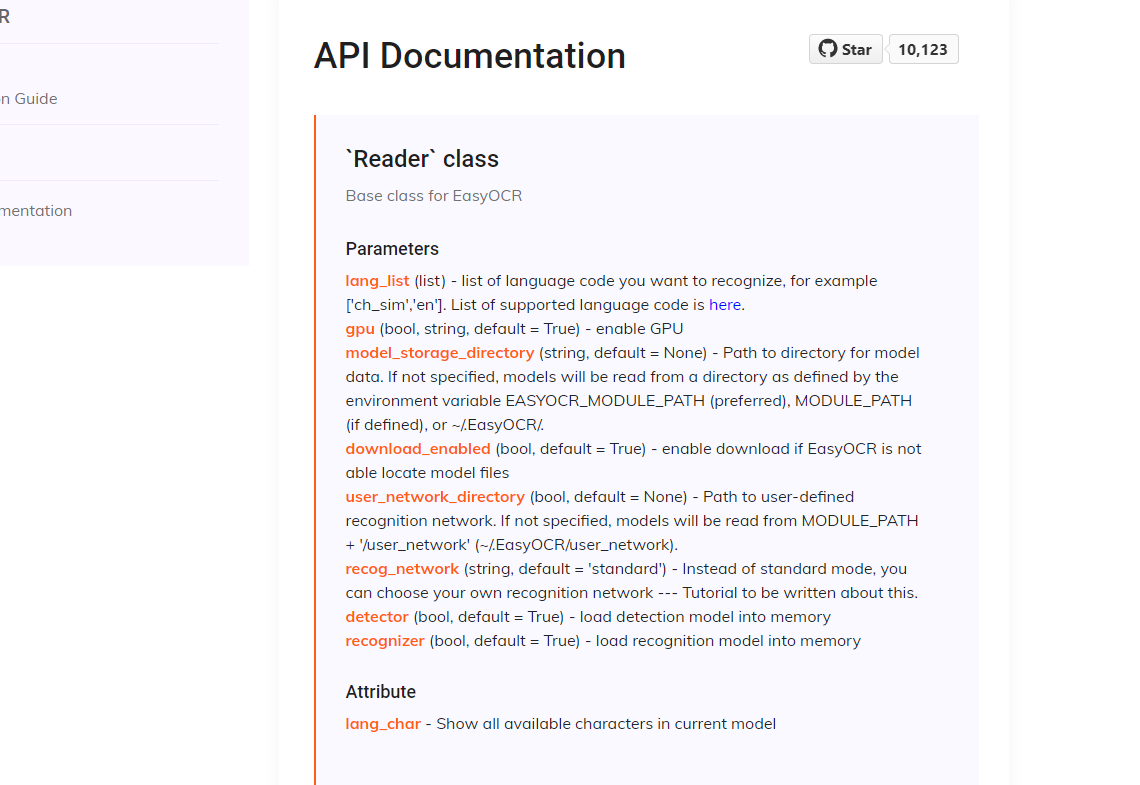
detectThe method is used to detect the text box in the image, and finally returns two lists to indicate the position of the text box in the image, one is in the format of horizontal_list [x_min,x_max,y_min,y_max], the other is in the format of free_list [[x1,y1],[x2,y2],[x3,y3],[x4,y4]],

The above picture is the verification code interface used by station B to pop up when the user logs in. In the following examples, this picture is used as a template. detecThe use of the t function is as follows
import easyocr
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.detect('ceshi.png')
print(result)
### ouput
([[11, 133, 11, 31], [158, 238, 2, 34], [199, 235, 315, 333]], [])
When in use, you first need to create a Readerclass, you need to specify some parameters in class:
- lang_list, used to specify the language codes that need to be recognized (such as Chinese, English), and store them in the form of a list. For the language codes, please refer to the following (only part is posted here. For details, please refer to the official website):
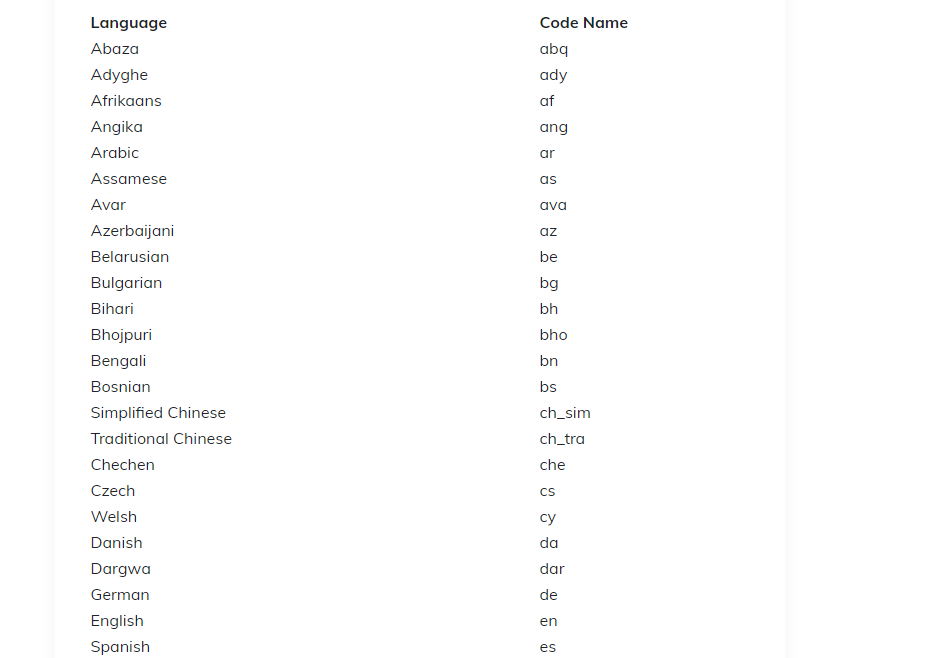
- gpu, a boolean value, indicates whether you need to use the GPU, the default is True;
- model_storage_directoy, string type, the default is
~./EasyOCR/.to specify the storage path of the network model, it is recommended to specify a new path;
Finally, two lists will be output, representing horizontal_list and free_list respectively
recognizeFor identifying a need to provide three parameters using the function image、horizontal_list、free_list, and when using detectmatched
- image represents a picture;
- horizontal_list, free_list rectangles represent text box list, as a function of
detectthe two output lists
The method of use is as follows
import easyocr
from PIL import Image,ImageDraw
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.recognize('ceshi.png',horizontal_list=[[11, 133, 11, 31], [158, 238, 2, 34], [199, 235, 315, 333]],free_list=[])
print(result)
### output
[([[158, 2], [238, 2], [238, 34], [158, 34]], '带鱼', 0.48613545298576355), ([[11, 11], [133, 11], [133, 31], [11, 31]], '清在下图依次点击:', 0.46184659004211426), ([[199, 315], [235, 315], [235, 333], [199, 333]], '确认', 0.31680089235305786)]
Finally, the recognize method will return the text information in each text box
readtextIt is a function detectand a recognizemethod of combining: to detect the position coordinates using the image recognition function Chinese box in the input coordinate list recognizeto identify, and finally returns the position coordinates of each text information, the frame functions as follows:
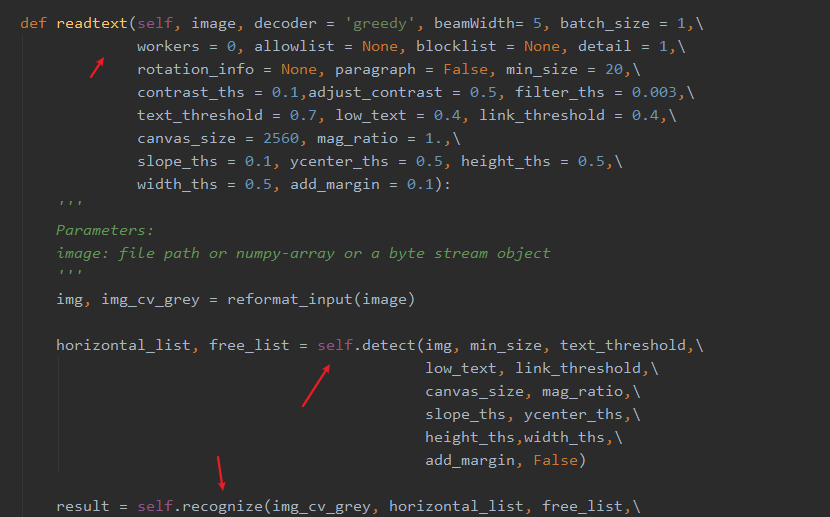
import easyocr
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.readtext('ceshi.png')
print(result)
### ouput
Using CPU. Note: This module is much faster with a GPU.
[([[158, 2], [238, 2], [238, 34], [158, 34]], '带鱼', 0.48613545298576355), ([[11, 11], [133, 11], [133, 31], [11, 31]], '清在下图依次点击:', 0.46184659004211426), ([[199, 315], [235, 315], [235, 333], [199, 333]], '确认', 0.31680089235305786)]
After getting the coordinates, in order to more intuitively observe the correctness of the detection results, the text box in the image can be drawn through PIL
import easyocr
from PIL import Image,ImageDraw
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.readtext('ceshi.png')
img = Image.open('ceshi.png')
draw = ImageDraw.Draw(img)
for i in result:
draw.rectangle((tuple(i[0][0]),tuple(i[0][2])),fill=None,outline='red',width=2)
img.save("ceshi3.png")
The effect is as follows

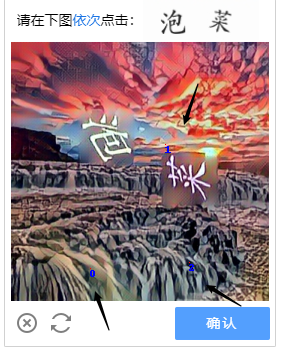
The results, in addition to the middle of the picture 带鱼than the text information is not identified, the text information in other regions can achieve good identification and detection effect;
Here is an explanation of the reason for the failure of recognition. If you observe carefully, you will find that the above picture is not real in reality, but a virtual image generated through deep learning technology such as GAN. The text information inside is not a single text paste. On the picture, I guess it has undergone some encryption processing,
In order to verify my guess, here I used the API interface provided by Super Eagle Code Ping, but in the end I still could not get a good recognition effect ( the blue font position in the figure represents the recognition result of the coding platform )
The above only introduces some general parameters in the easyocr method, and there are many default parameters that are not introduced. For example, batch_size controls the number of images that are recognized each time. With this parameter, batch recognition can be realized, but the premise requires the support of GPU large memory; adjust_contrast adjustment Image contrast
For more detailed information about easyocr, interested friends can see the official document: Document API ,
Well, the above is all the content of this article. Finally, thank you all for reading!