Sputnik: Airbnb's data development framework based on Spark
Past memory big data Past memory big data
This article comes from Airbnb’s engineer Egor Pakhomov’s sharing on the topic of "Sputnik: Airbnb's Apache Spark Framework for Data Engineering" at Spark Summit North America 2020. Related PPT can be obtained from the Spark AI Summit 2020 PPT you want. I have sorted it out for you.
A typical Spark job includes reading external data and then using Spark to process related logic, and then write it to external storage, such as Hive tables and object storage.
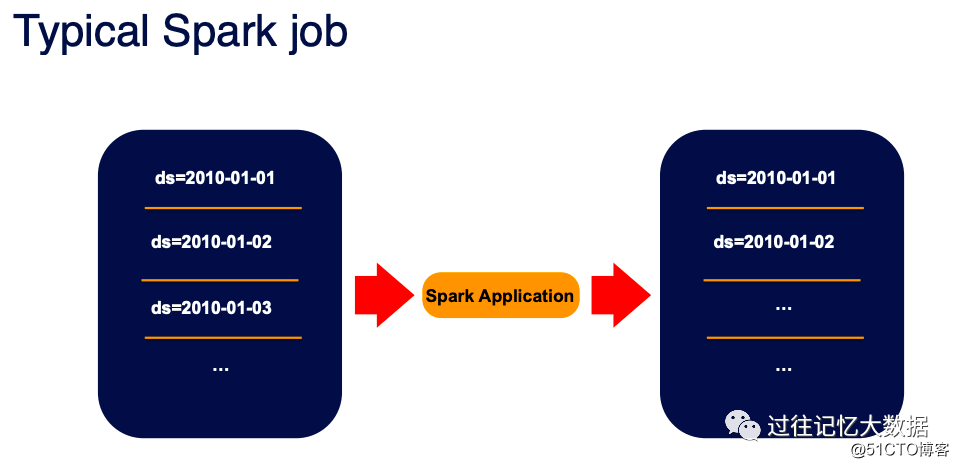
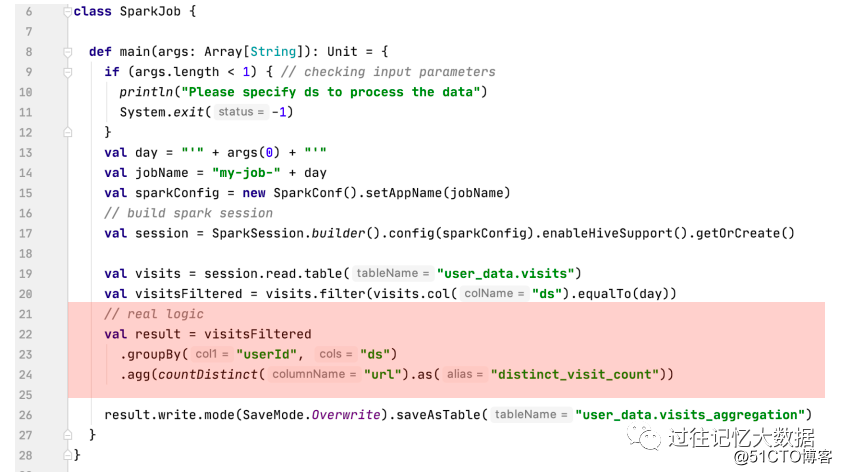
If the representative is used, the main framework is as shown above. As you can see, most of the logic in this program is processing parameter parsing, SparkSession creation, table input data processing, and result storage; only the red part is the real business part. 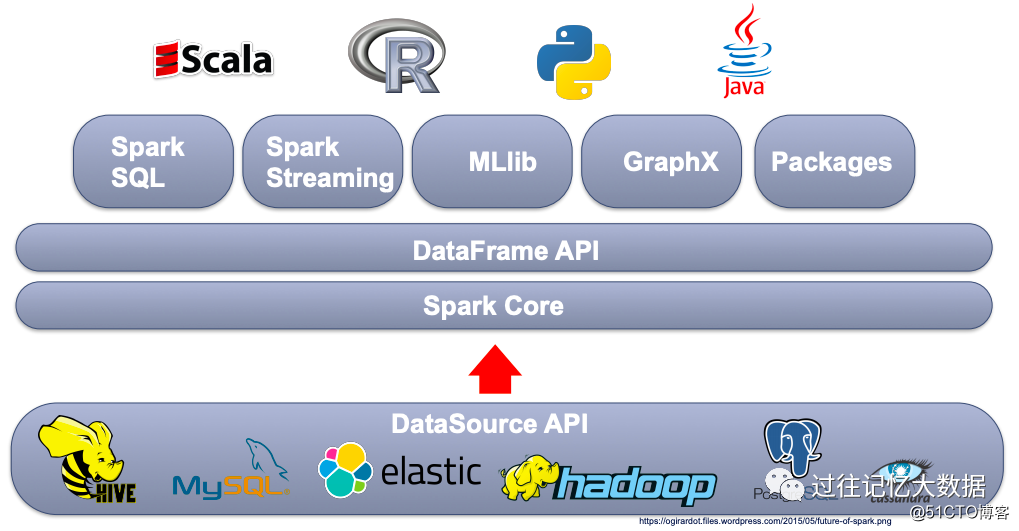
On the other hand, Spark is a very good general computing logic. Using DataSource API can read data from multiple data sources. Then Spark provides us with a variety of programming modes, such as Spark Core, DataFrame API, Spark SQL, Spark Streamig, etc., while providing Scala, R, Python and Java to implement various business logic. 
But at Airbnb, 99% of homework is written in Scala, mainly using Spark SQL and DataFrame API, and only reading and writing data in Hive. So at Airbnb, Spark provides so many functions, but it causes trouble for engineers.

For Airbnb's data development project, in fact, their focus should be to write a function similar to transform in which to process various business logic. This is what we call Job Logic. 
The difference between Job Logic and Run Logic is as follows:
Job Logic only needs to pay attention to business logic, such as how to calculate the traffic of each url; the input and output tables of the job; the processing of partitions and the verification of results.
Run Logic needs to process the input data range; save the results to the table when the table does not exist; when running in the test mode, the table needs to end with "_testing", so that online tables and test tables can be distinguished.
To help data development engineers, Airbnb developed a data work framework called Sputnik based on Apache Spark. Using this framework, all Run Logic is handled by Sputnik, and business personnel only need to pay attention to the implementation of Job Logic. 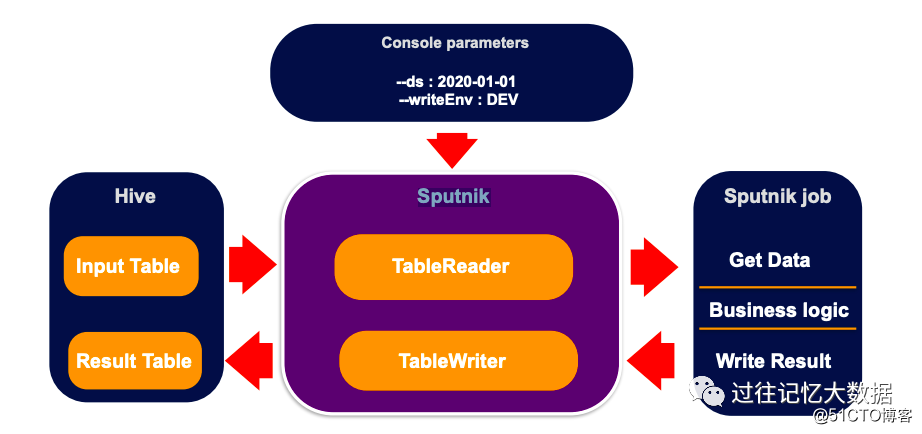
When using the Sputnik platform, users only need to extend the SputnikJob class to implement their own business logic, and use HiveTableReader to read table data: 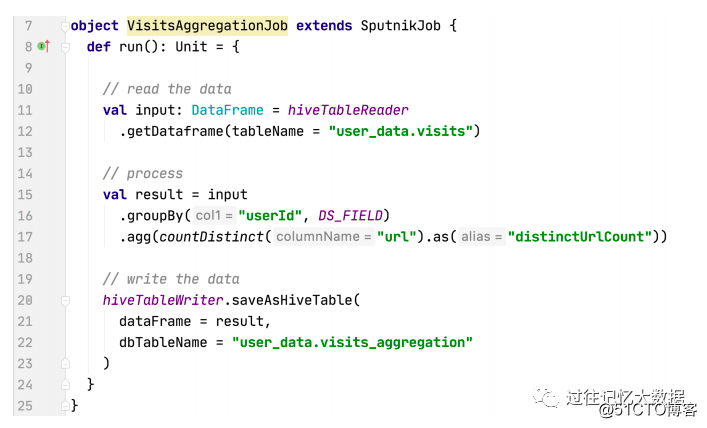
use hiveTableWriter to save the results to Hive's related tables and 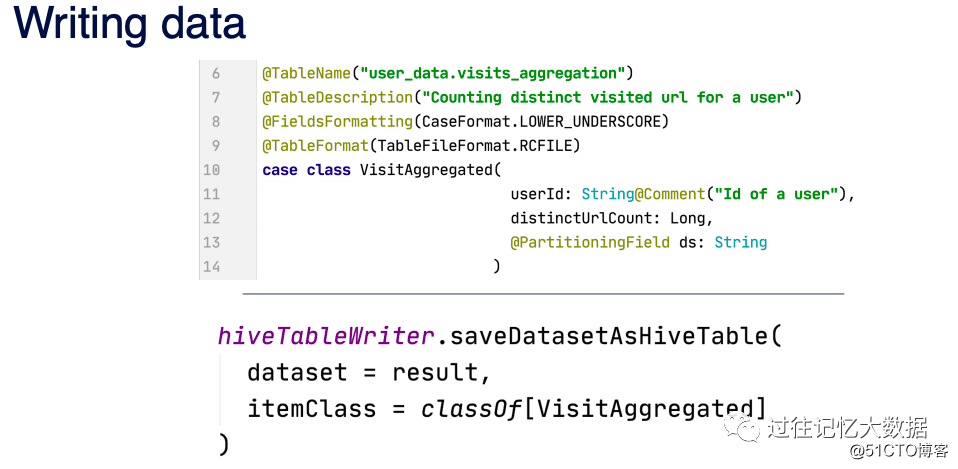

finally use SputnikJobRunner to run the job.
The user does not need to process the various parameter analysis mentioned above, and then process the data reading; when writing the result to the Hive table, there is no need to care about whether the table does not exist or not.

Sputnik HiveTableWriter mainly does the following things:
- When the written table does not exist, use Hive's CREATE TABLE to create the table;
- Update the metadata of the table;
- Standardize the DataFrame Schema according to the output table;
- Read the output table for repartition, in order to reduce the number of files written to disk;
- Perform some verification before writing data;
- Modify the table name of the output table according to different operating modes.

Sputnik provides an interface to convert data into DataFrame and DataSet. Users only need to output the table name and the processing time range of the table to get the DataFrame or DataSet of the table without having to deal with the various parameter parsing issues mentioned above.

Sputnik also supports configuration files so that users can configure some jobs. Business personnel only need to provide the relevant configuration file, and then use Sputnik to obtain the value of the relevant parameter. 
For output results, we generally need to do some null value check or empty output check, etc. Sputnik provides some common check classes, such as NullCheck, NotEmptyCheck, etc. The business personnel only need to directly configure the relevant verification class when outputting the table.
The picture only needs to configure --ds 2020-01-07 for daily operations to process the data of a certain day. For example, we can easily perform T+1 data processing through this. 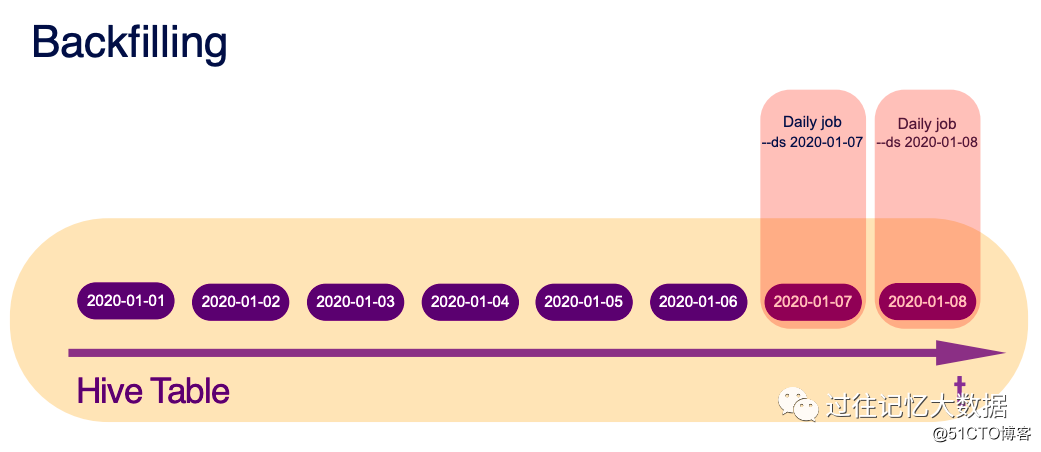
If you need to process data in a certain time range for some reason, you can use --startDate 2020-01-01 --endDate 2020-01-06 to achieve. 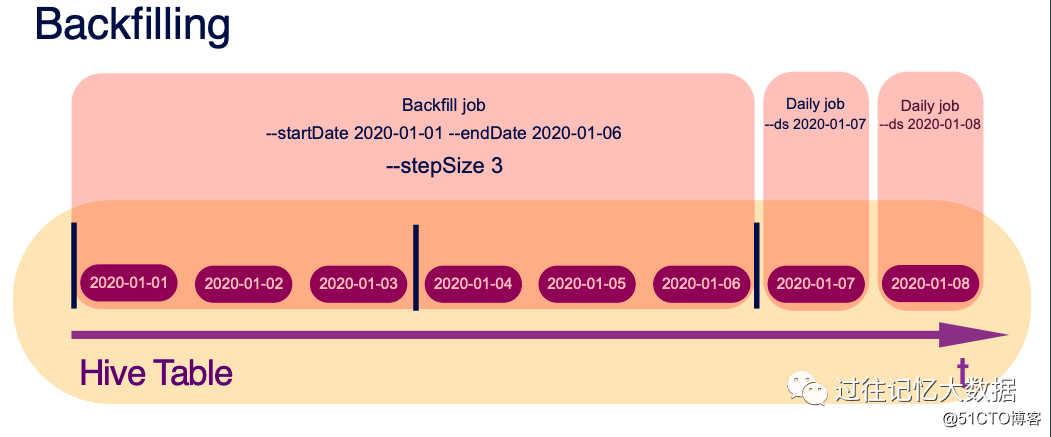
If you need to process data at intervals, you can use the --startDate 2020-01-01 --endDate 2020-01-06 --stepSize class 3 implementation. 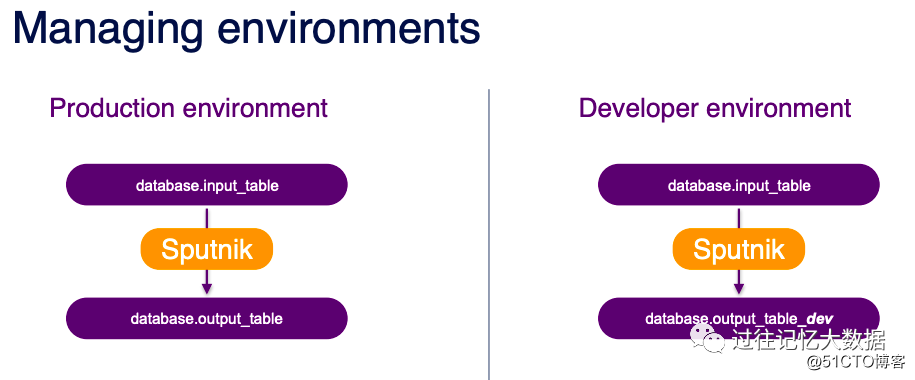
Before the business is realized, we generally need to perform some tests in the development environment. 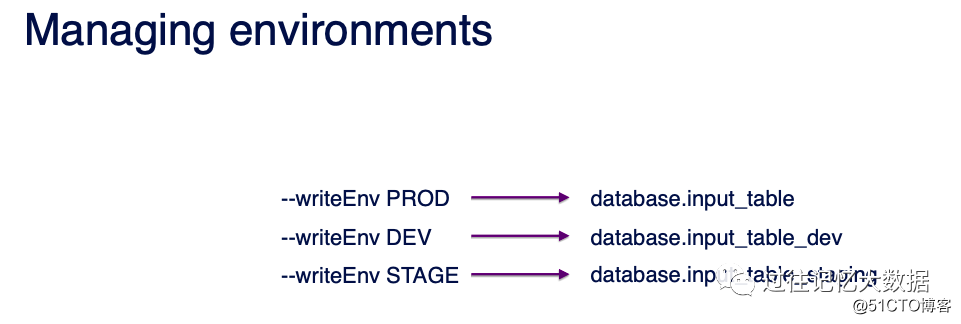
We only need to use the --writeEnv parameter to set the operating environment. For example, --writeEnv PROD represents the online environment; --writeEnv DEV represents the development environment, and dev is automatically added to the end of the input and output tables. 
Some other parameters include dropResultTables, sample, repartition, jobArgument, etc.