Reference: "MySQL Technical Insider InnoDB Storage Engine Version 2",
One, mysql logical structure
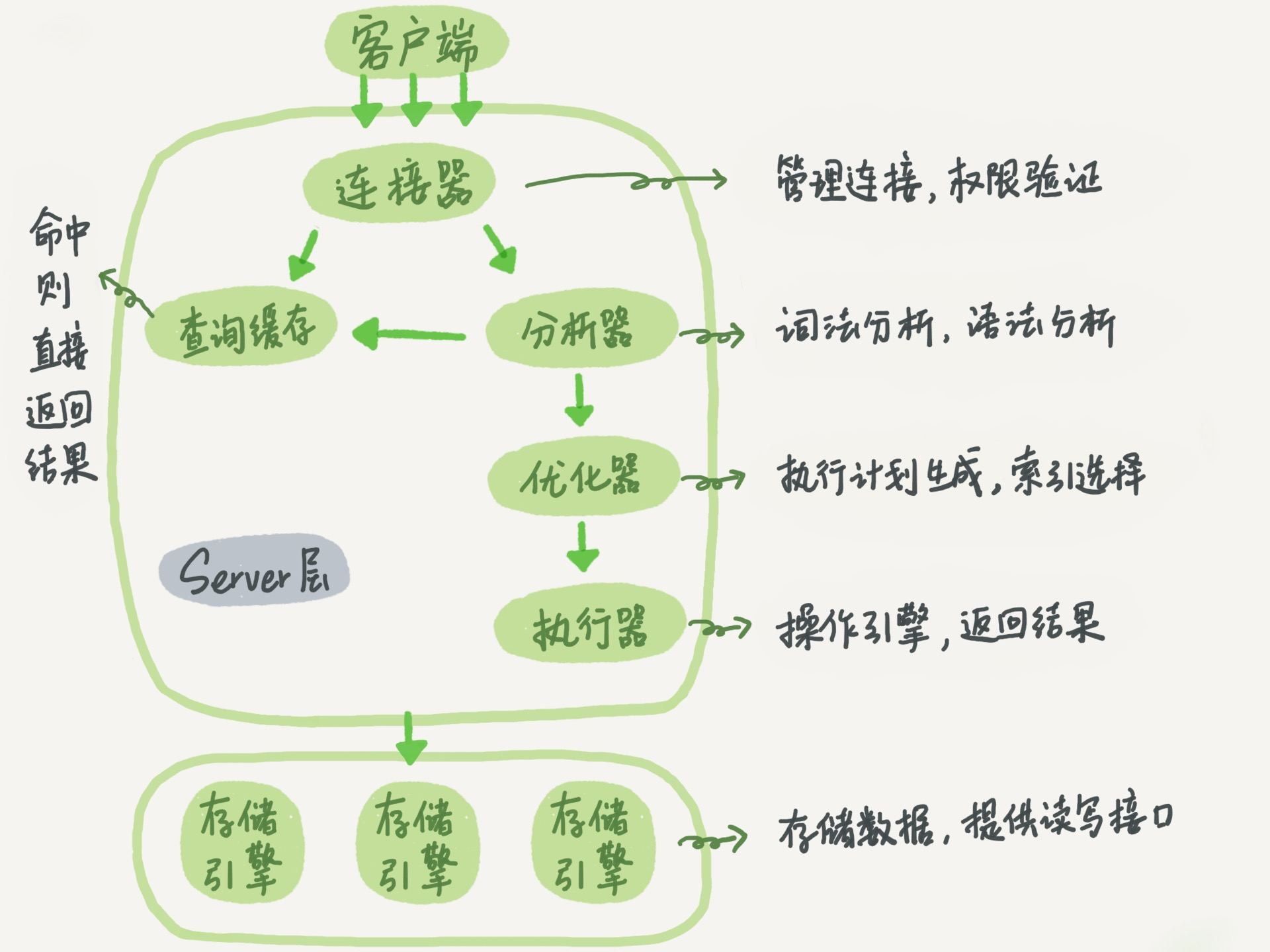
The architecture of mysql can be roughly divided into two parts: Server layer and storage engine layer:
- Server layer: Including connectors, query caches, analyzers, optimizers, executors and most of the core services of Mysql, as well as all built-in functions
- Storage engine layer: Responsible for data storage and extraction. Its architecture model is plug-in style. Starting from Mysql5.5, the default storage engine is InnoDB
The components related to the Server layer are introduced below:
- Connector: Responsible for managing connections, authorization authentication work, for example, the authorization between the administrator account and the ordinary account is different
- Query cache: Mysql will first come to the query cache when performing a query operation to determine whether the statement has been executed before. However, query cache is generally not recommended, because every time a table is updated, the cache on the table is Invalid, this function has been cancelled since mysql8.0
- Parser: The parser performs grammatical analysis when the work to be done to determine what operation the sentence is
- Optimizer: After the analyzer, does Mysql know what the statement does? The optimizer decides which index to use or other optimization operations when there are multiple indexes in the table
- Executor: Mysql knows what to do through the analyzer, and what to do through the optimizer, then the work to be done is to actually execute the statement and interact with the storage engine
The above sequence is actually to execute a query statement. What mysql does is like a pipeline.
2. Comparison of several common storage engines
- InnoDB: InnoDB storage engine is the default storage engine of Mysql. The InnoDB storage engine provides transaction security with commit, rollback, and crash recovery capabilities. However, compared with the storage engine of MyISAM, InnoDB writes are less efficient and will take up more disk space to retain data and indexes.
- MyISAM: MyISAM does not support transactions, nor does it support foreign keys. Its advantage is that it has fast access speed, and does not require transaction integrity or applications that are based on SELECT and INSERT can basically use this engine to create tables.
- MEMORY: The Memory storage engine stores table data in memory. Each MEMORY table actually corresponds to a disk file, the format is .frm, the file only stores the structure of the table, and its data files are stored in the memory, which is conducive to the rapid processing of data and improve the efficiency of the entire table. MEMORY type table access is very fast, because its data is stored in memory, and the HASH index is used by default, but once the service is closed, the data in the table will be lost
- MERGE: The MERGE storage engine is a combination of a set of MyISAM tables. These MyISAM tables must have exactly the same structure. The MERGE table itself does not store data. You can perform query, update, and delete operations on MERGE tables. These operations are actually internal The MyISAM table is carried out.
Comparison between InnoDB and MyISAM:
- InnoDB is currently the default storage engine, and MyISAM is before mysql5
- In terms of transactions, InnoDB supports transactions, while MyISAM does not support transactions. MyISAM is uncomfortable to recover after a system crash
- In terms of locks, InnoDB is a row-level lock, while MyISAM supports table locks, so InoDB is more efficient in terms of efficiency
- In terms of foreign keys, InnoDB supports foreign keys, while MyISAM does not support foreign keys
- In terms of cluster indexes, B+ numbers are used as indexes, but MyISAM indexes and files are separated, and InnoDB indexes and data are bound together, so InnoDB must have a primary key. If there is no primary key, one will be selected as Primary key
Three, index
1. What is an index?
Simply put, an index is a data structure. The index is to help the establishment of the database MySQL index is very important for the efficient operation of MySQL, and the index can greatly improve the retrieval speed of MySQL. In addition to data, the database system also maintains data structures that meet specific search algorithms. These data structures reference (point to) data in a certain way, so that advanced search algorithms can be implemented on these data structures. This data structure is an index. .
2. Index and B+ Tree
Recalling examples in life, such as looking up the dictionary, looking up the word mysql, do you first go to find m, and then search in order, if you use sequential search for the 26 letters az, then you can find it after 13 searches. If you use binary search, you can find it in a small number of times, but we actually search for the word mysql. Do we search the index and quickly locate the position of m through the index, then if we use a multi-way search tree? Isn't that even faster? The catalog of books, the train schedule of the train station, etc. are all used to filter the final results by constantly narrowing the scope of the target data.
The database is also the same. Most of the database operations are queries, but the data in the database is stored on the disk. After learning the principles of computer composition, you can understand that the disk operation is very time-consuming! The cost of accessing the disk is about 100,000 times that of accessing the memory! Therefore, for the data in the database, you cannot use the AVL tree, because its imbalance may lead to a large number of io operations, resulting in a rapid decline in performance. At this time, B-tree appears (see data structure and algorithm analysis Java language description for details In the section of B tree), B+ tree (a variant of B tree) isHighly controllable multi-path search tree. So that the disk io tree is controlled to a small order of magnitude when searching for data
3.B+ tree
The index in Mysql uses B+ tree. B+ tree is a variant of B tree. BTree is also called multi-way balanced search tree. The characteristics of a BTree with m forks are as follows:
- Each node in the tree contains at most m children.
- Except for the root node and leaf nodes, each node has at least [ceil(m/2)] children.
- If the root node is not a leaf node, it has at least two children.
- All leaf nodes are in the same layer.
- Each non-leaf node is composed of n keys and n+1 pointers, where [ceil(m/2)-1] <= n <= m-1
B+ tree
B+Tree is a variant of BTree. The difference between B+Tree and BTree is:
1). The n-fork B+Tree contains at most n keys, and the BTree contains at most n-1 keys.
2). The leaf nodes of B+Tree store all key information, arranged in order of key size.
3). All non-leaf nodes can be regarded as the index part of the key.
4. B+ tree in Mysql
Reference link
[External link image transfer failed. The source site may have an anti-hotlinking mechanism. It is recommended to save the image and upload it directly (img-2mCf0b9S-1616994232027)(C:\Users\VSUS\Desktop\Notes\MySQL\sqlimage\03.jpg )]
As shown in the figure above, it is a b+ tree. The light blue block is called a disk block. You can see that each disk block contains several data items (shown in dark blue) and pointers (shown in yellow), such as a disk Block 1 contains data items 17 and 35, including pointers P1, P2, P3. P1 represents a disk block smaller than 17, P2 represents a disk block between 17 and 35, and P3 represents a disk block larger than 35. The real data exists in the leaf nodes, namely 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. Non-leaf nodes only store real data, only data items that guide the search direction. For example, 17 and 35 do not really exist in the data table.
The search process of b+ tree:
As shown in the figure, if you want to find data item 29, then first load disk block 1 from the disk to the memory. At this time, an IO occurs. Use binary search to determine that 29 is between 17 and 35 in the memory, and lock disk block 1. Because the memory time is very short (compared to disk IO), the memory time is negligible. The disk block 3 is loaded from the disk to the memory through the disk address of the P2 pointer of disk block 1, and the second IO occurs, 29 in 26 and Between 30, lock the P2 pointer of disk block 3, load disk block 8 to the memory through the pointer, and a third IO occurs. At the same time, a binary search is performed in the memory to find 29, and the query ends, and a total of three IOs. The real situation is that a 3-layer b+ tree can represent millions of data. If millions of data searches only require three IOs, the performance improvement will be huge. If there is no index, each data item will have one IO. , Then a total of millions of IOs are required, which is obviously very expensive.
Fourth, the syntax of the index
4.1 Classification of Indexes
1) Single-value index: that is, an index contains only a single column, and a table can have multiple single-column indexes
2) Unique index: The value of the index column must be unique, but null values are allowed
3) Composite index: that is, an index contains multiple columns
4.2 Create Index
grammar:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
For example: create a single-value index for the name field of the tb_seller table:
mysql> create index idx_tb_seller_name on tb_seller(name);
4.3 View Index
show index from [table_name]
For example: view the index built above
show index from tb_seller;
[External link image transfer failed. The source site may have an anti-hotlink mechanism. It is recommended to save the image and upload it directly (img-cHbIC1qo-1616994232031)(C:\Users\VSUS\Desktop\Notes\MySQL\sqlimage\04.png )]
You can see that there are two indexes. This is because the primary key is created when the table is built. The primary key will be set as the index by default. You can see that key_name is PRIMARY, and Non_unqiue is 0, which means that this field cannot be repeated, and it uses BTREE data. structure. (\G is for better explicitness on Linux)
-
Table: The name of the table where the index is located
-
Non_unique: non-unique index, the index of the primary key is 0, because the primary key can only be unique
-
Key_name: the name of the index, the index can be deleted by this name
-
Seq_in_index: the position of the column in the index, for example, the joint index idx_a_c(a,c) For column a, the Seq_in_index value is 1, and for column c, the Seq_in_index value is 2
-
Column_name: column name
-
Collation: How is the column stored in the index? The index of the B+ tree is always A
-
Cardinality: a very critical parameter, indicating the number of unique values in the indexestimated value, This value should be as close as possible to 1, if it is very small, then you need to consider whether it is necessary to create this index. For example: for the gender field, the result of the query may be 50% of the entire table, then it is not necessary to establish an index, but if the name field is not repeated in the entire table, then it is necessary to establish an index , This value will be used when the index becomes invalid later
-
Sub_part: whether part of the column is indexed
-
How keywords are compressed
-
Null: Is it possible to have a null value
-
Index_type: Index type, B+ type is displayed as BTREE
-
Comment: Comment
4.4 Delete index
drop index index_name on table_name;
For example: delete the index created above
mysql> drop index idx_tb_seller_name on tb_seller;
4.4 Delete index
drop index index_name on table_name;
For example: delete the index created above
mysql> drop index idx_tb_seller_name on tb_seller;