table of Contents
The configuration of the go-redis connection cluster, especially the address array
Three, mechanism interpretation
The configuration of the go-redis connection cluster, especially the address array
Transfer from: https://blog.csdn.net/pengpengzhou/article/details/105559884
client := redis.NewClusterClient(&redis.ClusterOptions{
//-------------------------------------------------------------------------------------------
//集群相关的参数
//集群节点地址,理论上只要填一个可用的节点客户端就可以自动获取到集群的所有节点信息。但是最好多填一些节点以增加容灾能力,因为只填一个节点的话,如果这个节点出现了异常情况,则Go应用程序在启动过程中无法获取到集群信息。
Addrs: []string{"127.0.0.1:7000", "127.0.0.1:7001", "127.0.0.1:7002", "127.0.0.1:7003", "127.0.0.1:7004", "127.0.0.1:7005"},
MaxRedirects: 8, // 当遇到网络错误或者MOVED/ASK重定向命令时,最多重试几次,默认8
//只含读操作的命令的"节点选择策略"。默认都是false,即只能在主节点上执行。
ReadOnly: false, // 置为true则允许在从节点上执行只含读操作的命令
// 默认false。 置为true则ReadOnly自动置为true,表示在处理只读命令时,可以在一个slot对应的主节点和所有从节点中选取Ping()的响应时长最短的一个节点来读数据
RouteByLatency: false,
// 默认false。置为true则ReadOnly自动置为true,表示在处理只读命令时,可以在一个slot对应的主节点和所有从节点中随机挑选一个节点来读数据
RouteRandomly: false,
//用户可定制读取节点信息的函数,比如在非集群模式下可以从zookeeper读取。
//但如果面向的是redis cluster集群,则客户端自动通过cluster slots命令从集群获取节点信息,不会用到这个函数。
ClusterSlots: func() ([]ClusterSlot, error) {
},
//钩子函数,当一个新节点创建时调用,传入的参数是新建的redis.Client
OnNewNode: func(*Client) {
},
//------------------------------------------------------------------------------------------------------
//ClusterClient管理着一组redis.Client,下面的参数和非集群模式下的redis.Options参数一致,但默认值有差别。
//初始化时,ClusterClient会把下列参数传递给每一个redis.Client
//钩子函数
//仅当客户端执行命令需要从连接池获取连接时,如果连接池需要新建连接则会调用此钩子函数
OnConnect: func(conn *redis.Conn) error {
fmt.Printf("conn=%v\n", conn)
return nil
},
Password: "",
//每一个redis.Client的连接池容量及闲置连接数量,而不是cluterClient总体的连接池大小。实际上没有总的连接池
//而是由各个redis.Client自行去实现和维护各自的连接池。
PoolSize: 15, // 连接池最大socket连接数,默认为5倍CPU数, 5 * runtime.NumCPU
MinIdleConns: 10, //在启动阶段创建指定数量的Idle连接,并长期维持idle状态的连接数不少于指定数量;。
//命令执行失败时的重试策略
MaxRetries: 0, // 命令执行失败时,最多重试多少次,默认为0即不重试
MinRetryBackoff: 8 * time.Millisecond, //每次计算重试间隔时间的下限,默认8毫秒,-1表示取消间隔
MaxRetryBackoff: 512 * time.Millisecond, //每次计算重试间隔时间的上限,默认512毫秒,-1表示取消间隔
//超时
DialTimeout: 5 * time.Second, //连接建立超时时间,默认5秒。
ReadTimeout: 3 * time.Second, //读超时,默认3秒, -1表示取消读超时
WriteTimeout: 3 * time.Second, //写超时,默认等于读超时,-1表示取消读超时
PoolTimeout: 4 * time.Second, //当所有连接都处在繁忙状态时,客户端等待可用连接的最大等待时长,默认为读超时+1秒。
//闲置连接检查包括IdleTimeout,MaxConnAge
IdleCheckFrequency: 60 * time.Second, //闲置连接检查的周期,无默认值,由ClusterClient统一对所管理的redis.Client进行闲置连接检查。初始化时传递-1给redis.Client表示redis.Client自己不用做周期性检查,只在客户端获取连接时对闲置连接进行处理。
IdleTimeout: 5 * time.Minute, //闲置超时,默认5分钟,-1表示取消闲置超时检查
MaxConnAge: 0 * time.Second, //连接存活时长,从创建开始计时,超过指定时长则关闭连接,默认为0,即不关闭存活时长较长的连接
})
defer client.Close()especially:
The cluster node address, in theory, just fill in an available node client to automatically obtain all node information in the cluster. But it is best to fill in more nodes to increase disaster tolerance, because if only one node is filled, if there is an abnormal situation on this node, the Go application cannot obtain cluster information during the startup process.
Addrs: []string{"127.0.0.1:7000", "127.0.0.1:7001", "127.0.0.1:7002", "127.0.0.1:7003", "127.0.0.1:7004", "127.0.0.1:7005"},
Redis failover principle
Transfer from: https://blog.csdn.net/tr1912/article/details/81265007
premise
A three-master and three-slave cluster is built as shown in the figure below.
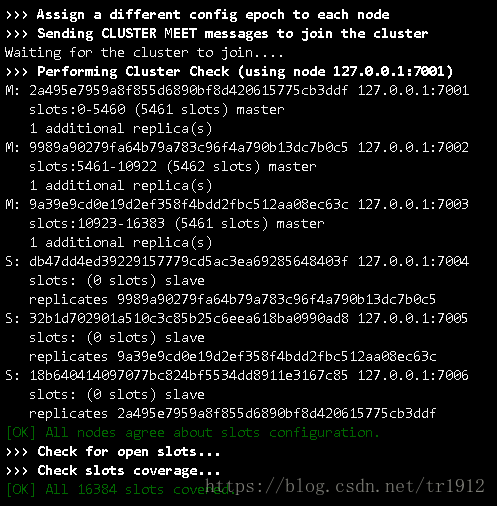
And the cluster is running
1. Fault simulation
We first stop a main service and see what changes:
We stopped the 7002 main server:
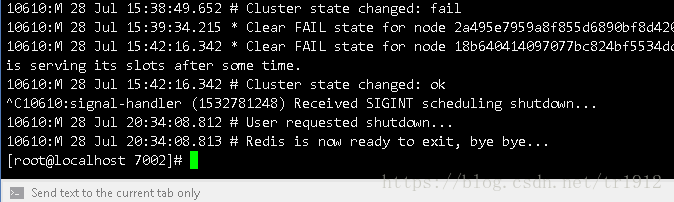
Will see these on his slave 7004 server soon
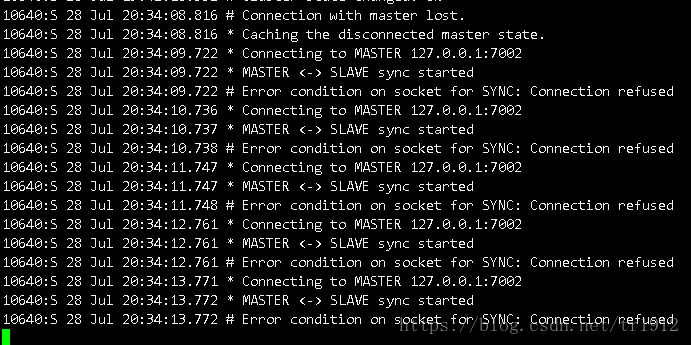
Then other master servers see these:
This means that a node is down, and then his hash slot is recycled, and then a new master is elected

The other slaves just marked the one that was down as an access failure
Then we can see these on the slave of the master machine that was down:

It can be seen that this slave knows the progress of the election and was elected as the master. So far, the whole election of the master is over.
Then we start the original host 7002

Looking at the host 7004, he found that he first marked the host 7002 as reachable, and then synchronized data with it. According to the pid recorded in the data
Other machines just mark it as reachable:

This time we have to stop both the master and slave machines and see what happens:
Let's stop the slave 7002 first:
His host:

Other machines:

Then stop the 7004 host:
Other slaves:

Other hosts:
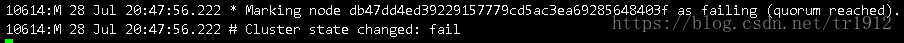
This can be seen, as long as the function of one shard in our node is completely stopped, the entire cluster will be in a state of being unable to connect.

Then we first start the slave node 7002:

7002 has been scanning the master node

The other nodes are the same as when 7002 was restored before, marking him as available.
Start 7004 node at this time:

You can see that 7002 is connected to 7004, and a wave of data is synchronized.
Other nodes indicate that this node has restored the connection, and then the entire cluster is restored:

Three, mechanism interpretation
This is the failover mechanism of redis cluster. Each node of redis communicates through ping/pong, rebroadcasts the information of the slot and node status information, and the fault discovery is also discovered through this action. It is divided into these steps in total:
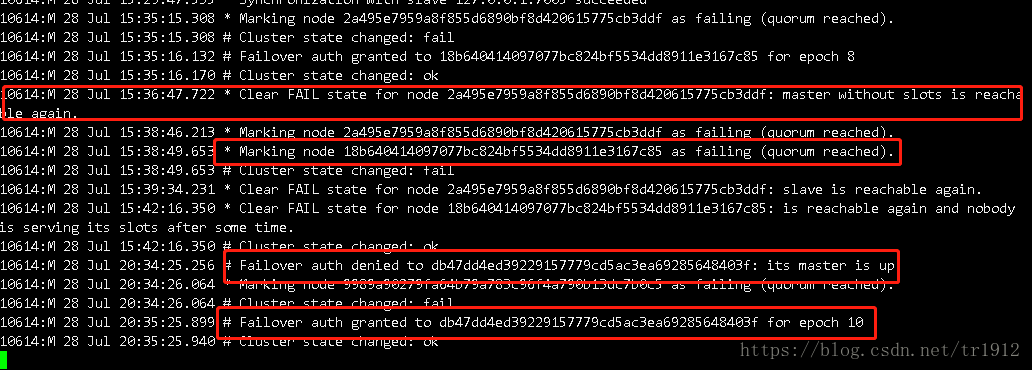
1. Subjective offline: a node thinks that another node is unavailable and becomes offline. This is the first experiment. When 7002 node is disconnected first, 7004 will immediately find 7004 when 7002 is unreachable. The state of thinking.
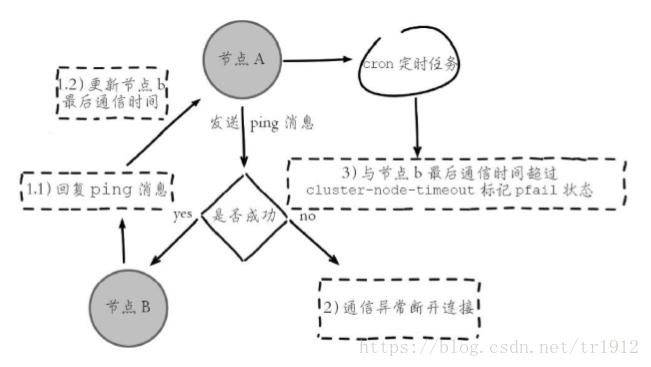
2. Objective offline: refers to the state where a node is marked as truly offline, and multiple nodes in the cluster consider the node to be unavailable. For example, after a while in the first experiment, other nodes will mark 7002 as a failed state.
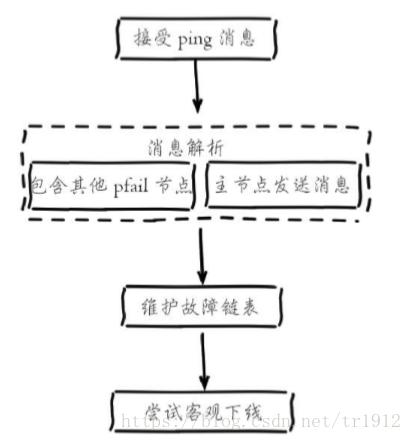

3. Failure recovery: After the failed node becomes objectively offline, if the offline node is the master node holding the slot, it needs to select one of its slave nodes to replace it, so as to ensure the high availability of the cluster. All slave nodes of the offline master node are responsible for failure recovery. When the slave node discovers that its replicated master node enters the objective offline through internal timing tasks, the failure recovery process will be triggered:
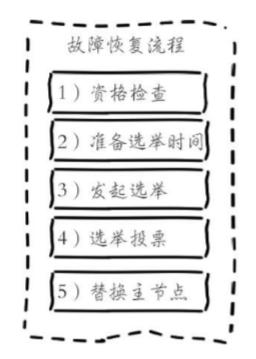
1). Qualification check: Each slave node must check the last disconnection time with the master node to determine whether it is qualified to replace the failed master node. If the disconnection time between the slave node and the master node exceeds cluster-node-time*cluster-slave-validity-factor, the current slave node is not eligible for failover. The parameter cluster-slavevalidity-factor is used for the validity factor of the slave node, and the default is 10.
2). Preparation for election time: When the slave node is eligible for failover, the time for triggering the failure election is updated, and the follow-up process can only be executed after the time is reached. The reason why the delayed trigger mechanism is adopted here is mainly to support the priority issue by using different delayed election times for multiple slave nodes. The larger the replication offset, the lower the delay of the slave node, so it should have a higher priority to replace the failed master node. All the slave nodes with the largest copy offset will trigger the failure election process in advance.
After the master node b enters the objective offline, its three slave nodes set the delay election time according to its own replication offset. For example, the node with the largest replication offset, slave b-1, delays execution for 1 second to ensure the slave node with low replication delay Give priority to initiating elections.

3). Initiate an election :
When the slave node timing task detection reaches the failure election time (failover_auth_time), the election process is as follows:
(1). Update configuration epoch: The configuration epoch is an integer that only increases and does not decrease. Each master node maintains a configuration epoch (clusterNode.configEpoch) to indicate the version of the current master node. The configuration epochs of all master nodes are not equal. The slave node will copy the configuration epoch of the master node. The entire cluster maintains a global configuration epoch (clusterState.current Epoch), which is used to record the maximum version of the configuration epoch of all master nodes in the cluster. Execute the cluster info command to view the configuration epoch information. As long as an important critical event occurs in the cluster, the number of epochs will increase, so when choosing a slave, you need to choose a slave with the largest number of epochs.
(2). Broadcast election messages: broadcast election messages (FAILOVER_AUTH_REQUEST) in the cluster and record the status of the messages that have been sent to ensure that the slave node can only initiate one election within a configuration epoch. The content of the message is like a ping message, but the type is changed to FAILOVER_AUTH_REQUEST.
4). Election voting: Only the master node holding the hash slot can participate in the voting, and each master node has the right to vote. If there are N master nodes in the cluster, then as long as one slave node obtains N/2+1 The ballot is considered a winner.
Ps. The failed master node is also counted in the number of votes. Assuming that the scale of nodes in the cluster is 3 masters and 3 slaves, there are 2 master nodes deployed on one machine. When this machine goes down, the slave nodes cannot collect 3/2+1 votes from the master node will cause the failover to fail. This question also applies to the fault discovery link. Therefore, when deploying a cluster, all master nodes need to be deployed on at least 3 physical machines to avoid single point problems.
Vote invalidation: Each configuration epoch represents an election cycle. If the node does not obtain a sufficient number of votes within the cluster-node-timeout*2 after the start of voting, the election will be invalidated. The slave node increments the configuration epoch and initiates the next round of voting until the election is successful.
5). Replace the master node
When enough votes are collected from the node, the operation of replacing the master node is triggered:
- The current slave node cancels replication and becomes the master node.
- Execute the clusterDelSlot operation to cancel the slots responsible for the failed master node, and execute clusterAddSlot to delegate these slots to itself.
- Broadcast its own pong message to the cluster to notify all nodes in the cluster that the current slave node has become the master node and has taken over the slot information of the failed master node.