Needless to say, the importance of neural networks will go directly to the topic.
Main article to explain some of the basic neural network algorithms and programming (such as perception, a cross entropy, gradient descent , etc.) , gradually deepened, and finally teach you to build a simple neural network (points 4-5 times ready to finish, please continue attention). If the reader is Xiaobai and does not understand neural networks, please Baidu by yourself.
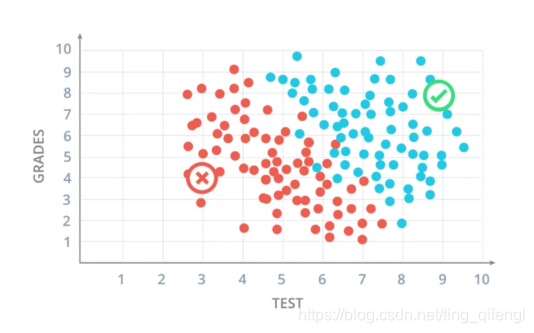
Simply put, neural networks are actually classification problems. For example, find a best straight line to distinguish the red data and blue data in the figure below. Of course this is just a simple linear classification problem. As the number of network layers increases, neural networks can handle many complex nonlinear problems.

This article mainly introduces the basics of neural networks-perceptron and python code implementation
First, let's look at a simple classification problem. Suppose we are an admissions officer of a college, and our main job is to accept or reject students who apply, and there are two assessment information: test scores and usual grades during the school period (again! Scores are the lifeblood of students! ). The picture below shows the two results of the students admitted by the school over the years. Blue dots indicate admitted students, and red dots indicate unaccepted students. Will students with a test score of 7 and a grade score of 6 be admitted?
In fact, the admission data of students over the years can be easily distinguished by the following straight line. Most students below the line are rejected, and most students above the line are admitted. Call this straight line our model, and the error of this model will not be considered for the time being. Going back to the above question, it can be seen that the point (7, 6) is located above the straight line, and it can be relatively certain that the student will be admitted.
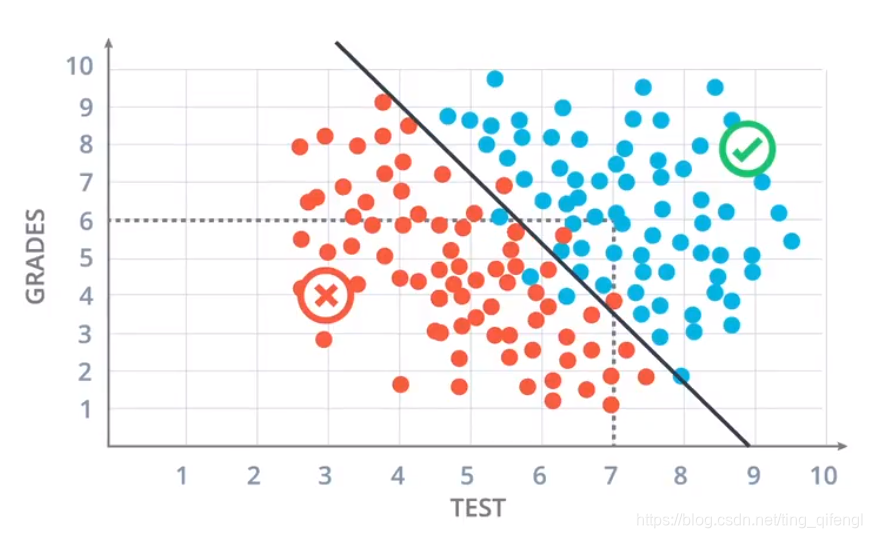
The above problem will be transformed into a mathematical problem below.
Record the abscissa variable as and the ordinate variable as
. Suppose we already know the equation of this line is
. That is, the student's score is score=2*test+grades-18, and then enter the student's two scores, if the score is positive (greater than or equal to 0), then accept, otherwise reject (this step is called prediction).

Then extended to the general problem of linear equations can be expressed as: . It is abbreviated as the vector method
. Among them are
called weights and
biases.
Mark the content we want to predict with a label , and
take 0 (red dot) or 1 (blue dot). Use labels to
indicate prediction results, and
take 0 (reject) or 1 (accept). Our goal is to get as
close as possible
. The closer it is, the better our straight line equation is, that is, the better the classification effect.

So if we add another evaluation basis: class ranking, what should we do? bingo! We need to do it in three-dimensional space, that is, to find a plane to
divide the data. If there are n dimensions, then it is looking for n-1 dimensional hyperplane partition data.
And
still the same as above.

Next, build the basis of neural network-perceptron. The perceptron is to encode the above linear equation to form a small figure. As shown in the figure below, the deviation is considered here
, so it will be
considered as part of the input.

Then the perceptron composed of n-dimensional data is shown in the figure below. To
is the input node,
to
is the edge weight, and
is the bias unit. The final output result is 0 or 1. A step function is used here.


So a perceptron can be completely represented by the following figure. That is to say it is regarded as a combination of nodes, the first node calculates the input of the equation and passes the calculation result to the step function. The second node outputs the prediction result according to the calculation result.

The above figure is represented by symbols:

Since the structure of the perceptron is more similar to that of human neurons, the network formed by the perceptron is called a neural network.

After talking about the perceptron, then there is an exercise to warm up: use the perceptron to implement the "and" operation.

You can try to write it yourself first.
The code is as follows (python), pandas library needs to be installed:
import pandas as pd
# TODO: Set weight1, weight2, and bias
weight1 = 1.0
weight2 = 1.0
bias = -1.5
# DON'T CHANGE ANYTHING BELOW
# Inputs and outputs
test_inputs = [(0, 0), (0, 1), (1, 0), (1, 1)]
correct_outputs = [False, False, False, True]
outputs = []
# Generate and check output
for test_input, correct_output in zip(test_inputs, correct_outputs):
linear_combination = weight1 * test_input[0] + weight2 * test_input[1] + bias
output = linear_combination > 0
is_correct_string = 'Yes' if output == correct_output else 'No'
outputs.append([test_input[0], test_input[1], linear_combination, output, is_correct_string])
# Print output
num_wrong = len([output[4] for output in outputs if output[4] == 'No'])
output_frame = pd.DataFrame(outputs, columns=['Input 1', ' Input 2', ' Linear Combination', ' Activation Output', ' Is Correct'])
if not num_wrong:
print('Nice! You got it all correct.\n')
else:
print('You got {} wrong. Keep trying!\n'.format(num_wrong))
print(output_frame.to_string(index=False))Of course, the perceptron can also implement "or" operations, "not" operations, etc. You can try it yourself.
Having introduced so much, you may have questions: How can a computer find a suitable linear equation? We will answer this question in the next section.
If you have any questions, please ask! ! !