kube-scheduler source code analysis
opsdev Wang Xigang 360 cloud computing
Heroine declaration
This article takes you to understand one of the important components deployed on our HULK container service master node, the interpretation of kube-scheduler's operating mechanism and core code analysis, and is a reference for students who want to read and learn the Kubernetes source code. This article was first published on opsdev, and the reprint has been authorized by the author.
PS: Rich first-line technology and diversified forms of expression are all in the " HULK first-line technology talk ", please pay attention!
Preface
The source code involved in this article is Kubernetes 1.9, and the git commit id is 925c127ec. The first half of this article explains the principle of the scheduler, and the second half analyzes the source code of the scheduler.
1
Basic principles of kubernetes scheduler
The kubernetes scheduler is deployed as a separate process on the master node. It will watch the kube-apiserver process to find the Pod whose PodSpec.NodeName is empty, and then schedule the Pod to the appropriate Node according to the specified algorithm. This process is also called binding. Set (Bind). The input of the scheduler is the information of the Pod and Node that need to be scheduled, and the output is the Node with the optimal conditions selected by the scheduling algorithm, and the Pod is bound to this Node. As shown below:
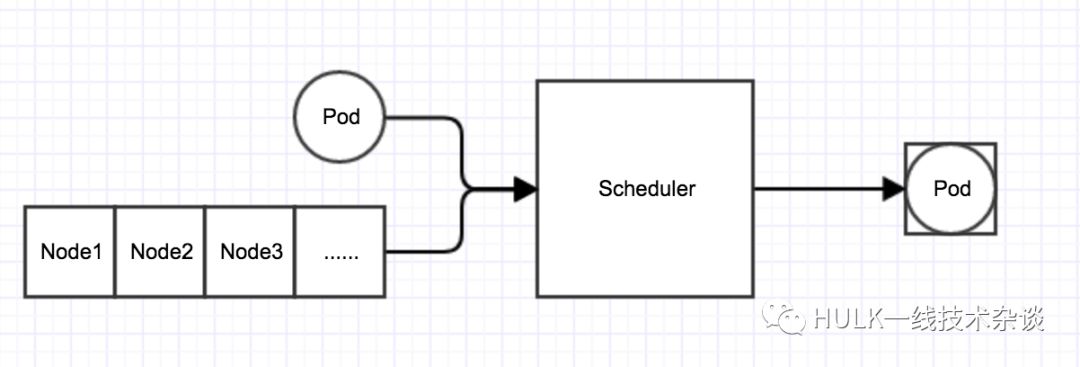
The scheduler scheduling algorithm is divided into two stages:
Predicates
Filter out Nodes that do not meet Policies according to the Predicates strategy.
Priorities
For the remaining Nodes after Predicates, an optimal Node needs to be selected through the Priorities strategy, and the Pod is bound to the Node. Describe in detail according to the following scheduling diagram:
1. First, the scheduler filters out non-compliant Nodes according to the predicates set. For example, if PodSpec specifies resource requests, the scheduler will filter out Nodes that do not have enough resources.
2. Secondly, the scheduler will select an optimal Node from the Nodes filtered from the predicates based on the priority functions set.
Algorithm implementation:
For each Node, priority functions will calculate a number between 0-10, indicating the appropriateness of the Pod to the Node, where 10 means very suitable, 0 means inappropriate, and each function in the priority functions set has one Weight, the final value is the product of weight and priority functions, and the weight of a node is the sum of the results of all priority functions. For example, there are two priority functions: priorityFunc1 and priorityFunc2, and the corresponding weights are weight1 and weight2 respectively, then the final score of NodeA is:

3. In the end, the Node with the highest score wins (if there are multiple Nodes with the same score, a Node will be randomly selected as the final Node).

2
kubernetes scheduler source code analysis
Code structure of scheduler

k8s.io/kubernetes/plugin/cmd/scheduler.go is the program entry file (main.go)
k8s.io/kubernetes/plugin/cmd/kube-scheduler/app/server.go contains the basic configuration items of the scheduler
Except for the entry function, the specific logic implementation of the scheduler is in the k8s.io/kubernetes/plugin/pkg/scheduler directory, so I won't introduce them one by one here.
Specific implementation of scheduler

The above sequence diagram is the specific implementation logic of the entire scheduler. Next, analyze the source code of the scheduler according to this sequence diagram.
NewSchedulerCommand creates a scheduler command line instance to parse and verify the scheduler's command line parameters and contains the function definition of the entry function Run of the scheduler program.
command.Execute() will execute the options.Run method in the command line instance.
The following operations are mainly carried out in options.Run:
loadConfigFromFile Load scheduler configuration file information.
NewSchedulerServer creates an instance of the scheduler server, and initializes the scheduler server with the scheduler configuration parameters, such as:
createClients creates a series of clients, such as connecting k8s client, client and event client for scheduler selection.
makeLeaderElectionConfig generates Leader Election configuration information (the scheduler has done HA and can run multiple instance processes at the same time, but only one can work normally. If the main scheduler hangs, the election will be re-elected).
makeHealthzServer initializes the healthz server for health check.
makeMetricsServer initializes the metrics server for prometheus performance monitoring.
SchedulerServer.Run Starts SchedulerServer, which is used to monitor whether there are Pods to be scheduled, and perform corresponding scheduling work. Specific code implementation:

SchedulerConfig() creates Scheduler Config, the key functions of which are NewConfigFactory and CreateFromProvider.
NewConfigFactory defines a podQueue to store Pods that need to be scheduled. Whenever a new Pod is created, the Pod will be added to the queue.
CreateFromProvider creates a scheduler configuration information based on the algorithm provider name. Among them, GetAlgorithmProvider obtains the specified provider according to the provider name.

The default provider used by scheduler is DefaultProvider. It mainly implements the following data structure:

AlgorithmProviderConfig This data structure contains a set of pre-selected and preferred related algorithm keys (an algorithm corresponds to a key, key is the name of the algorithm, value is the specific implementation of the algorithm funtion), and these algorithms are registered in scheduler/algorithmprovider/defaults/defaults.go Register in the init() method of the file (implementation uses the factory pattern). If you want to learn more about the pre-selection and optimization algorithm, please refer to the official document:
https://github.com/kubernetes/community/blob/master/contributors/devel/scheduler_algorithm.md
Then go on: Get the key of the preselected and preferred algorithm set associated with the provider through GetAlgorithmProvider. Then by calling CreateFromKeys (pre-selected and preferred Key as a parameter) to obtain the specific implementation (funtion) of the pre-selected and preferred algorithm, initialize the NewGenericScheduler instance, and return the final scheduler configuration information.
NewFromConfig creates a scheduler by Scheduler Config.
Start up the healthz server
Start up the metrics server Start the metrics service for Prometheus to capture performance monitoring data.
LeaderElection If you specify the election method to start the scheduler, use this method to execute the scheduler. (Use CallBack to execute the Run method. If the main scheduler has a problem, it will also specify an elegant processing function to handle it).
Now comes the logic of scheduler's real work. Every time a Pod is scheduled, the following Scheduler.Run() will be executed. The specific code is as follows:

WaitForCacheSync() synchronizes the latest data to the SchedulerCache cache.
scheduleOne() The overall logic of scheduling Pod. The specific implementation can be seen in the following code:

NextPod() gets an unbound Pod from the PodQueue.
schedule(pod) Execute the schedule corresponding to Algorithm for preselection and optimization. The interface is defined as follows:

Schedule mainly includes the following important methods:
nodeLister.List() Get the list of available Nodes.
findNodesThatFit() performs preselection.
PrioritizeNodes() is prioritized.
selectHost() If multiple Nodes with the same score are selected, a Node is randomly selected.
assume() updates the status of the Pod in SchedulerCache, marks the Pod as scheduled, and updates it to NodeInfo.
bind() calls the kube-apiserver API, binds the Pod to the selected Node, and then Kube-apiserver writes the metadata into etcd. The interface is defined as follows:

This completes the process of binding a Pod to Node.
3
to sum up
As a separate process on the Kubernetes master, kube-scheduler provides scheduling services. The master specifies the address of kube-api-server to watch Pod and watch Node and calls the api server bind interface to complete the Bind operation of Node and Pod.
kube-scheduler maintains a FIFO-type PodQueue cache (in fact, there is also a PriorityQueue used to specify the priority of the Pod, which needs to be turned on by specifying the parameter, and the default is the FIFO queue). The newly created Pod will be watched by the ConfigFactory and added to In the PodQueue, each time the PodQueue is scheduled, NextPod() a Pod to be scheduled from the PodQueue.
After obtaining the Pod to be scheduled, execute the Algorithm Provider to configure the Schedule method of Algorithm for scheduling. The entire scheduling process is divided into two key steps: Predicates and Priorities, and finally a Node that is most suitable for the Pod is selected.
Update the status of the Pod in SchedulerCache (AssumePod), mark the Pod as scheduled, and update it to NodeInfo.
Call the Bind interface of the api server to complete the Bind operation of Node and Pod. If Bind fails, delete the Assumed Pod from the SchedulerCache in the previous step .