What is a partition ? ?
Decompose a table into multiple blocks for operation and storage, thereby reducing the data of each operation and improving performance.
Logically speaking, there is only one table, but on Wulu, this table may consist of multiple partitions.
What can partitions do ? ?
Split data can have multiple different physical paths
Can store more data;
Improve the read and write speed of each partition;
Involving aggregation operations such as sum and count, parallel operations can be easily performed.
Partition type :
Range partition: based on a given continuous range of column values, multiple rows are allocated to partitions
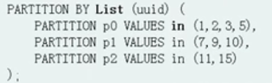
list partition:
Hash partition: select partition based on the return value of the defined expression
Key partition: similar to hash partition, the mysql server provides its own hash function
Create a partition :
1. Range partition
2. List partition
3. Hash partition
Specify the number of partitions that the partitioned table will be divided into
4. Key partition
Why sub-database and sub-table ? ?
Master-slave replication + read-write separation can achieve high data availability, but cannot solve the large-scale concurrent write problem (innodb row lock), and a single server due to resource limitations leads to the amount of data and data processing capacity that the database can carry not tall.
Advantages of sub-database and sub-table :
Reduce the impact of locks on queries when incremental data is written;
Common queries reduce the number of records that need to be scanned, so that the number of retrieval rows required for single-table queries is reduced, and disk IO is reduced;
Solve the limitation of the largest file in the disk system;
What is sub-library ?
Sub-database is also called "vertical segmentation", which means that the tables originally stored in one database are split and stored in multiple databases. The tables are usually divided according to functional modules and closeness of relationships, and deployed on different libraries. If the database is caused by a large amount of data due to too many tables, and the business logic of the project is clearly divided and has low coupling, the first choice is to sub-database.
Advantages of sub-library: easy to implement;
Disadvantages of sub-library: it is not conducive to cross-library operations, for example, the tables of two libraries cannot be connected
What is a sub-table ?
Split table is also called "horizontal split", which is to split the data of a table into multiple copies according to certain business rules or logic, and store them in multiple tables with the same structure; these multiple tables can exist one to one. Multiple libraries. The sub-table is also divided into "vertical segmentation" and "horizontal segmentation".
Vertical sub-table :
The content that originally exists in one table is artificially divided into multiple tables.
Level score table :
Also called " data fragmentation ". It is to copy a table into different tables with the same table structure, and then divide the data according to certain rules and store them in these tables respectively, so as to ensure that the capacity of a single table will not greatly improve performance. (Recommendation: The data volume of a single meter cannot exceed 500W)


The principle and idea of the level score table:
Navigation rules --- According to different situations, direct the same SQL to different libraries or tables.
Basic realization idea:
1. Resolve routing:
According to the business function or sql analysis, obtain the data source and the table to be accessed
2. Execute sql on the data source and table respectively
3. If it involves returning the result set, you need to merge the result set and perform secondary processing as needed, such as sorting and paging
4. If you need transactions, you must consider whether to use distributed transactions, or implement two-phase commit yourself, or use compensatory business processing methods
Achievable levels:

Difficulties in the realization of the level score table:
The implementation of horizontal sub-tables faces a series of problems, such as: segmentation strategy, database node routing, table routing, global primary key production, cross-border store sorting, grouping, paging, table management, multi-data source transaction processing, database expansion, etc.
Use mycat to implement mysql sub-database sub-table :
mycat introduction :
mycat is an open source distributed database system and a server that implements the mysql protocol.
Front-end users can think of it as a database proxy. The backend can communicate with multiple mysql servers using the mysql native protocol, or communicate with most mainstream database servers using the JDBC protocol.
The core is sub-database sub-table, that is, a large table is horizontally divided into N small tables.
Build mycat :
- Download mycat
http://mycat.sourceforge.net/- Install and modify the configuration file
Download the installation package and unzip it
Schematic diagram:
For example, use mycat to implement horizontal scoring of the test1 table, and store the data on the nodes of 192.168.0.3 (2 nodes) and 192.168.0.4 (1 node) respectively.
the term:
Schema logic library:
The database defined in mycat exists logically but does not exist physically. Mainly for the concept provided by vertical segmentation.
table logical table:
The table defined in Mycat. It exists logically but does not exist physically. It is mainly for the concept of horizontal segmentation.
dataHost:
The host address of the physical MySQL storage. You can use the host name, IP, and domain name definitions.
dataNode data node:
Configure the physical database. The physical node where the data is stored. That is the database.
Fragmentation rules:
That is, control how data accesses the physical database and table.

Configure mycat :
Mycat is divided into 3 important configuration files, namely schema.xml server.xml rule.xml
1 、 schema.xml
Set up the overall schema split task + node configuration information + table split information + underlying mysql login information
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">- -schema Task Configuration
<schema name="mycat" checkSQLschema="false" sqlMaxLimit="1000">
--Table test1 split nodes and split rules
<table name="test1" primaryKey="ID" dataNode="dn1,dn3,dn2" rule="auto-sharding-long"/>
--Table test2 split node and split rule <table name="test2" primaryKey="ID" dataNode="dn2,dn4" rule="rule1"/>
</schema>- the node information of the node configuration data, host data
<dataNode name="dn1" dataHost="192.168.0.3" database="db1" />
<dataNode name="dn2" dataHost="192.168.0.3" database="db2" />
<dataNode name="dn3" dataHost="192.168.0.4" database="db3" />
<dataNode name="dn4" dataHost="192.168.0.4" database="db4" />--底层mysql登录方式
<dataHost name="192.168.0.3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat><writeHost host="mysql1" url="192.168.0.3:3306" user="root"
password="123456"></writeHost>
</dataHost>--底层mysql登录方式
<dataHost name="192.168.0.4" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat><writeHost host="mysql2" url="192.168.0.4:3306" user="root"
password="123456">
</writeHost>
</dataHost></mycat:schema>
2、server.xml
This file configures global firewall information
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<!-- 1 to enable real-time statistics, 0 to disable-- >
<property name="useSqlStat">0</property>
<!-- 1 is to turn on the full overtime consistency test, 0 is to turn off -->
<property name="useGlobleTableCheck">0</property>
<property name= "sequnceHandlerType">2</property>
<property name="processorBufferPoolType">0</property>m-vy288c43d05418f4
<property name="handleDistributedTransactions">0</property>
<!--off heap for merge/order/group /limit 1 open 0 close -->
<property name="useOffHeapForMerge">1</property><!--单位为m -->
<property name="memoryPageSize">1m</property><!--单位为k-->
<property name="spillsFileBufferSize">1k</property><property name="useStreamOutput">0</property>
<!--单位为m -->
<property name="systemReserveMemorySize">384m</property><!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<firewall>
<whitehost>
<host host="127.0.0.1" user="root"/>
<host host="localhost" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall><user name="root">
<property name="password">123456</property>
<property name="schemas">mysql</property>
</user>
</mycat:server>
3、rule.xml
This configuration file configures the split rule of the table and the configuration of the underlying file of the split rule.
Fragmentation rules:
<?xml version="1.0" encoding="UTF-8"?>
<--c language governing permissions and - limitations under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">--表test1拆分规则配置
<tableRule name="test1">
<rule>
<columns>ID</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>--Table test2 split rule configuration
<tableRule name="test2">
<rule>
<columns>ID</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule><function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">2</property>
<property name="virtualBucketTimes">160</property>
</function><function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property>
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function><--范围约定--->
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
autopartition-long.txt
0-5000000=0
5000001-10000000=1
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
or
0-10000000=0
10000001-20000000=1
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function><function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
Fixed shard hash algorithm
If you need to evenly allocate settings: evenly divide into 4 fragments, partitionCount*partitionLength=1024
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">4</property>
<property name="partitionLength">256</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
4. The underlying mysql configuration
Mysql needs to grant login permissions to the host where mycat is located
5. Test
(1) Open mycat
(2) Log in to mysql on the host where mycat is located
(3) Insert three pieces of data, select all the data on the host where mycat is located
Since the test1 table uses the "range convention" split rule, then
The results in 192.168.0.3 are as follows: (1, aa), (5000000, aa)
The result in 192.168.0.4 is as follows (500001,aa)


springboot integrates mycat :