COW (CopyOnWrite, copy-on-write) mechanism is a lock-free fast data access mechanism. It is read by multiple threads in the scenario and the pressure of the read operation is relatively high. The write operation only occurs in one thread, and the number of writes is related to the number of reads. The comparison is relatively small, which means that COW is used in an environment where there is only a read-write conflict, no write-write conflict, and high read pressure.
The specific process is explained by the operation process of BtrFS on file system metadata.
The file system seems to be a relatively stable part of the kernel. For many years, people have been using ext2/3. With its excellent stability, the ext file system has become the de facto Linux standard file system. In recent years, ext2/3 has exposed some scalability problems, so ext4 was born. The dev version of ext4 is integrated in the Linux2.6.19 kernel released in 2008. When the 2.6.28 kernel was released, ext4 ended the development version and began to accept users. It seems that ext will become synonymous with Linux file system. However, when you read many articles about ext4, you will find that btrfs is mentioned invariably, and you think that
ext4 will be a transitional file system. Theodore Tso, the author of ext4, also praised btrfs and believes that btrfs will become the next-generation Linux standard file system. Oracle, IBM, Intel and other vendors have also shown great attention to btrfs and invested capital and manpower. Why is btrfs so popular? This is the question that this article wants to discuss first.
Kevin Bowling[1] has an article introducing various file systems. In his opinion, file systems such as ext2/3 belong to the "classical period". The new era of file system was initiated by Sun's ZFS in 2005. ZFS stands for "last word in file system", which means that there is no need to develop other file systems. ZFS does bring a lot of new concepts, and it is an epoch-making work for file systems.
If you compare the features of btrfs, you will find that btrfs and ZFS are very similar. Maybe we can think of btrfs as the Linux community's response to ZFS. Since then, Linux finally has a file system comparable to ZFS.
You can see a list of btrfs features on the homepage of btrfs[2]. I made my own claim and divided the list into four parts.
The first is scalability-related features. The most important design goal of btrfs is to deal with the scalability requirements of large machines for file systems. Features such as Extent, B-Tree and dynamic inode creation ensure that btrfs still has excellent performance on large machines, and its overall performance will not decrease with the increase of system capacity.
The second is the characteristics related to data integrity. The system faces unexpected hardware failures. Btrfs uses COW transaction technology to ensure the consistency of the file system. btrfs also supports checksum to avoid silent corrupt. The traditional file system cannot do this.
The third is the characteristics related to multi-device management. Btrfs supports the creation of snapshots (snapshot) and clones (clone). Btrfs can also easily manage multiple physical devices, making traditional volume management software redundant.
Finally, there are other features that are difficult to categorize. These features are relatively advanced technologies that can significantly improve the time/space performance of the file system, including delayed allocation, storage optimization of small files, and directory indexing.
B-Tree
All metadata in the btrfs file system is managed by BTree. The main advantage of using BTree is that search, insert and delete operations are very efficient. It can be said that BTree is the core of btrfs.
Blindly boasting that BTree is very good and efficient may not be convincing, but if you spend a little time looking at the implementation of metadata management in ext2/3, you can reflect the advantages of BTree.
One problem that hinders the scalability of ext2/3 comes from the way its directories are organized. A directory is a special file, and its content is a linear table in ext2/3. As shown in Figure 1-1 [6]:
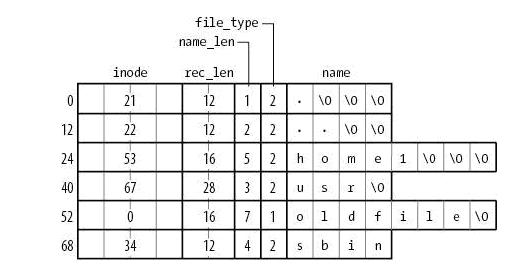
Figure 1 shows the contents of an ext2 directory file, which contains four files. They are "home1", "usr", "oldfile" and "sbin". If you need to find the directory sbin in this directory, ext2 will traverse the first three items until it finds the string sbin.
This structure is a relatively intuitive design when the number of files is limited, but as the number of files in the directory increases, the time to find files will increase linearly. In 2003, ext3 designers developed a directory index technology to solve this problem. The data structure used by the directory index is BTree. If the number of files in the same directory exceeds 2K, the i_data field in the inode points to a special block. The directory index BTree is stored in this block. The search efficiency of BTree is higher than that of linear table,
But designing two data structures for the same metadata is always not very elegant. There are many other metadata in the file system, and the unified BTree management is a very simple and beautiful design.
All metadata in Btrfs is managed by BTree, which has good scalability. Different metadata in btrfs is managed by different trees. In the superblock, there are pointers to the roots of these BTrees. as shown in picture 2:
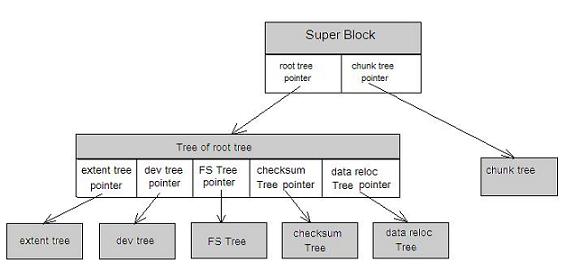
FS Tree manages file-related metadata, such as inode, dir, etc.; Chunk tree manages equipment, each disk device has an item in the Chunk Tree; Extent Tree manages disk space allocation, and btrfs allocates a segment of disk space every time. The disk space information is inserted into the Extent tree. Query Extent Tree will get free disk space information; Tree of tree root stores many root nodes of BTree. For example, every time a user creates a snapshot, btrfs will create an FS Tree. In order to manage all trees, btrfs
uses Tree of tree root to save the root nodes of all trees; checksum Tree saves the checksum of data blocks.
Extent-based file storage
Many modern file systems use extent instead of block to manage disks. Extents are some continuous blocks, and an extent is defined by the initial block plus the length.
Extent can effectively reduce metadata overhead. In order to further understand this problem, let's take a look at the negative example in ext2.
ext2/3 uses block as the basic unit and divides the disk into multiple blocks. In order to manage disk space, the file system needs to know which blocks are free. Ext uses bitmap for this purpose. Each bit in the bitmap corresponds to a block on the disk. When the corresponding block is allocated, the corresponding bit in the bitmap is set to 1. This is a very classic and clear design, but unfortunately when the disk capacity becomes larger, the space occupied by the bitmap itself will also become larger. This leads to scalability problems. As the storage device capacity increases, the space occupied by bitmap metadata also increases. And people hope that no matter how the disk capacity increases, metadata should not increase linearly, so that such a design is scalable.
The following figure compares the difference between block and extent:
Figure 3. btrfs with extent and ext2/3 with bitmap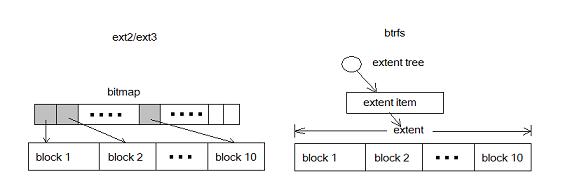
In ext2/3, 10 blocks require 10 bits to represent; in btrfs, only one metadata is required. For large files, extent shows more excellent management performance.
Extent is the smallest unit for btrfs to manage disk space and is managed by the extent tree. Btrfs allocates data or metadata to query the extent tree in order to obtain free space information.
Dynamic inode allocation
In order to understand dynamic inode allocation, ext2/3 is still needed. The following table lists the limitations of the ext2 file system:
| limit | |
| Maximum number of files | File system space size V/8192, such as a 100G file system, the maximum number of files that can be created is 131072 |
Figure 4 shows the disk layout of ext2:
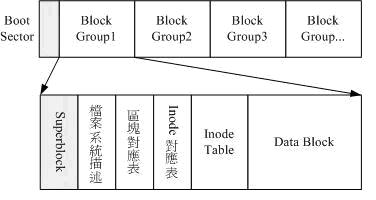
In ext2, the inode area is fixed in advance and its size is fixed. For example, in a 100G partition, the inode table area can only store 131072 inodes, which means that it is impossible to create more than 131072 files, because each file Both must have a unique inode.
In order to solve this problem, inodes must be allocated dynamically. Each inode is just a node in the BTree, and users can insert new inodes at will without restriction, and its physical storage location is dynamically allocated. Therefore, btrfs does not limit the number of files.
Optimized support for SSD
SSD is the abbreviation of Solid State Disk. In the past few decades, the development of CPU/RAM and other devices has always followed Moore's Law, but the read and write rate of hard disk HDD has not developed by leaps and bounds. Disk IO is always the bottleneck of system performance.
SSD adopts flash memory technology, there are no mechanical devices such as disk heads inside, and the reading and writing speed is greatly improved. Flash memory has some characteristics different from HDD. Flash must be erased before writing data; secondly, flash has a certain limit on the number of erase operations. At the current level of technology, the same data unit can be erased at most about 1 million times, so In order to extend the life of the flash, write operations should be averaged to the entire flash.
SSD implements distributed write operation technologies such as wear leveling in the microcode inside the hardware, so the system does not need to use special MTD drivers and FTL layers. Although SSD has made a lot of efforts at the hardware level, it is still limited after all. Optimizing the file system for the characteristics of the SSD can not only increase the service life of the SSD, but also improve the read and write performance. Btrfs is one of the few file systems optimized specifically for SSDs. btrfs users can use the mount parameter to turn on the special optimization processing for SSD.
Btrfs' COW technology fundamentally avoids repeated write operations to the same physical unit. If the user turns on the SSD optimization option, btrfs will optimize the underlying block space allocation strategy: aggregate multiple disk space allocation requests into a continuous block with a size of 2M. A large block of continuous address IO can make the microcode solidified in the SSD better read and write optimization, thereby improving IO performance.
Features related to data consistency
COW affairs
To understand COW transactions, you must first understand the terms COW and transactions.
What is COW?
The so-called COW means that every time the disk data is written, the updated data is first written into a new block. When the new data is successfully written, the related data structure is updated to point to the new block.
What is a transaction?
COW can only guarantee the atomicity of a single data update. However, many operations in the file system need to update multiple different metadata. For example, to create a file, you need to modify the following metadata:
- Modify the extent tree, allocate a section of disk space
- Create a new inode and insert it into the FS Tree
- Add a directory item and insert it into the FS Tree
If any step fails, the file cannot be created successfully, so it can be defined as a transaction.
The following will demonstrate a COW transaction.
A is the root node of the FS Tree, and the new inode information will be inserted into node C. First, btrfs inserts the inode into a newly allocated block C', and modifies the upper node B to point to the new block C'; modifying B will also trigger COW, and so on, triggering a chain reaction until the topmost Root A. When the whole process is over, the new node A 'becomes the root of the FS Tree. But the transaction is not over at this time, and the superblock still points to A.
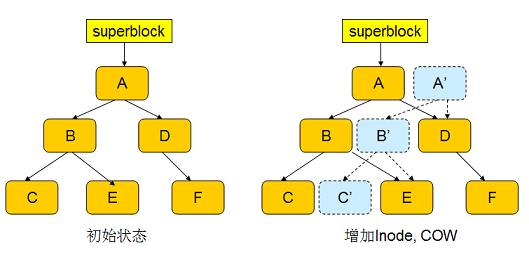
Next, modify the directory entry (E node), which also triggers this process, thereby generating a new root node A''.
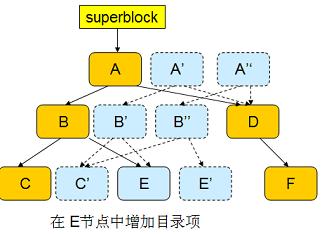
At this point, both the inode and the directory entry have been written to the disk, and the transaction can be considered to have ended. btrfs modifies superblock to point to A'', as shown in the following figure:
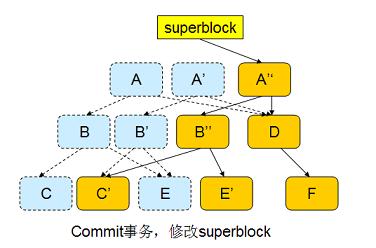
The COW transaction can ensure the consistency of the file system, and there is no need to execute fsck after the system Reboot. Because the superblock either points to the new A'' or points to A, whichever is consistent data.
Checksum
Checksum technology guarantees the reliability of data and avoids silent corruption. Due to hardware reasons, the data read from the disk will be wrong. For example, the data stored in block A is 0x55, but the read data becomes 0x54. Because the read operation did not report an error, this error cannot be detected by the upper-level software.
The solution to this problem is to save the checksum of the data and check the checksum after reading the data. If it does not match, you know that there is an error in the data.
ext2/3 has no checksum and trusts the disk completely. Unfortunately, disk errors always exist, not only on cheap IDE hard drives, but expensive RAID also has silent corruption issues. And with the development of storage networks, even if the data is read correctly from the disk, it is difficult to ensure that it can safely traverse network devices.
btrfs will read its corresponding checksum while reading data. If the data finally read from the disk is not the same as the checksum, btrfs will first try to read the mirror backup of the data. If the data does not have a mirror backup, btrfs will return an error. Before writing the disk data, btrfs calculates the checksum of the data. Then write checksum and data to disk at the same time.
Btrfs uses a separate checksum Tree to manage the checksum of the data block, and separates the checksum from the data block protected by the checksum, thereby providing stricter protection. If a domain is added to the header of each data block to save the checksum, then this data block becomes a structure that protects itself. Under this structure, there is an error that cannot be detected. For example, the file system originally intended to read block A from the disk, but returned block B. Since the checksum is inside the block, the checksum is still correct. btrfs uses
checksum tree to save the checksum of data blocks, avoiding the above problems.
Btrfs uses crc32 algorithm to calculate checksum, and will support other types of checksum algorithms in future development. In order to improve efficiency, btrfs will use different kernel threads to execute the work of writing data and checksum in parallel.
Features related to multi-device management
Every Unix administrator has faced the task of allocating disk space for users and various applications. In most cases, people cannot accurately estimate in advance how much disk space a user or application will need in the future. It often happens that the disk space is exhausted, and people have to try to increase the file system space at this time. Traditional ext2/3 cannot cope with this demand.
Many volume management software are designed to meet the needs of users for multi-device management, such as LVM. Btrfs integrates the functions of volume management software, which simplifies user commands on the one hand, and improves efficiency on the other hand.
Multi-device management
Btrfs supports dynamically adding devices. After adding a new disk to the system, the user can use the btrfs command to add the device to the file system.
In order to flexibly use the device space, Btrfs divides the disk space into multiple chunks. Each chunk can use a different disk space allocation strategy. For example, some chunks only store metadata, and some chunks only store data. Some chunks can be configured as mirrors, while others can be configured as stripe. This provides users with very flexible configuration possibilities.
Subvolume
Subvolume is a very elegant concept. That is, a part of the file system is configured as a complete sub-file system, called subvolume.
With subvolume, a large file system can be divided into multiple sub-file systems. These sub-file systems share the underlying device space and are allocated from the underlying device when disk space is needed, similar to an application calling malloc() to allocate memory. It can be called a storage pool. This model has many advantages, such as making full use of disk bandwidth and simplifying disk space management.
The so-called full use of disk bandwidth means that the file system can read and write multiple disks at the bottom in parallel, because each file system can access all disks. The traditional file system cannot share the underlying disk device, whether it is physical or logical, and therefore cannot be read and written in parallel.
The so-called simplified management is relative to volume management software such as LVM. Using the storage pool model, the size of each file system can be automatically adjusted. With LVM, if the space of a file system is not enough, the file system cannot automatically use the free space on other disk devices, but must be adjusted manually using LVM management commands.
Subvolume can be mounted to any mount point as the root directory. Subvolume is a very interesting feature and has many applications.
Suppose the administrator only wants certain users to access a part of the file system. For example, he wants users to only access all the content under /var/test/, but not the other content under /var/. Then you can make /var/test a subvolume. The subvolume /var/test is a complete file system, which can be mounted with the mount command. For example, if you mount it to the /test directory and give the user access to /test, then the user can only access the content under /var/test.
Snapshot and clone
A snapshot is a complete backup of the file system at a certain moment. After the snapshot is created, changes to the file system will not affect the contents of the snapshot. This is a very useful technique.
Such as database backup. If at time T1, the administrator decides to back up the database, then he must stop the database first. Backing up files is a very time-consuming operation. If an application program modifies the contents of the database during the backup process, a consistent backup will not be obtained. Therefore, the database service must be stopped during the backup process, which is not allowed for certain critical applications.
Using snapshots, the administrator can stop the database at time T1 and create a snapshot of the system. This process generally only takes a few seconds, and then the database service can be restored immediately. After that, the administrator can back up the contents of the snapshot at any time, and the user's modification of the database at this time will not affect the contents of the snapshot. When the backup is complete, the administrator can delete the snapshot to free up disk space.
Snapshots are generally read-only. When the system supports writable snapshots, such writable snapshots are called clones. Cloning technology also has many applications. For example, install basic software in a system, and then make different clones for different users. Each user uses his own clone without affecting the disk space of other users. Very similar to a virtual machine.
Btrfs supports snapshot and clone. This feature greatly increases the scope of use of btrfs, and users do not need to purchase and install expensive and complex volume management software. The following briefly introduces the basic principles of btrfs to achieve snapshots.
As mentioned earlier, Btrfs adopts COW transaction technology. As can be seen from Figure 1-10, after the COW transaction is over, if the original nodes A, C, E are not deleted, then A, C, E, D, and F are still intact. The file system before the start of the transaction. This is the basic principle of snapshot implementation.
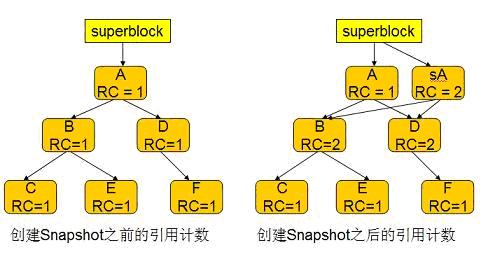
Btrfs uses the reference count to determine whether to delete the original node after the transaction commit. For each node, btrfs maintains a reference count. When the node is referenced by other nodes, the count is increased by one, and when the node is no longer referenced by other nodes, the count is decreased by one. When the reference count reaches zero, the node is deleted. For ordinary Tree Root, the reference count is increased by one when it is created, because Superblock will reference this Root block. Obviously, the reference count of all other nodes in this tree is one at the beginning. When the COW transaction commits, the superblock is modified to point to the new Root
A. The reference count of the original Root block A is reduced by one and becomes zero, so the A node is deleted. The deletion of node A will cause the reference counts of its descendants to be decremented by one. As a result, the reference counts of nodes B and C in Figure 1-10 also become 0 and are deleted. When the D and E nodes are in COW, because they are referenced by A'', the counter is incremented by one, so the counter is not reset to zero at this time, so it is not deleted.
When creating a snapshot, btrfs copies the Root A node to sA, and sets the reference count of sA to 2. When the transaction commits, the reference count of the sA node will not be reset to zero and will not be deleted, so users can continue to access the files in the snapshot through Root sA.
Software RAID
RAID technology has many very attractive features. For example, users can combine multiple cheap IDE disks into a RAID0 array, which becomes a large-capacity disk; RAID1 and more advanced RAID configurations also provide data redundancy protection, This makes the data stored in the disk more secure.
Btrfs supports software RAID well, and the types of RAID include RAID0, RAID1 and RAID10.
Btrfs performs RAID1 protection on metadata by default. As mentioned earlier, btrfs divides the device space into chunks. Some chunks are configured as metadata, that is, only metadata is stored. For this type of chunk, btrfs divides the chunk into two strips. When writing metadata, it will write to the two strips at the same time, so as to protect the metadata.
The other features listed on the Btrfs homepage are not easy to classify. These features are relatively advanced technologies in modern file systems, which can improve the time or space efficiency of the file system.
Delay allocation
Delayed allocation technology can reduce disk fragmentation. In the Linux kernel, in order to improve efficiency, many operations are delayed.
In the file system, frequent allocation and release of small blocks of space can cause fragmentation. Delayed allocation is a technique in which when the user needs disk space, the data is first stored in the memory. The disk allocation request is sent to the disk space allocator, and the disk space allocator does not immediately allocate real disk space. Just record this request and return.
Disk space allocation requests may be very frequent, so during a period of delayed allocation, the disk allocator may receive many allocation requests, some requests may be merged, and some requests may even be cancelled during this delay. Through such "waiting", unnecessary allocations can often be reduced, and it is also possible to combine multiple small allocation requests into one large request, thereby improving IO efficiency.
Inline file
There are often a large number of small files in the system, such as a few hundred bytes or smaller. If you allocate a separate data block for it, it will cause internal fragmentation and waste disk space. btrfs saves the content of small files in metadata, and no longer allocates additional disk blocks for storing file data. The internal fragmentation problem is improved, and the file access efficiency is also increased.
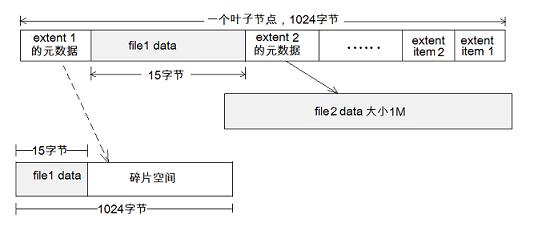
The figure above shows the leaf nodes of a BTree. There are two extent data item metadata in the leaf, which are used to represent the disk space used by the files file1 and file2.
Suppose the size of file1 is only 15 bytes; the size of file2 is 1M. As shown in the figure, file2 uses a normal extent representation method: extent2 metadata points to a section of extent with a size of 1M, and its content is the content of file2 file.
For file1, btrfs will embed its file content into metadata extent1. If you do not use inline file technology. As shown by the dotted line, extent1 points to the smallest extent, which is a block, but file1 has 15 bytes, and the remaining space becomes fragmented space.
Using inline technology, when reading file1, only the metadata block needs to be read, instead of reading the metadata of extent1 first, and then reading the block that actually stores the contents of the file, thereby reducing disk IO.
Thanks to the inline file technology, btrfs is very efficient in processing small files and avoids the problem of disk fragmentation.
Directory index
When the number of files in a directory is huge, the directory index can significantly improve the file search time. Btrfs itself uses BTree to store directory entries, so the efficiency of searching for files in a given directory is very high.
However, the way btrfs uses BTree to manage directory entries cannot meet the needs of readdir at the same time. readdir is a POSIX standard API. It requires all files in a specified directory to be returned, and in particular, these files must be sorted by inode number. The key when the btrfs directory entry is inserted into the BTree is not the Inode number, but a hash value calculated based on the file name. This method is very efficient when looking for a specific file, but it is not suitable for readdir. For this reason, every time btrfs creates a new file, in addition to inserting a directory entry with the hash value as the Key, it also inserts another directory entry index. The
KEY of the directory entry index uses the sequence number as the key value of the BTree. The sequence number increases linearly each time a new file is created. Because the inode number is also increased every time a new file is created, the sequence number and inode number are in the same order. Using this sequence number as the KEY to search in BTree can easily get a file list sorted by inode number.
In addition, files sorted by sequence number are often adjacent to each other on the disk, so accessing a large number of files in sequence number order will achieve better IO efficiency.
compression
Everyone has used compression software such as zip and winrar. Compressing a large file can effectively save disk space. Btrfs has a built-in compression function.
Usually people think that compressing data before writing it to disk will take up a lot of CPU computing time and will inevitably reduce the read and write efficiency of the file system. However, with the development of hardware technology, the gap between CPU processing time and disk IO time continues to increase. In some cases, it takes a certain amount of CPU time and some memory, but it can greatly save the amount of disk IO, which can increase the overall efficiency.
For example, if a file is not compressed, 100 disk IOs are required. But after spending a small amount of CPU time for compression, only 10 disk IOs are needed to write the compressed file to disk. In this case, the IO efficiency increases instead. Of course, this depends on the compression ratio. Currently btrfs uses the DEFALTE/INFLATE algorithm provided by zlib for compression and decompression. In the future, btrfs should be able to support more compression algorithms to meet the different needs of different users.
There are still some shortcomings in the compression features of btrfs. When compression is enabled, all files in the entire file system will be compressed, but users may need more fine-grained control, such as using different compression algorithms for different directories, or Compression is prohibited. I believe that the btrfs development team will solve this problem in future versions.
For some types of files, such as jpeg files, it can no longer be compressed. Trying to compress it will purely waste CPU. For this reason, when several blocks of a file are compressed and the compression ratio is found to be poor, btrfs will no longer compress the rest of the file. This feature improves the IO efficiency of the file system to some extent.
Pre-allocated
Many applications have the need to pre-allocate disk space. They can tell the file system to reserve some space on the disk through the posix_fallocate interface, but do not write data temporarily. If the underlying file system does not support fallocate, the application can only use write to write some useless information in advance to reserve enough disk space for itself.
Supporting reserved space by the file system is more effective and can reduce disk fragmentation, because all the space is allocated at once, so it is more likely to use contiguous space. Btrfs supports posix_fallocate.
So far, we have discussed many features of btrfs in more detail, but btrfs can provide more features. btrfs is in the experimental development stage, and there will be more features.
Btrfs also has an important shortcoming. When an error occurs in a node in the BTree, the file system will lose all file information under that node. But ext2/3 avoids this problem called "error diffusion".
But no matter what, I hope you, like me, begin to agree that btrfs will be the most promising file system for Linux in the future.