Preface
Sentiment analysis is a part of natural language processing. Its task is to determine whether the emotion expressed by the text is positive, neutral, or negative, given a text. This is widely used:
1. Automatic detection of product praise.
2. Whether users of platforms such as Weibo and Twitter are happy to praise or criticize and complain.
This time, I will lead you to use machine learning to do a real battle on sentiment analysis.
Note: This time I will focus on a process of actual machine learning, rather than detailed machine learning algorithms. It will be more friendly to novices who want to experience it. In addition, for novices, what I want to remind is that it is normal to experience a complete process and figure out that it takes a long time, so don’t be impatient.
related data
Our data is the tweets sent by users on Twitter. Our task is to train a model to judge whether it is a happy praise ( positive), a criticism or a complaint ( negative) or a neutral ( neutral) given a Twitter speech that has not been seen before. . For example, given “bullying me”(bullying me), the model needs to be able to output “negative”.
The data this time has been uploaded to github . We only used the train.csvfiles in this actual combat .
Actual combat
1. Import related packages and models.
import pandas as pd
import numpy as np
#将train.csv划分训练集和测试集
from sklearn.model_selection import train_test_split
#将文本变成向量,这是自然语言处理的常用技术
from sklearn.feature_extraction.text import TfidfVectorizer
#逻辑回归模型
from sklearn.linear_model import LogisticRegression
#支持向量机
from sklearn.svm import LinearSVC
#朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
#训练完成后,对模型的评价
from sklearn.metrics import accuracy_score,classification_report
#对于上面的包,你只需要会pandas和numpy两个包,其他不会不要紧,如果连pandas和numpy都不会,要么先去学(比较建议),要么看下去不懂再查。
2. Read the data. The path here needs to be changed to the path where your data is located.
data=pd.read_csv("data/tweet-sentiment-extraction/train.csv")
data.head(5)
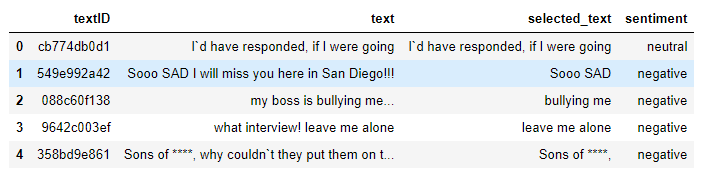
3. Construct the input and output of the model. For simplicity, we choose selected_text for input and sentiment as the label for output. The other two columns are not needed.
datax=data["selected_text"]
datay=data["sentiment"]
print(datax.shape)
print(datay.shape)

4. #Dividing training set and test set. The test set is used to select models or hyperparameters. You can refer to how the training data set is divided into the verification test set?
trainx,testx,trainy,testy=train_test_split(datax,datay,test_size=0.3,random_state=42)
print(trainx.shape)
print(testx.shape)
Which is random_statewhat's the use? You can refer to what is the use of random_state in train_test_split function in sklearn?
5. Deal with missing values. The following is a bit cumbersome to deal with. If you don’t understand it too much, it’s okay. Just take a look at the general process and practice it again. For details, please refer to How to determine whether there are missing values None or NaN(nan) in the DataFrame?
#查看是否有缺失值
trainx.isnull().any()

Find the position of the missing value and fill it with a fixed string (such as a space or "#"), or you can delete it directly.
#可以得到是否为空得true,false的同样shape的dataframe or series。
boolx=trainx.isnull()
#改成数值型,否则numpy无法处理。
boolx[boolx==True]=1
boolx

#必须要先将dataframe或者series转化成ndarray,否则argwhere会报错。
boolxn=np.array(boolx)
np.argwhere(boolxn==1)
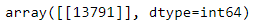
#由于随机状态固定了,所以分配的训练集和测试集每次都是那样的,即每一次索引都是13791。但是这个是顺序的那个索引,我们应该得到真正的index.
sindex=trainx.index
sindex[13791]

#为了追究data中到底是什么,我们得到了其索引是314,由于这个是从0开始的,所以索引和iloc都是一样的。
data.iloc[314,:]
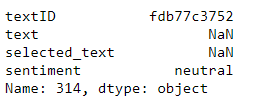
We found that there was a piece of training data that didn't say anything NaN, and sentiment analysis was marked as neutral.
#这里我需要给一个暗号,为了便于处理,将空值一律替换成空格或者#都可以。
trainx.iloc[13791]="#"
trainx.iloc[13791]
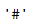
6. Vectorize the text trainx. You can refer to an example to use TfidfVectorizer in sklearn .
#下面将文本trainx给向量化。
tv=TfidfVectorizer(stop_words="english",ngram_range=(1,1),max_df=0.8,min_df=2)
tv_fit=tv.fit_transform(trainx)
#从此,trainx变成了tv_fit的toarray,也就是说已经变成了向量。
trainxv=tv_fit.toarray()
trainxv

trainxv.shape
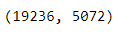
In the same way, testx should also be converted into a vector. Note that it is tvconverted into a TV that has been done above , not a new tv, otherwise the dimension recorded in testxv may be different from trainxv, and may not be 5072, then based on the model trained by trainxv (only 5072 dimensions are accepted), use testxv to go When verifying the test, the input is definitely not entered.
testxv=tv.transform(testx)
testxv
#下面显示是稀疏矩阵,压缩存储了,我真是笑了,我觉得这个说明了一个问题,这个testx里面有很多生词,这样不太好啊,因为感觉预测效果将不会太好。

7. Training the model.
#由于我们要用很多个机器学习模型来分类,而且都有一个共同点,都是fit,predict,所以干脆写成一个函数。
def train_model(model_name,model,trainx,trainy,testx,testy):
print("this is the model of",model_name)
model.fit(trainx,trainy)
trainy_pred=model.predict(trainx)
testy_pred=model.predict(testx)
print("accuracy on training data:",accuracy_score(trainy,trainy_pred))
print("accuracy on testing data:",accuracy_score(testy,testy_pred))
print("classification report on testing data:")
print(classification_report(testy,testy_pred))
#使用逻辑回归模型,
import warnings
warnings.filterwarnings("ignore")
model_lr=LogisticRegression()
train_model("logistic regression",model_lr,trainxv,trainy,testxv,testy)
#使用支持向量机模型来进行分类。
model_svm=LinearSVC()
train_model("support vector machine",model_svm,trainxv,trainy,testxv,testy)
#使用朴素贝叶斯模型来分类。
model_nb=MultinomialNB()
train_model("naive bayes",model_nb,trainxv,trainy,testxv,testy)
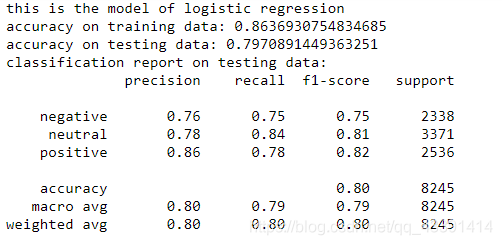
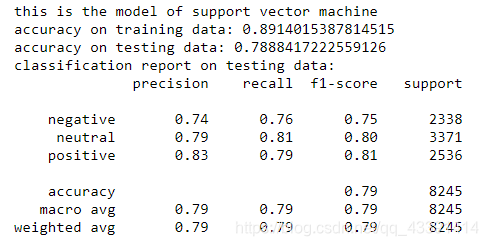
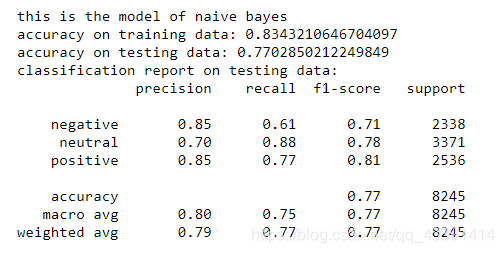
We have used 3 models for training above. As for the final choice, you can see the correct rate on the test set, or the weighted test set and training set (for example, add and divide by 2) to choose your final model. .
end
Personally, I suggest to understand this article carefully, it is not very long, and it does not involve too much difficult, but accumulate little by little. I didn't write something clearly, just ask questions.