Article Directory
awk editor
In Linux/UNIX systems, awk is a powerful editing tool. It reads the input text line by line, searches according to the specified matching mode, and performs formatting output or filtering processing on the content that meets the conditions. It can be used in non-interactive Under the circumstances, quite complex text operations are realized, and they are widely used in Shell scripts to complete various automated configuration tasks.
working principle
- The sed command is often used to process a whole line, while awk tends to divide a line into multiple "fields" and then process it.
- Awk also reads the text line by line. By default, it is separated by a space or tab key as a separator. The separated fields are saved to the built-in variables, and the editing commands are executed according to the mode or condition. The execution result can be displayed by printing the field data through the print function.
- In the process of using the awk command, you can use the logical operators "&&" to indicate "and", "||" to indicate "or", "!" to indicate "not"; you can also perform simple mathematical operations, such as +,- , *, /, %, ^ represent addition, subtraction, multiplication, division, remainder and power respectively.
Command format
awk 选项 '模式或条件 {操作}' 文件 1 文件 2 …
awk -f 脚本文件 文件 1 文件 2 …
The common built-in variables of awk (can be used directly) are as follows:
FS:列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
NF:当前处理的行的字段个数。
NR:当前处理的行的行号(序数)。
$0:当前处理的行的整行内容。
$n:当前处理行的第n个字段(第n列)
FILENAME:被处理的文件名。
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
Example
Output text by line
#输出所有内容
awk '{print}' sed.sh
awk '{print $0}' sed.sh

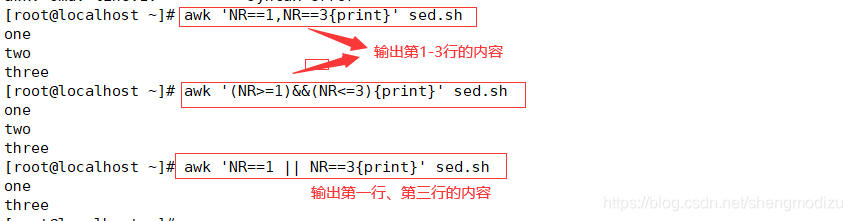
awk 'NR==1,NR==3{print}' sed.sh #输出第1-3行内容
awk '(NR>=1)&&(NR<=3){print}' sed.sh #输出第1-3行内容
awk 'NR==1 || NR==3{print}' sed.sh #输出第1行、第3行内容
awk '(NR%2)==1{print}' sed.sh #输出奇数行内容
awk '(NR%2)==0{print}' sed.sh #输出偶数行内容

awk '/^root/{print}' /etc/passwd #输出以root开头的内容
awk '/nologin$/{print}' /etc/passwd #输出以bash结尾的内容

#统计以/bin/bash 结尾的行数
grep -c "/bin/bash$" /etc/passwd
awk 'BEGIN {x=0}; /\/bin\/bash$/{x++};END{print x}' /etc/passwd
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句

Output text by field
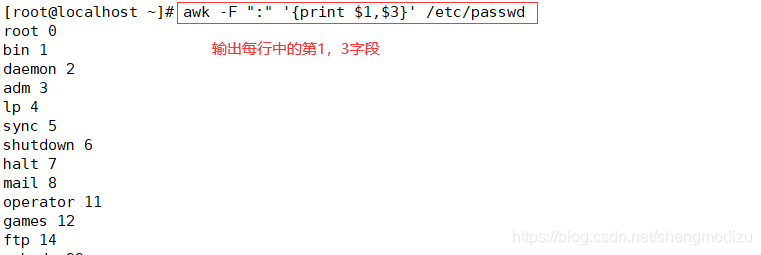
awk -F ":" '{print $3}' /etc/passwd #输出每行中(以”:“分割的)的第三个字段

awk -F ":" '{print $1,$3}' /etc/passwd #输出每行中(以”:“分割的)的第1,3个字段
awk -F ":" '$3<6{print $1,$3}' /etc/passwd #输出第三个字段的值小于6的行的第1,3个字段

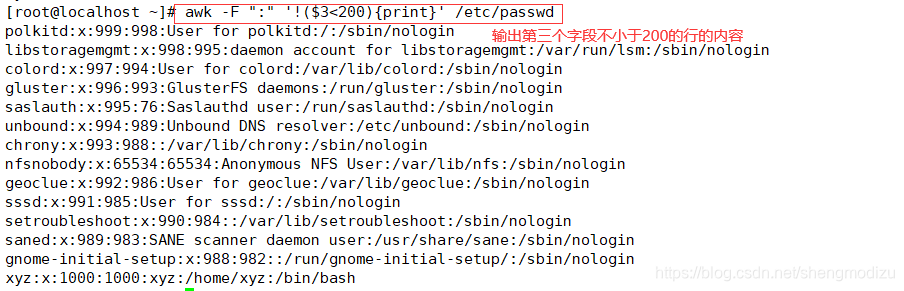
#输出第3个字段的值不小于200的行
awk -F ":" '!($3<200){print}' /etc/passwd
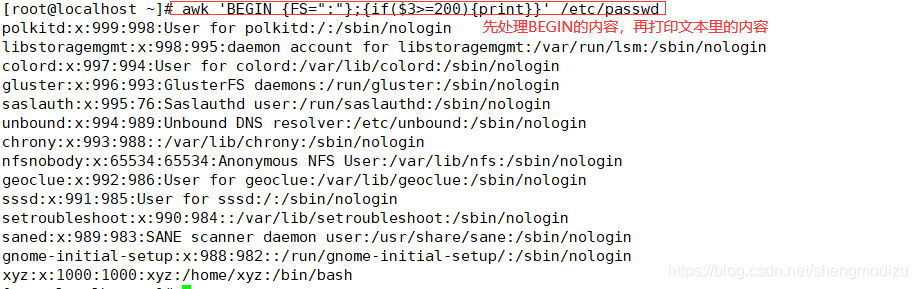
#输出第3个字段的值不小于200的行,先处理完BEGIN的内容,再打印文本里面的内容
awk 'BEGIN {FS=":"};{if($3>=200){print}}' /etc/passwd
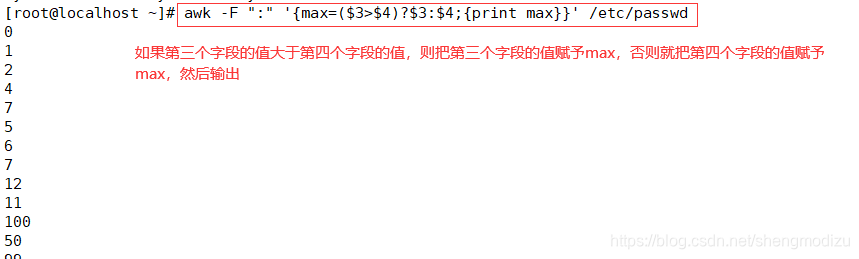
awk -F ":" '{max=($3>$4)?$3:$4;{print max}}' /etc/passwd
#($3>$4)?$3:$4是三元运算符,如果第三个字段的值大于第四个字段的值,则把第三个字段的值赋给max,否则把第四个字段的值赋给max
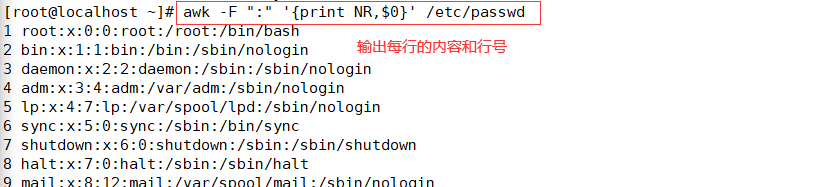
#输出每行内容和行号,每处理完一条记录,NR值加1
awk -F ":" '{print NR,$0}' /etc/passwd
#输出以冒号分隔且第7个字段中包含/bash的行的第1个字段
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd

#输出第1个字段中包含root且有7个字段的行的第1、2个字段
awk -F ":" '($1~"root")&&(NF==7){print $1,$2}' /etc/passwd
#输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行
awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd

Invoke shell commands through pipe symbols and double quotes
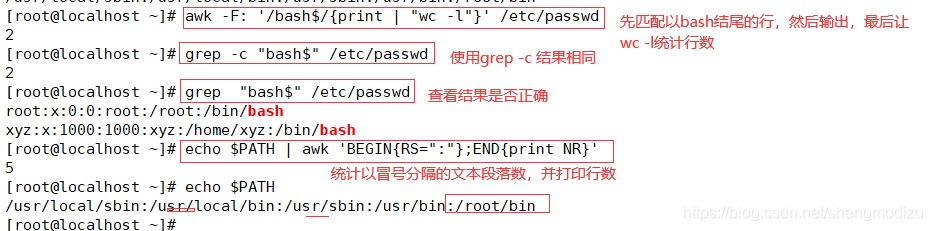
#调用 wc -l 命令统计使用 bash 的用户个数
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
grep -c "bash$" /etc/passwd #效果一样
#统计以冒号分隔的文本段落数,END{}语句块中,往往会放入打印结果等语句
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}'
#查看当前内存使用百分比
free -m | awk '/Mem:/ {print int($3/($3+$4)*100)”%“}'

#查看当前CPU空闲率,(-b -n 1 表示只需要1次的输出结果)
top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}'

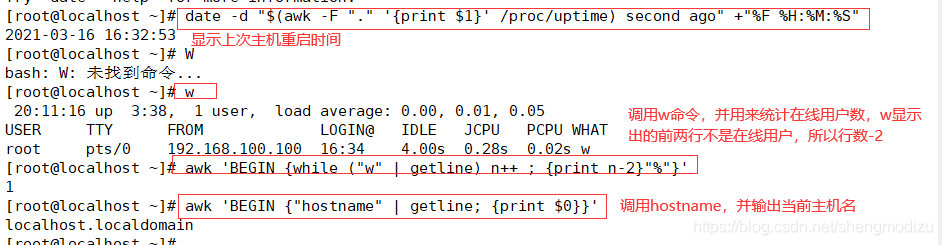
#显示上次系统重启时间,等同于uptime;second ago为显示多少秒前的时间,+"%F %H:%M:%S"等同于+"%Y-%m-%d %H:%M:%S"的时间格式
date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S"
#调用w命令,并用来统计在线用户数
awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}"%"}'
#调用 hostname,并输出当前的主机名
awk 'BEGIN {"hostname" | getline; {print $0}}'
- When there is no redirection "<" or "|" on the left and right of getline, getline acts on the current file, and reads the first line of the current file to the variable var or $0 followed by it; because awk has already read a line before processing the getline , So the return result of getline is interlaced.
- When there are redirection characters "<" or "|" on the left and right of getline, getline acts on the directional input file. Since the file is just opened and has not been read into a line by awk, just getline reads it, then getline returns this The first line of the file, not every other line.
