IO operation in-depth
Character Encoding
In the computer world, only the data of 0 and 1 are recognized. If you want to describe the encoding of some characters, you need to combine these binary data, so that you can see the Chinese now, but you must display it correctly when encoding. The content must be decoded, so encoding and decoding must adopt the same set of unified standards. If they are not unified, garbled codes will appear.
In practice, the commonly used codes in development are as follows:
- GBK/GB2312: National standard code, which can describe Chinese information. GB2312 only describes simplified Chinese, while GBK includes simplified and traditional;
- ISO8859-1: International universal code, which can be used to describe all letter information, if it is a pictograph, it needs to be coded;
- UNICODE code: It is stored in hexadecimal format, which can describe all characters;
- UTF encoding: The pictograph part uses hexadecimal encoding, while ordinary letters use ISO8859-1 encoding, which has the advantage of fast transmission and bandwidth saving, which has become the first encoding ("UTF-8") in development.
If you want to know the encoding rules supported in the current system, you can use the following code to list all native attributes:
List native attributes
public class Char_Encode {
public static void main(String[] args) {
System.getProperties().list(System.out);
}
}
When the encoding is not set, the default encoding is used, and the encoding can be specified by force.
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class Char_Encode {
public static void main(String[] args) throws Exception {
OutputStream output = new FileOutputStream("C:"+File.separator+"mld.txt");
output.write("中国人民万岁".getBytes("ISO8859-1")); //指定编码
}
}
The problem of garbled characters in the project is the inconsistency of encoding and decoding standards, and the best way to solve garbled characters is to use "UTF-8" for all encoding methods.
Memory operation flow
All used before are file operation streams. With the characteristics of file operations, the program uses InputStream to read the content of the file, and then the program uses OutputStream to output the content to the file. All operations are based on the program as the terminal.
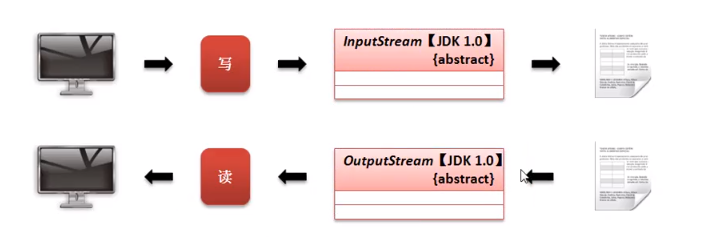
Assuming that IO operations need to be implemented now, but you do not want to generate files (temporary files), you can use memory as the terminal to output. The process at this time is as follows: Provide two types of memory operation streams in Java:

- Byte memory operation stream: ByteArrayOutputStream (OutputStream子类)、ByteArrayInputStream(InputStream subclass)
- Character memory operation stream: CharArrayWriter, CharArrayReader
The memory usage analysis is mainly based on the ByteArrayOutputStream and ByteArrayInputStream classes:
- ByteArrayOutputStream construction method:
public ByteArrayOutputStream(); - ByteArrayInputStream construction method:
public ByteArrayInputStream(byte[] buf);
There is an important method in the ByteArrayOutputStream class, this method can get all the data information stored in the memory stream:
- retrieve data:
public byte[] toByteArray(); - Use string form to get:
public String toString();
Use memory flow time to convert lowercase letters to uppercase letters
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class Memory_IO {
public static void main(String[] args) throws Exception {
String str = "test!";
InputStream input = new ByteArrayInputStream(str.getBytes()); //将数据保存在内存流
OutputStream output = new ByteArrayOutputStream();
int data = 0;
while((data = input.read()) != -1) {
//每次读取一个字节
output.write(Character.toUpperCase((char)data));
}
System.out.println(output);
input.close();
output.close();
}
}
If you don't want to just return in the form of a string, because the storage may be other binary data, then you can use the extended function of the ByteArrayOutputStream subclass to get all the data at this time.
Get all byte data
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
public class Memory_IO {
public static void main(String[] args) throws Exception {
String str = "test!";
InputStream input = new ByteArrayInputStream(str.getBytes()); //将数据保存在内存流
// 必须使用子类来调用子类自己的扩展方法
ByteArrayOutputStream output = new ByteArrayOutputStream();
int data = 0;
while((data = input.read()) != -1) {
//每次读取一个字节
output.write(Character.toUpperCase((char)data));
}
byte result[] = output.toByteArray(); //获取全部数据
System.out.println(new String(result)); //自己处理字节数据
input.close();
output.close();
}
}
At the beginning, ByteArrayOutputStream can be used to read large-scale text files.
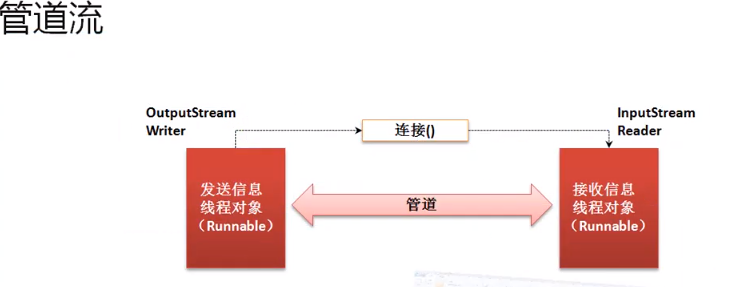
Pipe flow
The main function of the pipeline flow is to implement IO operations between two threads. For pipeline flow, it is also divided into two categories:
- Character pipe stream: PipedWriter(Writer subclass)、PipedReader(Reader subclass)
- Connection processing:
public void connect(PipedInputStream snk) throws IOException
- Connection processing:
- Byte pipeline stream: PipedOutputStream(OutputStream子类) 、 PipedInputStream (InputStream subclass)
- Connection processing:
public void connect(PipedReader snk) throws IOException
- Connection processing:
Implement pipeline processing
//代码有问题
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
class SendThread implements Runnable{
private PipedOutputStream output; //管道输出流
public SendThread() {
this.output = new PipedOutputStream(); //实例化管道输出流
}
@Override
public void run() {
for(int x=0; x<10;x++) {
try {
//利用管道实现数据发送处理
this.output.write(("No:"+(x+1)+"-"+Thread.currentThread().getName()+"信息发送\n").getBytes());
} catch (IOException e) {
e.printStackTrace();
}
try {
this.output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public PipedOutputStream getOutput() {
return output;
}
}
class ReceiveThread implements Runnable{
private PipedInputStream input;
public ReceiveThread() {
this.input = new PipedInputStream();
}
@Override
public void run() {
byte data[] = new byte[1024];
int len = 0;
ByteArrayOutputStream bos = new ByteArrayOutputStream(); //将所有数据保存到内存输出流
try {
while((len = this.input.read(data)) != -1) {
bos.write(data,0,len); //所有数据保存到内存流bos
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("{"+ Thread.currentThread().getName() +"接收消息}" + new String(bos.toByteArray()));
try {
this.input.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public PipedInputStream getInput() {
return input;
}
}
public class Piped_IO {
public static void main(String[] args) throws IOException {
SendThread send = new SendThread();
ReceiveThread receive = new ReceiveThread();
send.getOutput().connect(receive.getInput()); //进行管道连接
new Thread(send,"发送线程").start();
new Thread(receive,"接收线程").start();
}
}
The pipeline is similar to the effect of dripping in the hospital, one is responsible for sending and the other is responsible for receiving, and the middle is connected by the pipeline.
RandomAccessFile (random read class)
The processing operation of the file content is mainly realized through InputStream (Reader), OutputStream (Writer), but the content reading realized by these classes can only read the data part in. If there is such a requirement
now : now A very large file, if reading and analyzing according to the traditional IO operation is impossible at this time, so in this case, a RandomAccessFile class is provided in the java.io package, which can realize the fileSkip reading, You can just read the filePart(Prerequisite: There needs to be a perfect storage form, that is, the number of data storage bits must be determined.) The
following operation methods are defined in the RandomAccessFile class:
- Construction method:
public RandomAccessFile(File file,String mode) throws FileNotFoundException;- Processing mode: r, rw
Realize file saving
import java.io.File;
import java.io.FileNotFoundException;
import java.io.RandomAccessFile;
public class Random_AccessFile {
public static void main(String[] args) throws Exception {
File file = new File("C:\\Project\\Java_study\\src\\文件\\test.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
String names[] = new String[] {
"zhangsan","wangwu ","lisi "};
int ages[] = new int[] {
30,16,20};
for(int x=0;x<names.length;x++) {
raf.write(names[x].getBytes());
raf.writeInt(ages[x]);
}
raf.close();
}
}
The biggest feature of RandomAccessFile lies in the processing of data reading. Because all data is stored in a fixed length, it can be read by skipping bytes when reading:
- Jump down:
public int skipBytes(int n) throws IOException; - Jump back:
public void seek(long pos) throws IOException;
Read data
import java.io.File;
import java.io.FileNotFoundException;
import java.io.RandomAccessFile;
public class Random_AccessFile {
public static void main(String[] args) throws Exception {
File file = new File("C:\\Project\\Java_study\\src\\文件\\test.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
//跳过24位
{
raf.skipBytes(24);
byte data[] = new byte[8];
int len = raf.read(data);
System.out.println(new String(data,0,len) + " - " + raf.readInt());
}
//回
{
raf.seek(0); //回到顶点
byte data[] = new byte[8];
int len = raf.read(data);
System.out.println(new String(data,0,len) + " - " + raf.readInt());
}
raf.close();
}
}
In the overall use, the user defines the location to be read by himself, and then reads the data according to the specified structure.