What I want to share with you today is how to crawl the movie news about the upcoming movies on Douban in Shenzhen, and use ordinary single-threaded, multi-threaded and coroutine respectively to crawl, so as to compare single-threaded, multi-threaded and coroutine in the network Performance in crawlers.
The specific URL to be crawled is: https://movie.douban.com/cinema/later/shenzhen/
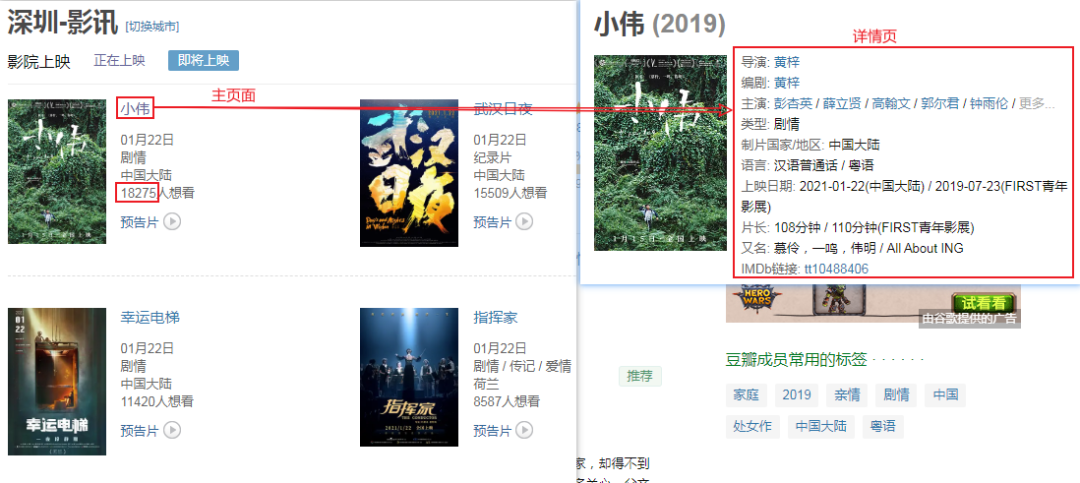
In addition to crawling the entry page, you also need to crawl the detail page of each movie. The specific structure information to be crawled is as follows:
Crawl test
Below I demonstrate the use of xpath to parse data.
Entry page data read:
import requests
from lxml import etree
import pandas as pd
import re
main_url = "https://movie.douban.com/cinema/later/shenzhen/"
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get(main_url, headers=headers)
r
result:
<Response [200]>
Check the xpath of the required data:
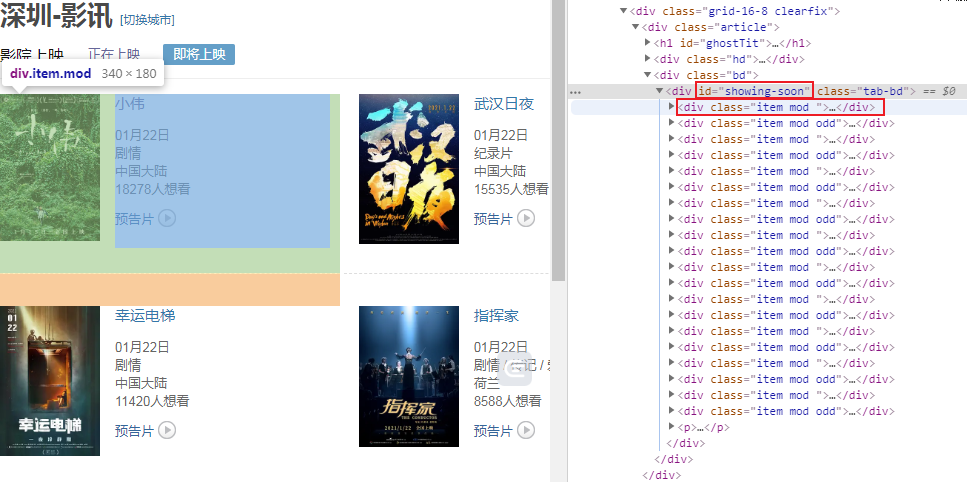
You can see that each movie information is located in showing-soonthe div below the id , and then analyze the internal movie name, url, and the location of the number of people you want to watch, so you can write the following code:
html = etree.HTML(r.text)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
# imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
result.append((name, int(like_num[:like_num.find("人")]), url))
main_df = pd.DataFrame(result, columns=["影名", "想看人数", "url"])
main_df
result:

Then choose the url of a detail page to test. I chose the movie Bear Infested Wild Continent, because the text data is relatively the most complex and the most representative:
url = main_df.at[17, "url"]
url
result:
'https://movie.douban.com/subject/34825886/'
Many people learn python and don't know where to start.
Many people learn python and after mastering the basic grammar, they don't know where to find cases to get started.
Many people who have done case studies do not know how to learn more advanced knowledge.
So for these three types of people, I will provide you with a good learning platform, free to receive video tutorials, e-books, and the source code of the course!
QQ group: 721195303
Analysis details page structure:
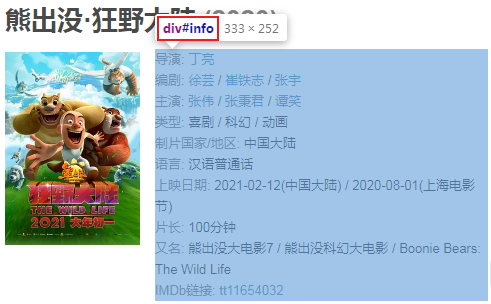
The text information is in this position. Below we directly extract all the text nodes under this div:
r = requests.get(url, headers=headers)
html = etree.HTML(r.text)
movie_infos = html.xpath("//div[@id='info']//text()")
print(movie_infos)
result:
['\n ', '导演', ': ', '丁亮', '\n ', '编剧', ': ', '徐芸', ' / ', '崔铁志', ' / ', '张宇', '\n ', '主演', ': ', '张伟', ' / ', '张秉君', ' / ', '谭笑', '\n ', '类型:', ' ', '喜剧', ' / ', '科幻', ' / ', '动画', '\n \n ', '制片国家/地区:', ' 中国大陆', '\n ', '语言:', ' 汉语普通话', '\n ', '上映日期:', ' ', '2021-02-12(中国大陆)', ' / ', '2020-08-01(上海电影节)', '\n ', '片长:', ' ', '100分钟', '\n ', '又名:', ' 熊出没大电影7 / 熊出没科幻大电影 / Boonie Bears: The Wild Life', '\n ', 'IMDb链接:', ' ', 'tt11654032', '\n\n']
For the convenience of reading, splice it:
movie_info_txt = "".join(movie_infos)
print(movie_info_txt)
result:
导演: 丁亮
编剧: 徐芸 / 崔铁志 / 张宇
主演: 张伟 / 张秉君 / 谭笑
类型: 喜剧 / 科幻 / 动画
制片国家/地区: 中国大陆
语言: 汉语普通话
上映日期: 2021-02-12(中国大陆) / 2020-08-01(上海电影节)
片长: 100分钟
又名: 熊出没大电影7 / 熊出没科幻大电影 / Boonie Bears: The Wild Life
IMDb链接: tt11654032
The next step is simple:
row = {}
for line in re.split("[\n ]*\n[\n ]*", movie_info_txt):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row
result:
{'导演': '丁亮',
'编剧': '徐芸 / 崔铁志 / 张宇',
'主演': '张伟 / 张秉君 / 谭笑',
'类型': '喜剧 / 科幻 / 动画',
'制片国家/地区': '中国大陆',
'语言': '汉语普通话',
'上映日期': '2021-02-12(中国大陆) / 2020-08-01(上海电影节)',
'片长': '100分钟',
'又名': '熊出没大电影7 / 熊出没科幻大电影 / Boonie Bears: The Wild Life',
'IMDb链接': 'tt11654032'}
You can see that each item was successfully cut out.
Based on the above test basis, we will improve the overall crawler code:
Single-threaded crawler
import requests
from lxml import etree
import pandas as pd
import re
main_url = "https://movie.douban.com/cinema/later/shenzhen/"
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get(main_url, headers=headers)
html = etree.HTML(r.text)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
print(url)
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
r = requests.get(url, headers=headers)
html = etree.HTML(r.text)
row = {}
row["电影名称"] = name
for line in re.split("[\n ]*\n[\n ]*", "".join(html.xpath("//div[@id='info']//text()")).strip()):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row["想看人数"] = int(like_num[:like_num.find("人")])
# row["url"] = url
# row["图片地址"] = imgurl
# print(row)
result.append(row)
df = pd.DataFrame(result)
df.sort_values("想看人数", ascending=False, inplace=True)
df.to_csv("shenzhen_movie.csv", index=False)
result:
https://movie.douban.com/subject/26752564/
https://movie.douban.com/subject/35172699/
https://movie.douban.com/subject/34992142/
https://movie.douban.com/subject/30349667/
https://movie.douban.com/subject/30283209/
https://movie.douban.com/subject/33457717/
https://movie.douban.com/subject/30487738/
https://movie.douban.com/subject/35068230/
https://movie.douban.com/subject/27039358/
https://movie.douban.com/subject/30205667/
https://movie.douban.com/subject/30476403/
https://movie.douban.com/subject/30154423/
https://movie.douban.com/subject/27619748/
https://movie.douban.com/subject/26826330/
https://movie.douban.com/subject/26935283/
https://movie.douban.com/subject/34841067/
https://movie.douban.com/subject/34880302/
https://movie.douban.com/subject/34825886/
https://movie.douban.com/subject/34779692/
https://movie.douban.com/subject/35154209/
Files crawled:
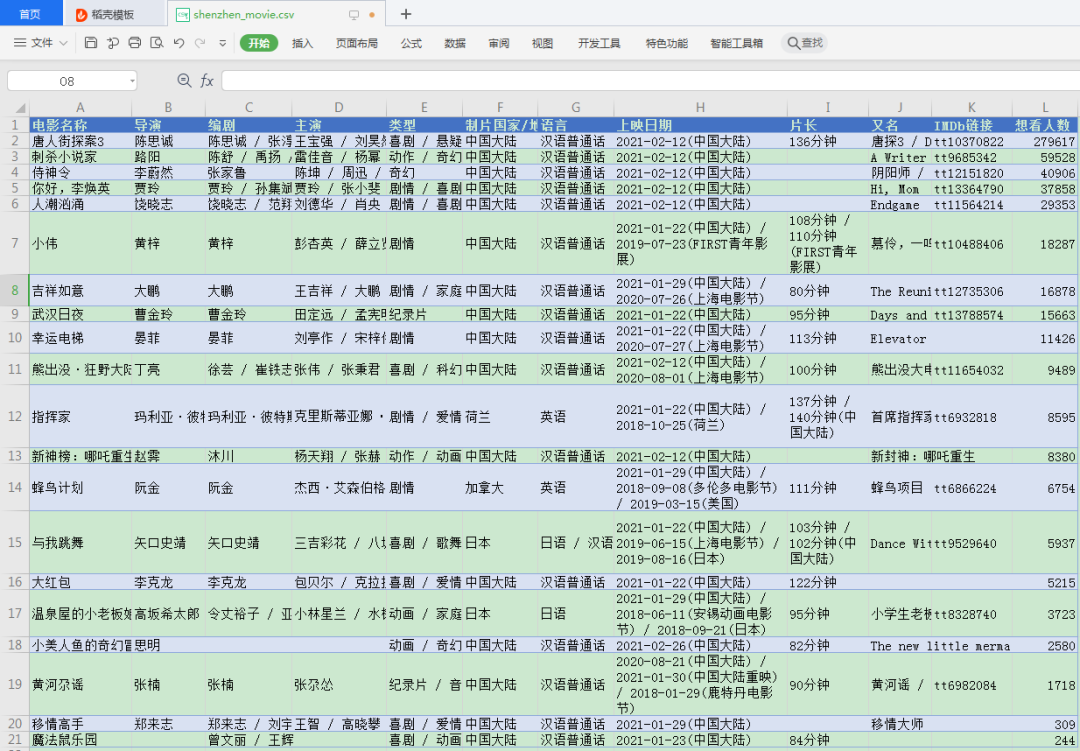
Overall time-consuming:
42.5 seconds.
Multi-threaded crawler
Single-threaded crawling takes a long time. Let’s take a look at the efficiency of crawling using multiple threads:
import requests
from lxml import etree
import pandas as pd
import re
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
def fetch_content(url):
print(url)
headers = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get(url, headers=headers)
return r.text
url = "https://movie.douban.com/cinema/later/shenzhen/"
init_page = fetch_content(url)
html = etree.HTML(init_page)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
# imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
result.append((name, int(like_num[:like_num.find("人")]), url))
main_df = pd.DataFrame(result, columns=["影名", "想看人数", "url"])
max_workers = main_df.shape[0]
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_tasks = [executor.submit(fetch_content, url) for url in main_df.url]
wait(future_tasks, return_when=ALL_COMPLETED)
pages = [future.result() for future in future_tasks]
result = []
for url, html_text in zip(main_df.url, pages):
html = etree.HTML(html_text)
row = {}
for line in re.split("[\n ]*\n[\n ]*", "".join(html.xpath("//div[@id='info']//text()")).strip()):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row["url"] = url
result.append(row)
detail_df = pd.DataFrame(result)
df = main_df.merge(detail_df, on="url")
df.drop(columns=["url"], inplace=True)
df.sort_values("想看人数", ascending=False, inplace=True)
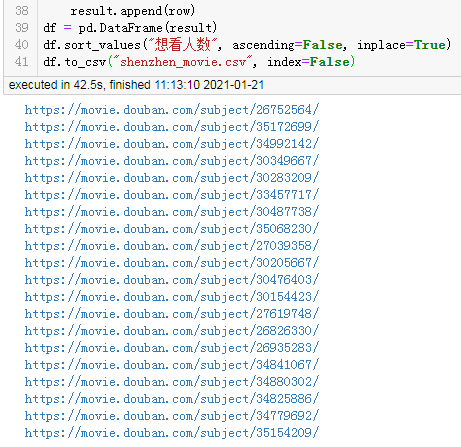
df.to_csv("shenzhen_movie2.csv", index=False)
df
result:
It took 8 seconds.
Since each subpage is crawled by a separate thread, and each thread is working almost at the same time, the final time consumption depends only on the slowest subpage crawled.
Coroutine asynchronous crawler
Since I am running in jupyter, in order to enable the coroutine to run directly in jupyter, I added the following two lines of code to the code, which can be removed in a normal editor:
import nest_asyncio
nest_asyncio.apply()
This problem is because there is a bug in the higher version of Tornado that jupyter relies on. Rolling back Tornado to the lower version can also solve this problem.
Below I use the coroutine to complete the crawling of this demand:
import aiohttp
from lxml import etree
import pandas as pd
import re
import asyncio
import nest_asyncio
nest_asyncio.apply()
async def fetch_content(url):
print(url)
header = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
async with aiohttp.ClientSession(
headers=header, connector=aiohttp.TCPConnector(ssl=False)
) as session:
async with session.get(url) as response:
return await response.text()
async def main():
url = "https://movie.douban.com/cinema/later/shenzhen/"
init_page = await fetch_content(url)
html = etree.HTML(init_page)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
# imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
result.append((name, int(like_num[:like_num.find("人")]), url))
main_df = pd.DataFrame(result, columns=["影名", "想看人数", "url"])
tasks = [fetch_content(url) for url in main_df.url]
pages = await asyncio.gather(*tasks)
result = []
for url, html_text in zip(main_df.url, pages):
html = etree.HTML(html_text)
row = {}
for line in re.split("[\n ]*\n[\n ]*", "".join(html.xpath("//div[@id='info']//text()")).strip()):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row["url"] = url
result.append(row)
detail_df = pd.DataFrame(result)
df = main_df.merge(detail_df, on="url")
df.drop(columns=["url"], inplace=True)
df.sort_values("想看人数", ascending=False, inplace=True)
return df
df = asyncio.run(main())
df.to_csv("shenzhen_movie3.csv", index=False)
df
result:

It takes only 7 seconds, which is a bit faster than multi-threading.
Since the request library does not support coroutines, I used aiohttp which supports coroutines for page crawling. Of course, the actual crawling time is still dependent on the network at the time, but overall, coroutine crawling will be slightly faster than multi-threaded crawling.
review
Today I demonstrated to you, single-threaded crawler, multi-threaded crawler and coroutine crawler. It can be seen that in general, the coroutine crawler is the fastest, the multi-threaded crawler is slightly slower, and the single-threaded crawler must crawl the previous page before it can continue to crawl.
However, the coroutine crawler is relatively not so easy to write. The request library cannot be used for data capture, and only aiohttp can be used. Therefore, when actually writing crawlers, we generally use multi-threaded crawlers to speed up, but it must be noted that websites have IP access frequency restrictions. If crawling too fast, IP may be blocked, so we generally use multi-threaded speeding at the same time. Proxy ip to crawl data concurrently.
Easter eggs: xpath+pandas parses the table and extracts the url
We can see a [ View all upcoming movies ] ( https://movie.douban.com/coming ) button at the bottom of Shenzhen Movie News , click in to see a complete list of recent movies, and found this The list is the data of a table tag:
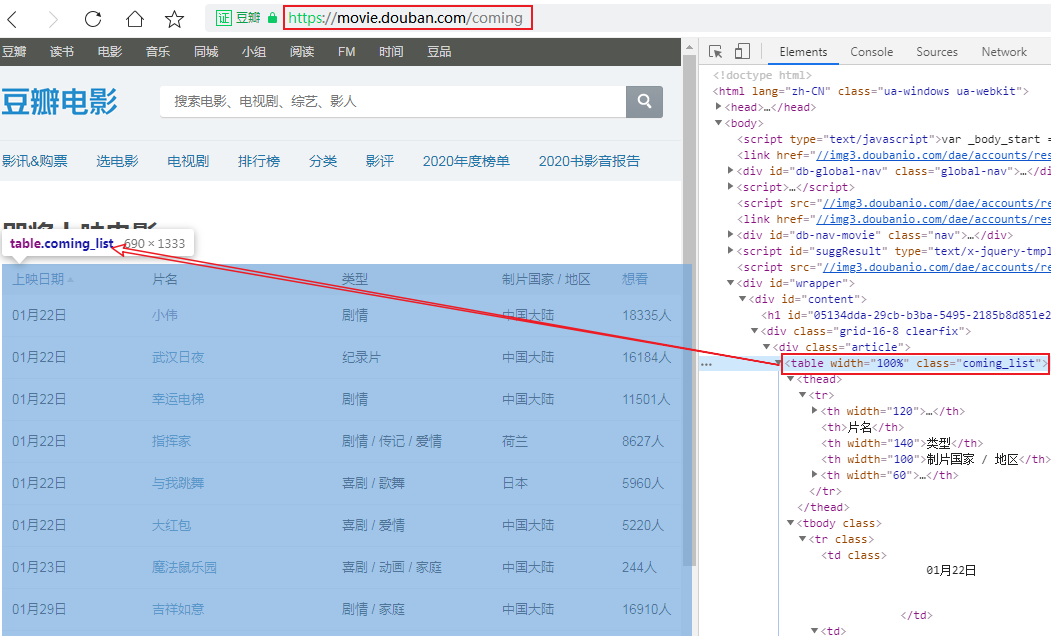
That's simple, we may not need to use xpath at all to parse the table, just use pandas directly, but the url address contained in the title still needs to be parsed, so I use xpath+pandas to parse this webpage, look at my code Bar:
import pandas as pd
import requests
from lxml import etree
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get("https://movie.douban.com/coming", headers=headers)
html = etree.HTML(r.text)
table_tag = html.xpath("//table")[0]
df, = pd.read_html(etree.tostring(table_tag))
urls = table_tag.xpath(".//td[2]/a/@href")
df["url"] = urls
df
result
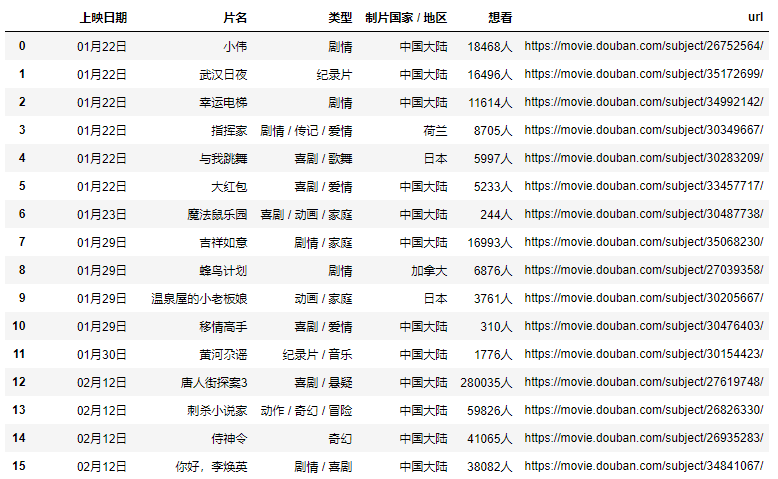 In this way, you can get the complete data of the main page, and then simply process it.
In this way, you can get the complete data of the main page, and then simply process it.
Conclusion
Thank you readers, if you have any ideas and gains, please leave a comment!