For Zhang's single-input single-output nonlinear function, using Huang's program, the number of hidden layer neurons does not have much influence, but the input weight and bias range have a great influence.
Number of hidden neurons 50
InputWeight=rand(
NumberofHiddenNeurons,NumberofInputNeurons ); BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1);

InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons)*2-1;
BiasofHiddenNeurons=rand(NumberofHiddenNeurons,1)*2-1;

InputWeight=rand(NumberofHiddenNeurons,NumberofInputNeurons)*30-10;
BiasofHiddenNeurons=rand(Numberof1)*10-ons 5;

The range of input weight and bias has a great influence on the result.
1. So how to choose the range of input weight and bias?
I have seen many papers that are all [-1,1], or randomly given.
For Zhang's nonlinear function, I only give a larger range. Is the data not normalized?
By using the yellow program, even the normalization of the data will not work.
2. So how to choose the range of input weight and bias?
I found a paper that talked about the setting of input weights and bias ranges:
Insights into randomized algorithms for neural networks: Practical issues and common pitfalls
Ming Li, Dianhui Wang
doi.org/10.1016/j.ins.2016.12.007
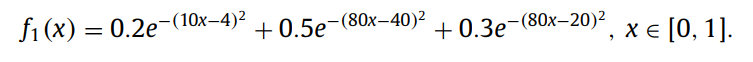

It can be seen from Table 1 and Table 2 that the range of input weights and biases in [-1,1] is not as good as [-200,200]. From the red circle, it can be seen that the error of [-200,200] is smaller. This shows that fixing the range of input weight and bias to [-1,1] is not the best. The above is for the nonlinear function f1.
The same result for f2 is as follows: It 
means that if the input weight and bias are set to [-1,1], the hidden layer output weight H will be less than the rank, and the training and testing performance is very poor. And the range is fixed at [-5,5], it will show good results.
Summary: This paper only says that the given input weight and bias range is unreasonable, but it does not give a method of how to set the input weight and bias range.
3. This issue will continue to be discussed in the following paper.
Generating random weights and biases in feedforward neural networks with random hidden nodes
DOI: 10.1016/j.ins.2018.12.063
Summary: This paper discusses that the weight a and bias b of the neuron activation function is the weight of the input neuron Different from the offset range! ! But I have to say that this aspect should also be considered.
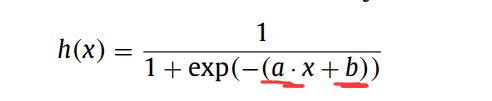
4. The number of hidden layer neurons corresponds to the range of input weight and bias. The number of hidden layer neurons also needs to be determined, but how to determine it?
A Study on Extreme Learning Machine for Gasoline Engine Torque Prediction mentioned how to choose the number of hidden layer neurons.

4. Through some papers using ELM, see how others set the scope?
5. I found a paper that specifically discussed about parameters
Some Tricks in Parameter Selection for Extreme Learning Machine
doi:10.1088/1757-899X/261/1/012002
This paper answered several questions
(1) Is it the number of hidden layer nodes? The more the number, the better?
The author tested several functions, and only the number of hidden layer nodes changed while other parameters remained unchanged.
Finally, it is concluded that it is not that the more hidden layer nodes, the better.
So how much should the number of hidden layer nodes be? The author gives several references to choose the number of hidden layer nodes.
one recommended is to automatically deduce the initial number of hidden nodes by using incremental constructive methods such as incremental ELM (I-ELM) [10], enhanced incremental ELM (EI-ELM) [20], bidirectional ELM (B-ELM) [ 21], pruned ELM (P-ELM) [22], error minimized ELM (EM-ELM) [23], etc… And then optimize the initial model to obtain the optimal network model
(2) Input node to hidden layer node Is it best to take the experience range [-1,1] for the range, and [0,1] for the offset range?
The value range of the author value change input multiplied to the hidden layer is respectively [-1, 1], [-10, 10], [-20, 20], and [-30, 30], while the other parameters remain unchanged , That is, the number of hidden layer nodes is fixed at 200, the bias is fixed at [0,1], and the Sigmoid function is used as the activation function. The performance is analyzed.
The conclusion is that different types of data do not necessarily achieve optimal performance in the range [-1,1]. We can adjust this range to get the best performance.
One recommendation is to use the grid search or random search to obtain the best parameters for ELM model.
The author suggests to use the grid search or random search to obtain the best parameters for ELM model .
(3) Is the offset [0,1] the best? The offset range is selected in sequence [0, 1], [0, 5], [0, 10], and [0, 15], and other parameters remain unchanged.
Conclusion: There are several approximations of nonlinear functions, and the optimal range is not [0,1]. Therefore, the optimal value can be obtained by adjusting the range.
(4) Does the type of activation function affect the optimal performance?
Conclusion: Although most of the sigmod functions have the best performance, there are also times when other functions are the best.
Summary: This paper was published in 2017. You can continue to see the progress in this area by searching for related papers citing this article.
How to find it? Baidu academic search for Extreme Learning Machine keywords found the following paper
A Study on Extreme Learning Machine for Gasoline Engine Torque Prediction
, which mentioned the above paper. 
5. Since my data is industrial data, I should find papers about extreme learning related to industrial data.
Robust extreme learning machine for modeling with unknown noise
https://doi.org/10.1016/j.jfranklin.2020.06.027
Published in 2019, this paper pointed out that ELM is more sensitive to the range of hidden layer parameters, and its changes will It has a great impact on the performance of the neural network.

6. How did I find this paper that specializes in input weights and bias ranges?
Answer: Through the random neural network review paper, it explains what the random neural network related papers do. This is how I discovered it. So when looking for something, first look at the review papers, see if there is anything you want in the review papers, and then look for related papers based on the articles you find.
I just want to solve the scope problem. I may not need to explore specific methods. I only need to use their conclusions to clarify my goals.
Methods: 1. You can continue to find relevant papers of the author to see if there is any more in-depth research. 2. See if the relevant papers that cited the paper have made relevant progress.