Xpath use
1. What is Xpath
XPath, the full name of XML Path Language, is the XML path language, which is a language for finding information in XML documents. It was originally used to search XML documents, but it is also suitable for searching HTML documents. Use path expressions to select nodes or node sets in an XML document. Nodes are selected by following paths or steps.
2.Xptah analysis principle
①Instantiate an etree object, and load the parsed page source data into the object
②Call the xpath method in the etree object combined with the xpath expression to achieve tag positioning and content capture
3. How to install Xpath
Install directly using pip pip install lxml
4. If you use Xpath
(1) Import from lxml import etree
(2) Load the source code data in the local html document into the etree object
html = etree.parse(r"路径/test.html")
(3) The source code data obtained on the Internet can be loaded into the etree object
html = etree.HTML('page_text')
(4) Note: The xpath method always returns a list
5. Xpath expression
Node, element, attribute, content
path expression
| / | Root node, node separator |
| // | Anywhere |
| . | Current node |
| … | Parent node |
| @ | Attributes |
Wildcard
| * | Any element |
| @* | Arbitrary attribute |
| node() | Any child node (element, attribute, content) |
Predicate
Use square brackets to define elements, called predicate
//a[n] n为大于零的整数,代表子元素排在第n个位置的<a>元素
//a[last()] last() 代表子元素排在最后个位置的<a>元素
//a[last()-1] 和上面同理,代表倒数第二个
//a[position()<3] 位置序号小于3,也就是前两个,这里我们可以看出xpath中的序列是从1开始
//a[@href] 拥有href的<a>元素
//a[@href='www.baidu.com'] href属性值为'www.baidu.com'的<a>元素
//book[@price>2] price值大于2的<book>元素
Multiple paths
Use | to connect two expressions, you can perform or match
html_data = html.xpath("//book/title | //book/price")
②Value
Ⅰ. Get text
Direct text: /text()
All text: //text()
Ⅱ. Get attribute
/@attribute name
Get src attribute
img/@src under img
5.Xpath commonly used functions
contains(string1,string2)
starts-with(string1,string2)
text()
last()
position()
node()
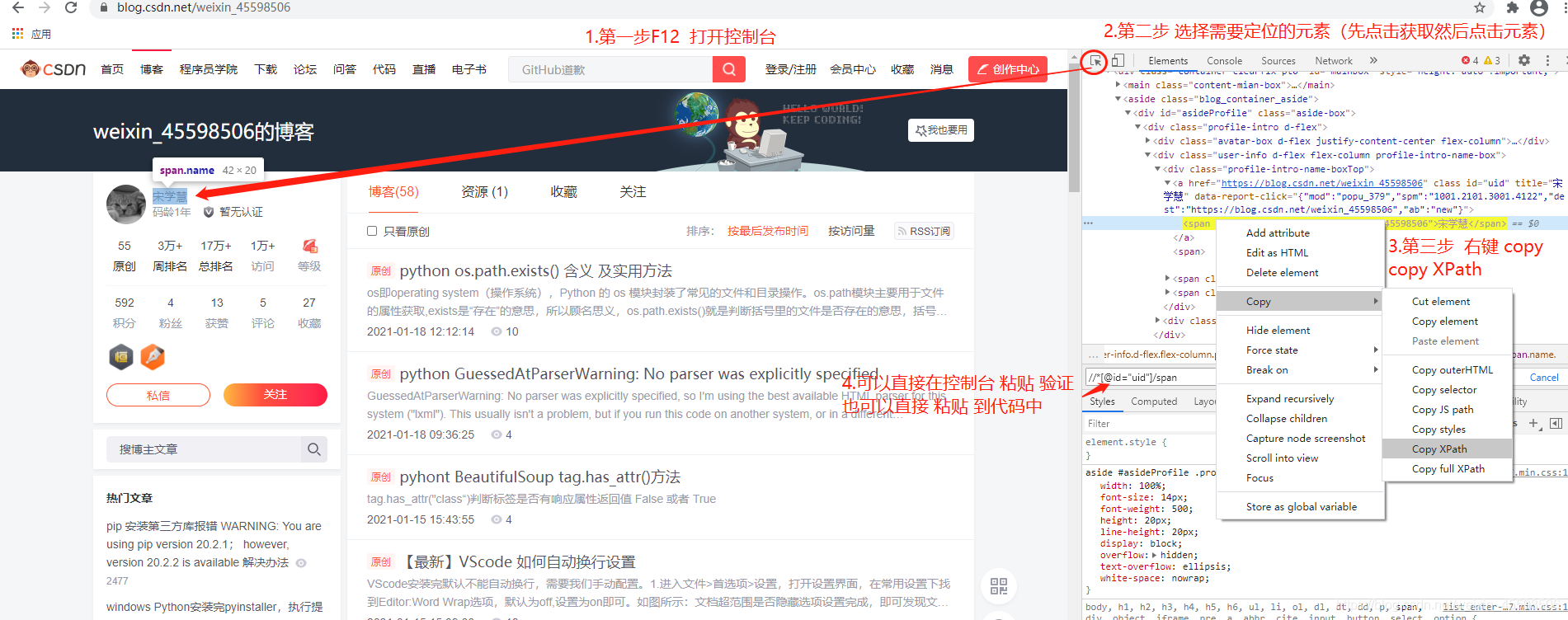
6.Chrome automatically generates Xpath expressions