Thread pool is not only a very commonly used technology in the project, but also basically a knowledge point that must be asked in the interview. Next, follow me to consolidate the relevant knowledge of thread pool. Before understanding the thread pool, let’s first understand what a process is and what a thread is
process
-
Program: generally a file composed of a set of CPU instructions, statically stored on a storage device such as a hard disk
-
Process: When a program is to be run by the computer, a runtime instance of the program is generated in the memory. We call this instance a process
After the user issues the command to run the program, a process will be generated. The same program can generate multiple processes (one-to-many relationship) to allow multiple users to run the same program at the same time without conflict.
Processes need some resources to work, such as CPU usage time, memory, files, and I/O devices, and they are executed one by one, that is, each CPU core can only run one process at any time. However, in an application, there is generally not only one task that will be executed in a single line. There will definitely be multiple tasks, and the creation of a process is time-consuming and resource-consuming, which is called a heavyweight operation.
-
The creation process takes up too many resources
-
Communication between processes requires data to be transmitted in different memory spaces, so inter-process communication will consume more time and resources
Thread
Thread is the smallest unit that the operating system can perform operation scheduling. In most cases, it is included in the process and is the actual operating unit in the process. A process can have multiple threads concurrently, and each thread performs a different task. Multiple threads in the same process share all virtual resources in the process, such as virtual address space, file descriptors, signal processing, and so on. However, multiple threads in the same process have their own call stacks.
> A process can have many threads, and each thread executes different tasks in parallel.
Data in thread
-
Local data on the thread stack : such as the local variables of the function execution process, we know that the thread model in Java is a model that uses the stack. Each thread has its own stack space.
-
Global data shared in the entire process : We know that in a Java program, Java is a process, and we
ps -ef | grep javacan see how many Java processes are running in the program, such as global variables in our Java, between different processes It is isolated, but shared between threads. -
Thread private data : In Java, we can
ThreadLocalcreate private data variables between threads.
> The local data on the thread stack can only be valid in this method, and the private data of the thread is shared by multiple functions between threads.
CPU intensive and IO intensive
Understanding whether the server is CPU-intensive or IO-intensive can help us better set the parameters in the thread pool. We will analyze how to set up the thread pool when we talk about the thread pool later. Here, we will first know these two concepts.
-
IO-intensive: CPU is idle most of the time, waiting for disk IO operations
-
CPU (computation) intensive: Most of the time the disk IO is idle, waiting for the CPU to perform calculations
Thread Pool
Thread pool is actually a kind of application of pooling technology. There are many common pooling technologies, such as database connection pool, memory pool in Java, constant pool and so on. And why is there pooling technology? The nature of the program is to process information by using system resources (CPU, memory, network, disk, etc.). For example, creating an object instance in the JVM consumes CPU and memory resources. If your program needs to be created frequently A large number of objects, and the short survival time of these objects means that they need to be destroyed frequently, so this code is likely to become a performance bottleneck. In fact, the following points are summed up.
-
Reuse the same resources, reduce waste, and reduce the cost of new construction and destruction;
-
Reduce the cost of individual management and transfer to the "pool" in a unified manner;
-
Centralized management to reduce "fragments";
-
Improve the response speed of the system, because there are existing resources in the pool, so there is no need to recreate it;
So the pooling technology is to solve our problems. Simply put, the thread pool is to save the used object, and when the object is needed next time, it will be directly taken out of the object pool and reused to avoid frequent creation. And destroyed. Everything in Java is an object, so a thread is also an object. A Java thread is an encapsulation of an operating system thread. Creating a Java thread also consumes operating system resources, so there is a thread pool. But how do we create it?
Four thread pools provided by Java
Java provides us with four methods to create thread pools.
-
Executors.newCachedThreadPool: Create an unlimited number of thread pools that can be cached. If there is no free thread pool in the thread, the task will create a new thread at this time. If the thread is useless for more than 60 seconds, the thread will be destroyed. To put it simply, it is to create unlimited temporary threads when they are not busy, and then recycle them when they are idle.public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<runnable>());} -
Executors.newFixedThreadPool: Create a fixed-size thread pool to control the maximum concurrent number of threads, and the excess threads will wait in the queue. Simply put, when you are not busy, the task will be placed in an infinite length queue.public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<runnable>());} -
Executors.newSingleThreadExecutor: Create a thread pool with a thread number of 1 in the thread pool, use a unique thread to execute tasks, and ensure that tasks are executed in the specified orderpublic static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<runnable>()));} -
-
Executors.newScheduledThreadPool: Create a fixed-size thread pool to support timing and periodic task executionpublic ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());} -
The principle of thread pool creation
We click to go to the source code of these four implementation methods, we can see that in fact, their underlying creation principles are all the same, except that the passed parameters are composed of four different types of thread pools. They are all used ThreadPoolExecutorto create. We can look at ThreadPoolExecutorthe parameters passed in the creation.
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
So what do these parameters specifically mean?
-
corePoolSize: The number of core threads in the thread pool -
maximumPoolSize: The maximum number of threads allowed in the thread pool -
keepAliveTime: When the number of existing threads is greater thancorePoolSize, then idle threads will be found to be destroyed. This parameter is to set how long idle threads will be destroyed. -
unit:time unit -
workQueue: Work queue, if the current number of threads in the thread pool is greater than the core thread, then the next task will be put into the queue -
threadFactory: When creating a thread, the thread is produced through the factory mode. This parameter is to set our custom thread creation factory. -
handler: If the maximum number of threads is exceeded, the rejection policy we set will be executed
Next, we combine these parameters to see what their processing logic is.
-
For the previous
corePoolSizetask, a thread is created when a task comes -
If the number of threads in the current thread pool is greater than
corePoolSizethen the next tasks will be put into theworkQueuequeue we set above -
If
workQueueit is also full at this time , then when the task comes again, a new temporary thread will be created, then if we setkeepAliveTimeor set it at this timeallowCoreThreadTimeOut, the system will check the activity of the thread, and destroy the thread once it times out -
If the current thread in the thread pool is greater than the
maximumPoolSizemaximum number of threads at this time , then thehandlerrejection strategy we just set will be executed
Why it is recommended not to use the thread pool creation method provided by Java
After understanding the parameters set above, let's take a look at why there is such a provision in the "Alibaba Java Manual".

img
I believe that everyone sees the four implementation principles for creating thread pools provided above, and you should know why Alibaba has such regulations.
-
FixedThreadPoolAndSingleThreadExecutor: the implementation of these two thread pools, we can see that the work queues they set are allLinkedBlockingQueue, we know that this queue is a queue in the form of a linked list, this queue has no length limit, it is an unbounded queue, then at this time If there are a large number of requests, it may be causedOOM. -
CachedThreadPoolAndScheduledThreadPool: For the implementation of these two thread pools, we can see that the maximum number of threads set by it is bothInteger.MAX_VALUE, which is equivalent to the number of threads allowed to be createdInteger.MAX_VALUE. If a large number of requests come at this time, it may also be causedOOM.
How to set parameters
So if we want to use thread pools in our projects, it is recommended to create thread pools personalized according to our own projects and machine conditions. So how to set these parameters? In order to properly customize the length of the thread pool, you need to understand your computer configuration, the required resources, and the characteristics of the task. For example, how many CPUs are installed on the deployed computer? How much memory? Is the main task execution IO-intensive or CPU-intensive? Does the task performed require a scarce resource such as a database connection?
> If you have multiple tasks of different categories and their behavior is very different, then you should consider using multiple thread pools. In this way, different thread pools can be customized according to each task, and one type of task will not be overwhelmed by another task.
-
CPU-intensive tasks: It means that there are a lot of computing operations. For example, if there are N CPUs, then the capacity of the thread pool is configured to be N+1, so that the optimal utilization can be obtained. Because the CPU-intensive thread happens to be suspended at a certain time due to a page fault or for other reasons, there happens to be an extra thread to ensure that the CPU cycle will not interrupt the work in this case.
-
IO-intensive tasks: It means that the CPU spends most of the time waiting for IO blocking operations. At this time, the capacity of the thread pool can be configured larger. At this point, you can calculate the appropriate number of your thread pool based on some parameters.
-
N: the number of CPUs
-
U: The utilization rate of the target CPU, 0<=U<=1
-
W/C: The ratio of waiting time to calculation time
-
Then the optimal pool size is
N*U*(1+W/C)
-
> Page fault (English: Page fault, also known as hard fault, hard interrupt, page fault, page missing, page fault interrupt, page fault, etc.) refers to when the software tries to access the virtual address space that has been mapped, but currently does not When a page is not loaded in physical memory, the interrupt issued by the memory management unit of the central processing unit
In fact, the size of the thread pool should be set according to your business type. For example, when the current task requires pooled resources, such as the connection pool of the database, the length of the thread pool and the length of the resource pool will affect each other. If each task requires a database connection, then the size of the connection pool will limit the effective size of the thread pool. Similarly, when the task in the thread pool is the only consumer of the connection pool, the size of the thread pool will be reversed. Will limit the effective size of the connection pool.
Thread destruction in the thread pool
The creation and destruction of threads are jointly managed by the number of core threads (corePoolSize), maximum number of threads (maximumPoolSize), and thread survival time (keepAliveTime) of the thread pool. Next, let’s review how the thread pool creates and destroys threads.
-
Current thread number <core thread number: create a thread from a task
-
Current number of threads = number of core threads: a task will be added to the queue
-
Current thread number> core thread number: At this time, there is a prerequisite that the queue is full before a new thread will be created. At this time, thread activity check will be started,
keepAliveTimeand threads that are not active at time will be recycled.
So some people here might think corePoolSizeof setting the number of core threads to 0 ( if you remember the above CachedThreadPool, you should remember that the number of core threads is 0 ), because if you set this way, the threads will be dynamically created and idle. When there is no thread, when it is busy, create a thread in the thread pool. This idea is good, but if we customize the parameter to set this parameter to 0, and just set the waiting queue is not SynchronousQueue, then there will be a problem, because the new thread will only be created when the queue is full. I use an unbounded queue in the code below LinkedBlockingQueue. In fact, let’s take a look at the output.
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(0,Integer.MAX_VALUE,1, TimeUnit.SECONDS,new LinkedBlockingQueue<>());for (int i = 0; i < 10; i++) {threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.printf("1");}});}
You can take a look at the effect of the demonstration. In fact, it 1is printed every second. In fact, this is contrary to our original intention of using the thread pool, because ours is equivalent to a single thread running.

But if we replace the work queue with SynchronousQueueit, we find that these 1are output together.

>It is SynchronousQueuenot a real queue, but a mechanism to manage the transfer of information directly between threads. Here you can simply imagine it as a producer producing messages and handing them over SynchronousQueue, and if there are threads on the consumer side to receive, then this The message will be delivered directly to the consumer, otherwise it will be blocked.
So when we set some parameters in the thread pool, we should think about the process of creating and destroying threads, otherwise our custom thread pool might not be as good as using the four thread pools provided by Java.
Rejection strategy in thread pool
ThreadPoolExecutorFour rejection strategies are provided for us. We can see that the rejection strategies provided by the four thread pool creation provided by Java are the default rejection strategies defined by it. So what are the other rejection strategies besides this rejection strategy?
private static final RejectedExecutionHandler defaultHandler =new AbortPolicy();
We can RejectedExecutionHandlerrealize that the rejection strategy is an interface , which means that we can customize our own rejection strategy. Let's take a look at what are the four rejection strategies provided by Java.
public interface RejectedExecutionHandler {/*** Method that may be invoked by a {@link ThreadPoolExecutor} when* {@link ThreadPoolExecutor#execute execute} cannot accept a* task. This may occur when no more threads or queue slots are* available because their bounds would be exceeded, or upon* shutdown of the Executor.** <p>In the absence of other alternatives, the method may throw* an unchecked {@link RejectedExecutionException}, which will be* propagated to the caller of {@code execute}.** @param r the runnable task requested to be executed* @param executor the executor attempting to execute this task* @throws RejectedExecutionException if there is no remedy*/void rejectedExecution(Runnable r, ThreadPoolExecutor executor);}
AbortPolicy
This rejection strategy is the default rejection strategy provided by the four thread pool creation methods provided by Java. We can look at its implementation.
public static class AbortPolicy implements RejectedExecutionHandler {public AbortPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());}}
So this rejection strategy is to throw RejectedExecutionExceptionan exception
CallerRunsPolicy
This rejection strategy is simply to give the task to the caller for direct execution.
public static class CallerRunsPolicy implements RejectedExecutionHandler {public CallerRunsPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}}}
Why is it handed over to the caller for execution? We can see that it calls a run()method, not a start()method.
DiscardOldestPolicy
It should be seen from the source code that this rejection strategy is to discard the oldest task in the queue and then execute it.
public static class DiscardOldestPolicy implements RejectedExecutionHandler {public DiscardOldestPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}}}
DiscardPolicy
It should be seen from the source code that this rejection strategy is to do nothing for the current task. In simple terms, it simply discards the current task and does not execute it.
public static class DiscardPolicy implements RejectedExecutionHandler {public DiscardPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}}
The rejection strategy of the thread pool provides us with these four implementation methods by default. Of course, we can also customize the rejection strategy to make the thread pool more in line with our current business. It will be explained later when Tomcat customizes its own thread pool. Your own rejection strategy.
Thread starvation deadlock
The thread pool brings a new possibility to the concept of "deadlock": thread starvation deadlock. In the thread pool, if one task to another task to submit to the same Executor, it will usually lead to a deadlock. The second thread stays in the work queue waiting for the completion of the execution of the first submitted task, but the first task cannot be completed because it is waiting for the completion of the second task. The figure is as follows
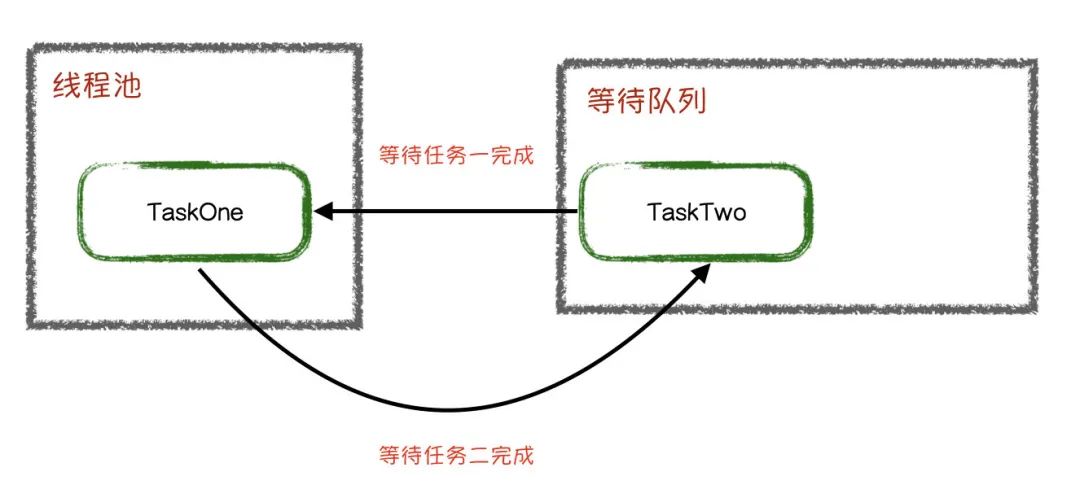
Expressed in code as follows, note that the thread pool we defined here is that there is SingleThreadExecutoronly one thread in the thread pool, so that it is easy to simulate such a situation, if in a larger thread pool, if all threads are waiting for others and are still working The task of the queue is blocked, then this situation is called a thread starvation deadlock . So try to avoid processing two different types of tasks in the same thread pool.
public class AboutThread {ExecutorService executorService = Executors.newSingleThreadExecutor();public static void main(String[] args) {AboutThread aboutThread = new AboutThread();aboutThread.threadDeadLock();}public void threadDeadLock(){Future<string> taskOne = executorService.submit(new TaskOne());try {System.out.printf(taskOne.get());} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}}public class TaskOne implements Callable{@Overridepublic Object call() throws Exception {Future<string> taskTow = executorService.submit(new TaskTwo());return "TaskOne" + taskTow.get();}}public class TaskTwo implements Callable{@Overridepublic Object call() throws Exception {return "TaskTwo";}}}
Extend ThreadPoolExecutor
If we want to expand the thread pool, we can use ThreadPoolExecutorsome of the interfaces reserved for me to allow us to customize the thread pool in a deeper level.
Thread factory
If we want to customize some names for each thread in our thread pool, then we can use thread factories to implement some customized operations. As long as we pass our custom factory to it ThreadPoolExecutor, whenever the thread pool needs to create a thread, it must be created through the factory defined by us. Next, let's take a look at the interface ThreadFactory. As long as we implement this interface , we can customize the unique information of our thread.
public interface ThreadFactory {/*** Constructs a new {@code Thread}. Implementations may also initialize* priority, name, daemon status, {@code ThreadGroup}, etc.** @param r a runnable to be executed by new thread instance* @return constructed thread, or {@code null} if the request to* create a thread is rejected*/Thread newThread(Runnable r);}
Next we can look at the thread pool factory class we wrote ourselves
class CustomerThreadFactory implements ThreadFactory{private String name;private final AtomicInteger threadNumber = new AtomicInteger(1);CustomerThreadFactory(String name){this.name = name;}@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r,name+threadNumber.getAndIncrement());return thread;}}
Just need to add this factory class when the thread pool is instantiated
public static void customerThread(){ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(0,Integer.MAX_VALUE,1, TimeUnit.SECONDS,new SynchronousQueue<>(),new CustomerThreadFactory("customerThread"));for (int i = 0; i < 10; i++) {threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {System.out.printf(Thread.currentThread().getName());System.out.printf("\n");}});}}
Next we execute this statement and find that the name of each thread has changed
customerThread1customerThread10customerThread9customerThread8customerThread7customerThread6customerThread5customerThread4customerThread3customerThread2
Extend by inheriting ThreadPoolExecutor
When we look at the ThreadPoolExecutorsource code, we can find that there are three methods in the source code.protected
protected void beforeExecute(Thread t, Runnable r) { }protected void afterExecute(Runnable r, Throwable t) { }protected void terminated() { }
> The protected modified members are visible to this package and its subclasses
We can override these methods through inheritance, and then we can carry out our unique extensions. The thread that executes the task calls beforeExecuteand afterExecutemethods, through which you can add log, timing, monitor, or information collection functions at the same level. Whether the task returns from run normally or throws an exception, it afterExecutewill be called ( if an Error is thrown after the task is completed, it afterExecutewill not be called ). If beforeExecuteone is thrown RuntimeException, the task will not be executed and afterExecutewill not be called.
Call terminated when the thread pool is closed, that is, after all tasks have been completed and all worker threads have been closed, terminated can be used to release various resources allocated by the Executor in its life cycle, and it can also send notifications. , Record logs or mobile phone finalize statistics and other operations.