1. Storage concept features
Features
优先读写内存
- Write: write directly to memory
- Read: read the memory first, if not, then read HDFS
- All data in the entire Hbase are arranged in the order of Rowkey
- When querying data, you can
rowkey前缀匹配查询
Rowkey是整个Hbase的唯一索引- Data type: The underlying storage types of Hbase are all bytes
- data structure:
KV结构,每一列在底层存储都是一个KV
Key:Rowkey+列族名称+列的名称+时间戳
- 20200101_001 column=basic:age, timestamp=1593247238403
Value:值
concept
RowKey:类似于主键的概念
- Uniquely mark a line
基于rowkey排序唯一索引
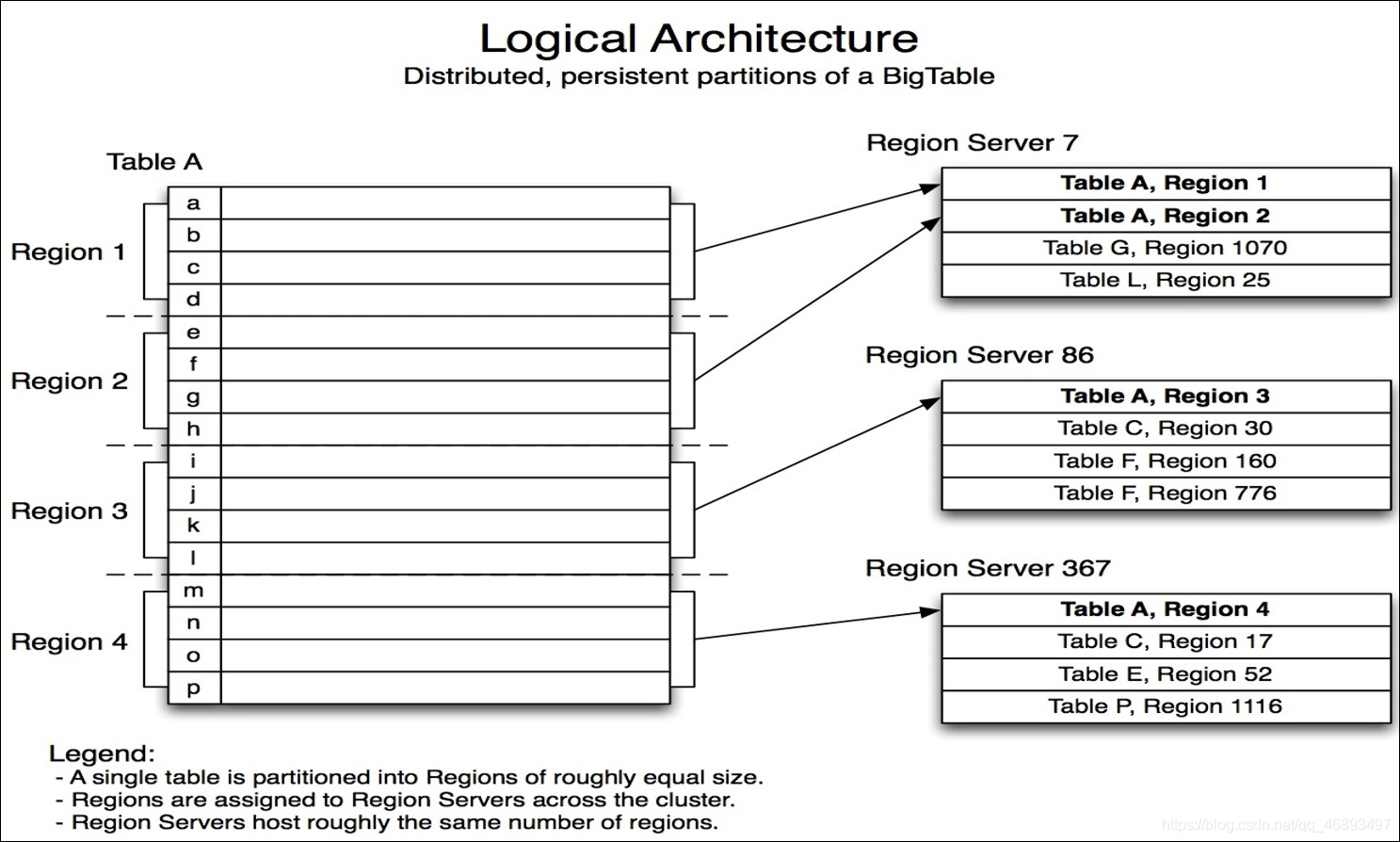
RegionServer:HBASE架构中的从节点
- All Hbase data is written to the RegionServer, and data is also read from the RegionServer
- Write: written into the memory of Regionserver
- Read: read the memory of RegionServer first
- There will be multiple slave nodes
每一台RegionServer上都可以有很多个Region- Similar to DataNode
RegionServer是将数据存储在内存中- RegionServer will call HDFS client to write data to HDFS
DataNode是将数据存储在磁盘上
Region:RegionServer中的存储单元
- Just
数据表的分区

一个Region必然会被某一个RegionServer所管理一个RegionServer可以管理多个Region
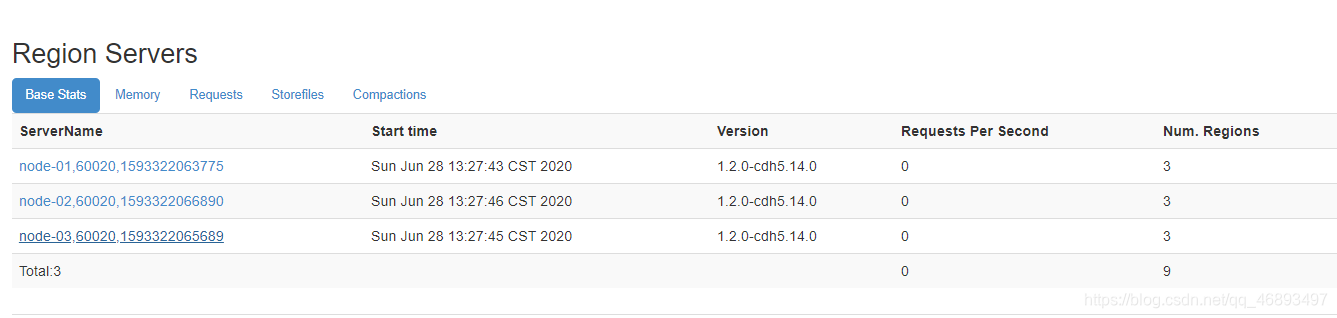
Thinking: I have a table, I have a lot of data, and I want to write to this table, how can I make this table distributed?
- Only with this table
分布式, can I read and write data in parallel in a distributed manner?
- Let a table have multiple partitions, and different partitions are stored on different machines
region:分区regionserver:region所在的机器
- Write data to the table, according to certain rules, write to a certain partition
- Suppose there is a table with three partitions
- region0:node-01
- region1:node-02
- region2:node-03
- The first data: write to the first partition region0
- The second piece of data: write to the second partition region1
- The third piece of data: write to the third partition region2
- ……
- Implement distributed storage
In Hbase:
- Each table has only one partition at the beginning by default
每个Region都有一个范围- If a table has only one region: -oo ~ +oo

- If a table has two regions
- region0 : -oo ~ 1000
- region1:1000 ~ +oo
- ……
- If a table has five partitions
- region0 : -oo ~ 10
- region1:10 ~ 20
- region2:20 ~ 30
- region3:30 ~ 40
- region4:40 ~ +oo
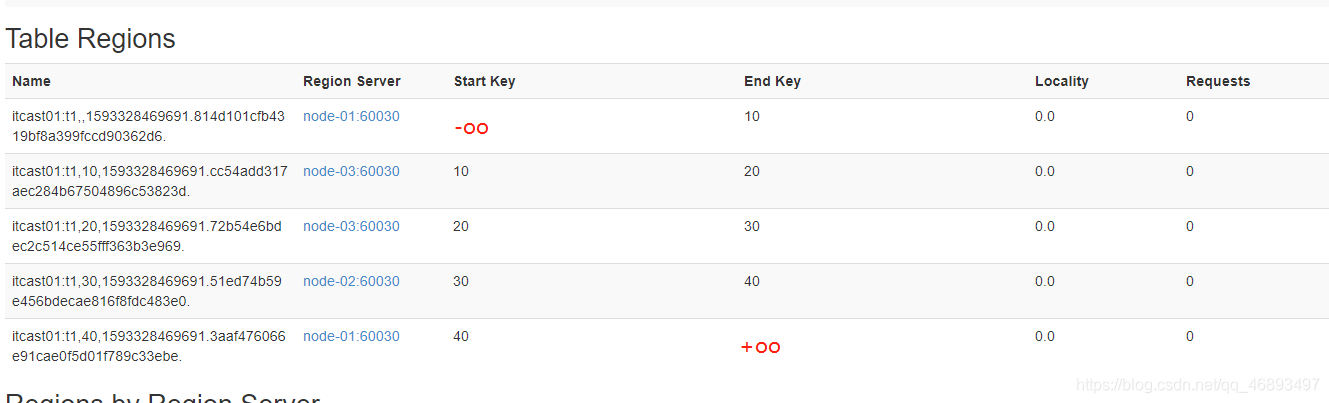
分区规则:根据rowkey所属的范围
| concept |
HDFS |
Hbase |
| data |
file |
table |
| Split |
Block: Block |
分区:Region |
| rule |
128M a Block |
范围 |
| machine |
DataNode |
RegionoServer |
|
Block has a copy |
分区没有副本 |
- Demo: a table has multiple partitions
create 'itcast01:t1', 'info', SPLITS => ['10', '20', '30', '40']

- Partition rules: partition according to rowkey
- The relationship between Region and table
Region就是表的分区, A table has only one partition by default, and there can be multiple partitions- When writing data to the table, it will be written to different partitions of this table according to the partitioning rules
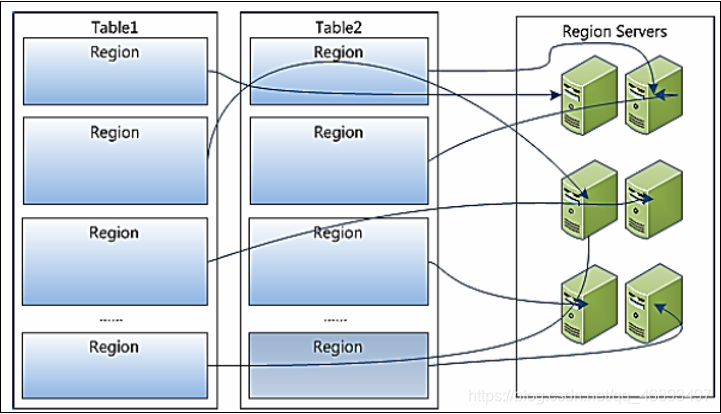
- The relationship between Region and RegionServer
- Region is stored in RegionServer and managed by RegionServer
Region是RegionServer负载均衡的最小单元
- regionserver1:10个region
- regionserver2: 5 regions
- regionserver3: 3 regions
- |
- |Load Balancing: Balanced Distribution of Regions
- |
- regionserver1:6个region
- regionserver2: 6 regions
- regionserver3: 6 regions
Store: Smaller storage unit in Region
region是表在rowkey的方向上进行了划分多个分区
Store是表中列的划分,store就是列族- The data corresponding to each Rowkey in this table has a column family, and there is a Store in the corresponding region
- The data of different column families are stored in different Stores, and the data of the same column families are stored together
- Why design the concept of column family?
- Just
为了将经常一起读写的数据存在一起(相似io属性)
加快读写的 效率
memstore: The memory area where data is stored in the Store
每个store中都有一个memstore,用于存储写入的数据不同列族就是store的数据写入不同的内存- The memory of the regionserver where this region is used is used
StoreFile: The file refreshed from the memory in each Store is storefile
一个Store中逻辑上可能会有多个storefile文件- Storefile is stored on HDFS, encapsulation of HFILE

2. Logical structure
put 'ns:tbname','rowkey',cf:col,value
- RegionServer: slave node, used to store all data in Hbase
- Table: All data exists in the form of tables, and reads and writes are specified tables
- Region: to realize the association between the table and the RegionServer, the partition of the table, used to
rowkeyturn the table into a distributed
- Store: Each partition
列族is divided into stores according to internal partitions, smaller partitions
- MemStore: The memory area of Regionserver, each Store has 1 MemStore
- StoreFIle: multiple, flashed data in the memory
- Logically belongs to this store
- Really stored on HDFS
分区没有副本,如果分区所在的宕机了怎么办?- Hbase will restore this region on other regionservers
- How can the data be guaranteed not to be lost?
StoreFile可以通过HDFS副本进行恢复- How to recover the data in memStore?
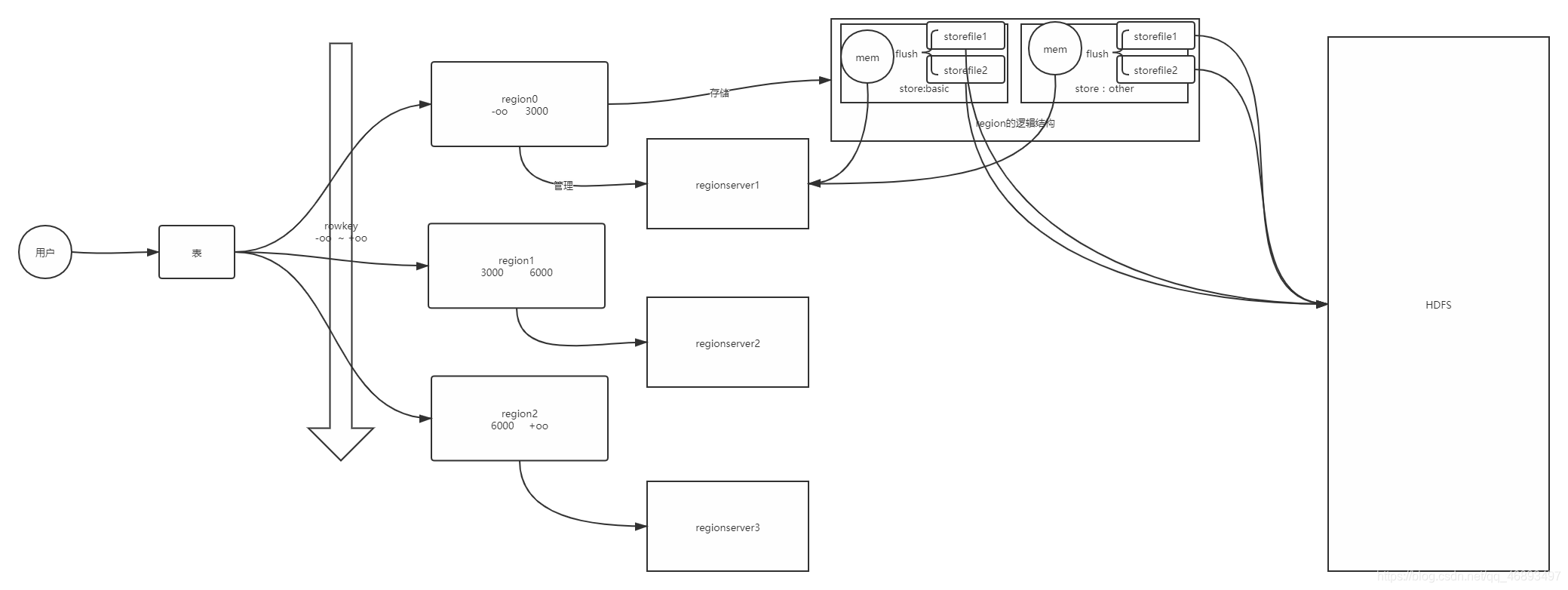
- Monitoring logical structure
- table

- Partition: Region

3. Physical structure
- The machine where the regionServer is located
- The machine where the DataNode is located
- Structure of storage on HDFS
- NameSpace: corresponds to a directory in HDFS
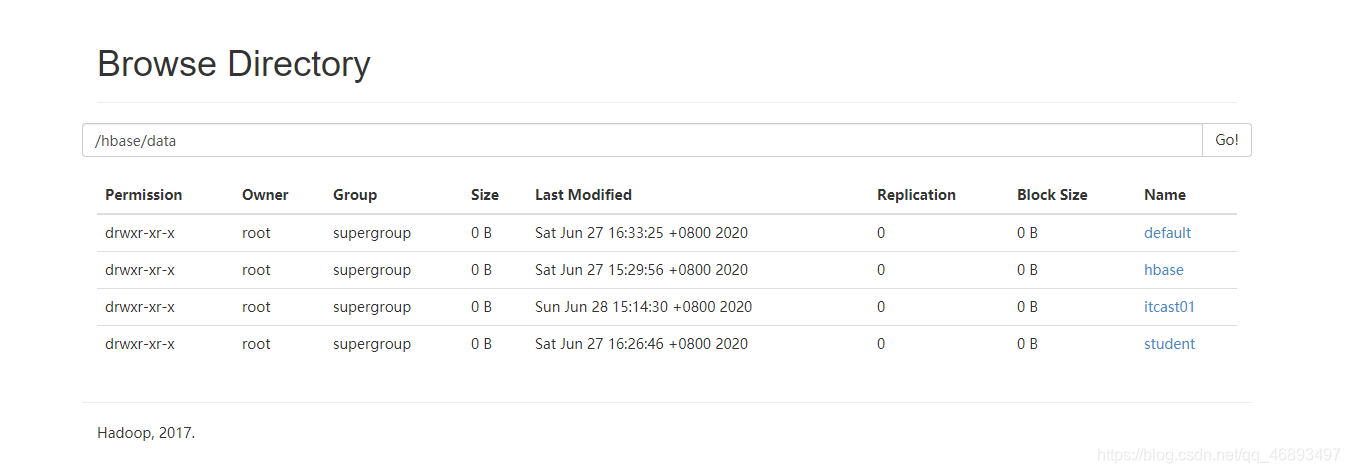
- Table: Corresponding to a directory on HDFS
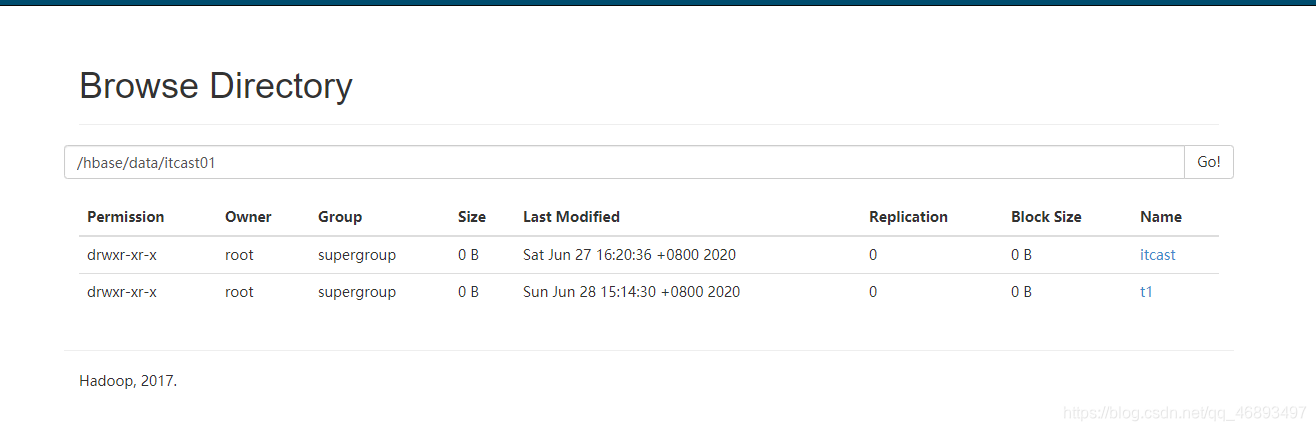
- Region: corresponds to a directory on HDFS
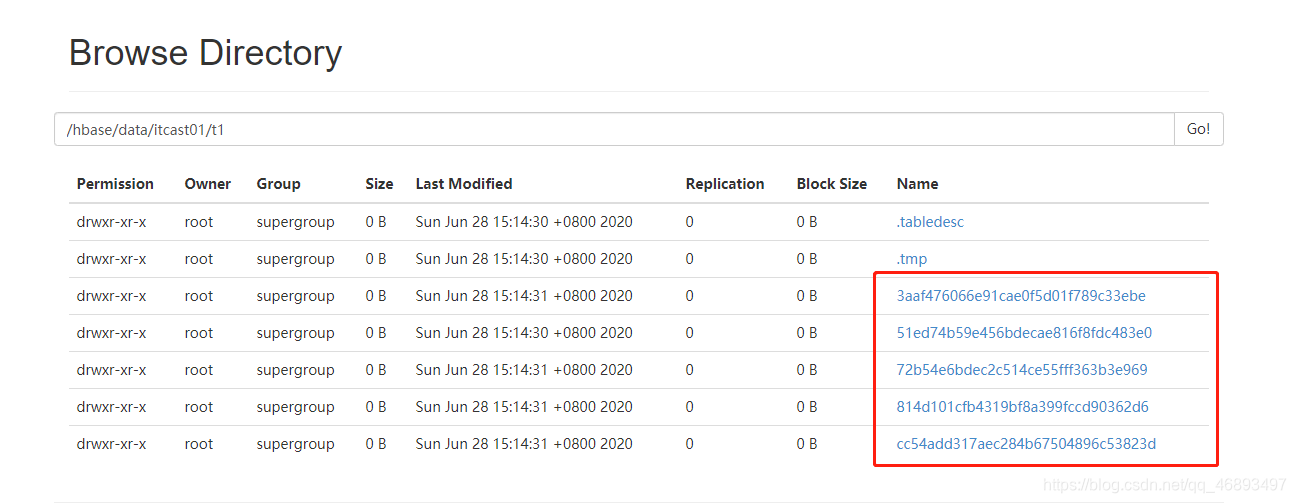
- Store: corresponds to a directory on HDFS, that is, column family

- StoreFile: File on HDFS
4. Storage architecture
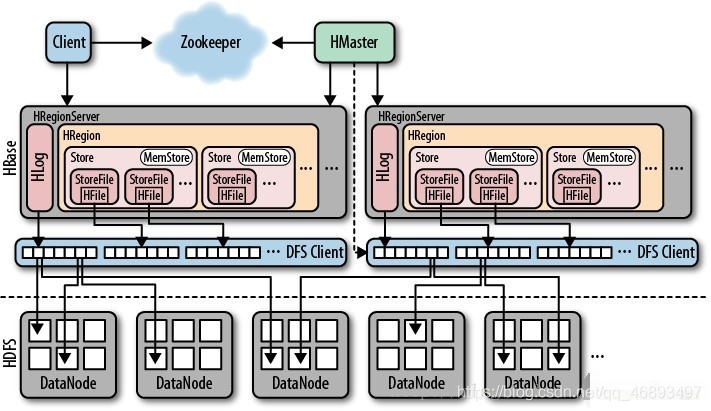
- Step 1: The client finds the corresponding region based on the table name and rowkey
- How does it know that this table has some regions?
- How does it know the extent of each region?
- How does it know which regionserver this region is on?
- The second step:
客户端会请求这个region所在的Regionserver,提交写请求
- third step:
RegionServer根据我们的请求来写入Region,根据列族来判断写入哪个Store
- the fourth step:
将这个数据读写Store中的MemStore
- If it is read:
先读memstore ,如果没有读StoreFIle
- If writing: write directly to MemStore
- When the data in MemStore reaches certain conditions, Flush will be triggered automatically
- Flash the data in memStore into Storefile file and write it to HDFS