1. HashMap constructor
HashMap provides us with three constructors to create HashMap objects.
1. The parameterless constructor public HashMap(): The hashmap object created by the parameterless constructor has a default capacity of 16, and a default load factor of 0.75.
2. Parameter constructor public HashMap (int initialCapacity, float loadFactor): Using this constructor, we can specify the initial capacity and load factor of the hashmap, but at the bottom of the hashmap, it will not necessarily be initialized to the capacity we passed in, but will It is initialized to the smallest power of 2 greater than or equal to the passed value. For example, if we pass in 17, the hashmap will be initialized to 32 (2^5). So how does hashmap efficiently calculate the smallest power of 2 greater than or equal to a number? The source code is as follows:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
Its design can be said to be very clever. The basic idea is that if the low bits of a binary number are all 1, then this number +1 must be a power of two number . Let's take an example:

As you can see, its calculation process is: first subtract 1 from the number cap we specify (the reason for subtracting 1 is that if cap is exactly a power of 2 number, it can also be calculated correctly), and then cap-1 Unsigned right shifts by 1, 2, 4, 8, and 16 bits (totaling exactly 31 bits), and perform bitwise OR operation with the previous number after each shift. Through this operation, Will make the final result low bits are all 1. Then finally add 1 to the result, and you will get a power of two.
3. Another parameterized constructor is the parameterized constructor public HashMap(int initialCapacity). The only difference between this constructor and the previous one is that the load factor cannot be specified.
2. HashMap insertion mechanism
1. Insert method source code
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 初始化桶数组 table, table 被延迟到插入新数据时再进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果桶中不包含键值对节点引用,说明当前数组下标下不存在任何数据,则将新键值对节点的引用存入桶中即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果hash相等,并且equals方法返回true,这说明key相同,此时直接替换value即可,并且返回原值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果第一个节点是树节点,则调用putTreeVal方法,将当前值放入红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果第一个节点不是树节点,则说明还是链表节点,则开始遍历链表,将值存储到链表合适的位置
for (int binCount = 0; ; ++binCount) {
//如果遍历到了链接末尾,则创建链表节点,将数据存储到链表结尾
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断链表中节点树是否超多了阈值8,如果超过了则将链表转换为红黑树(当然不一定会转换,treeifyBin方法中还有判断)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果在链表中找到,完全相同的key,则直接替换value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//e!=null说明只是遍历到中间就break了,该种情况就是在链表中找到了完全相等的key,该if块中就是对value的替换操作
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//加入value之后,更新size,如果超过阈值,则进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
2. Insert the flowchart
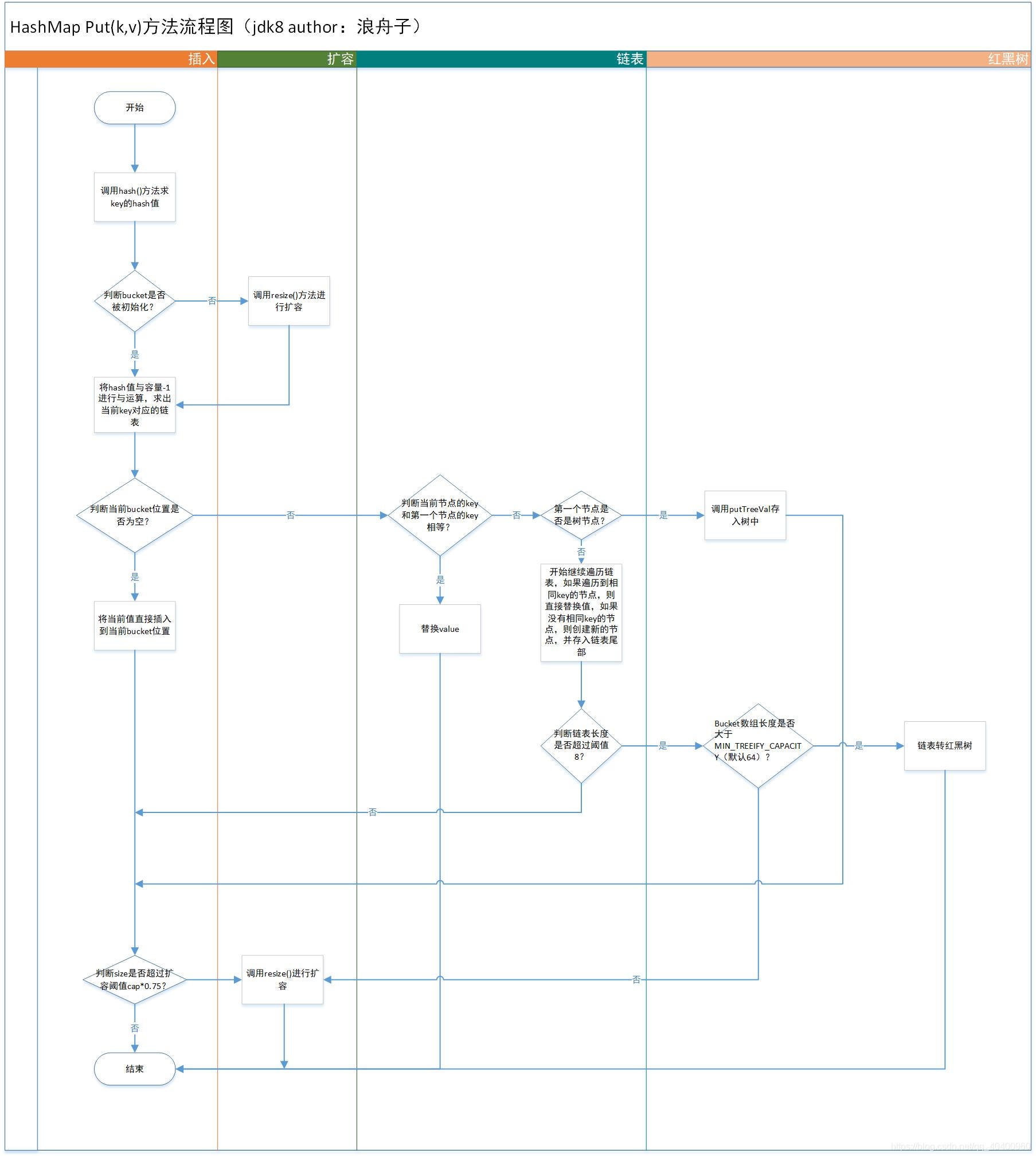
(1) When putting a kv, first call the hash() method to calculate the hashcode of the key, but in the hashmap, it is not simply calling the hashcode of the key to obtain a hash code, and the disturbance function is also used To reduce hash collisions. The source code is as follows:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
As you can see from the source code, the final hash value is the result of XORing the original hash code and the value obtained by shifting the original hash code 16 bits to the right. 16 is exactly half of 32, so the hashmap moves the high bit of the hashcode to the low bit, and then spreads the high bit to the low bit through the exclusive OR operation, thereby reducing hash collisions. As for why the conflict can be reduced, we can look at the author's comments on the hash method:
Computes key.hashCode() and spreads (XORs) higher bits of hash to lower. Because the table uses power-of-two masking, sets of hashes that vary only in bits above the current mask will always collide. (Among known examples are sets of Float keys holding consecutive whole numbers in small tables.) So we apply a transform that spreads the impact of higher bits downward. There is a tradeoff between speed, utility, and quality of bit-spreading. Because many common sets of hashes are already reasonably distributed (so don’t benefit from spreading), and because we use trees to handle large sets of collisions in bins, we just XOR some shifted bits in the cheapest possible way to reduce systematic lossage, as well as to incorporate impact of the highest bits that would otherwise never be used in index calculations because of table bounds.
From the comments, we can conclude that the reason for the author's dissemination from high to low is: when hashmap calculates the bucket subscript, the calculation method is hash&n-1, n is a power of 2, so hash&n-1 is just taken out For example, if n is 16, then hash&n-1 takes out the low four bits of the hash. If the low four bits of multiple hashes are exactly the same, this leads to an always collide (conflict), even if the hashes are different. Therefore, the high bits are spread to the low bits, and the high bits are also involved in the calculation, thereby reducing conflicts and making data storage more hashed.
(2) After calculating the hash, call the putVal method to store the key-value. In the putVal method, it is first necessary to determine whether the table is initialized (because the hashmap is lazily initialized, and the table is not initialized when the object is created), if the table has not been initialized, use the resize method to expand.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
(3) Calculate the bucket subscript where the current key is located through (n-1)&hash. If there is no data stored in the current subscript in the current table, create a linked list node and store the current kv directly at the subscript location.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
(4) If there is already data at the table subscript, first determine whether the current key is exactly equal to the key stored at the subscript. If they are equal, replace the value directly and return the original value, otherwise continue to traverse the linked list or store it in the red Black tree.
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
(5) If the node at the current subscript is a tree node, it is directly stored in the red-black tree
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
(6) If it is not a red-black tree, traverse the linked list. If an equal key is found in the process of traversing the linked list, then replace the value. If there is no equal key, store the node at the end of the linked list (the tail is used in jdk8). Interpolation), and check whether the node tree in the current linked list exceeds the threshold 8. If it exceeds 8, the linked list is converted into a red-black tree by calling the treeifyBin method.
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
(7) After the data is stored, it is necessary to determine whether the size of the current hashmap exceeds the expansion threshold Cap*load_fact, if it is greater than the threshold, call the resize() method to expand.
f (++size > threshold)
resize();
The capacity of HashMap after expansion is twice the original capacity. The basic mechanism is to create a table with twice the capacity, then dump the data into a new hash table, and return the new hash table. The difference from jdk1.7 is that multi-dumping in jdk1.8 has been optimized, and there is no need to recalculate the bucket subscript. The source code of the implementation is as follows:
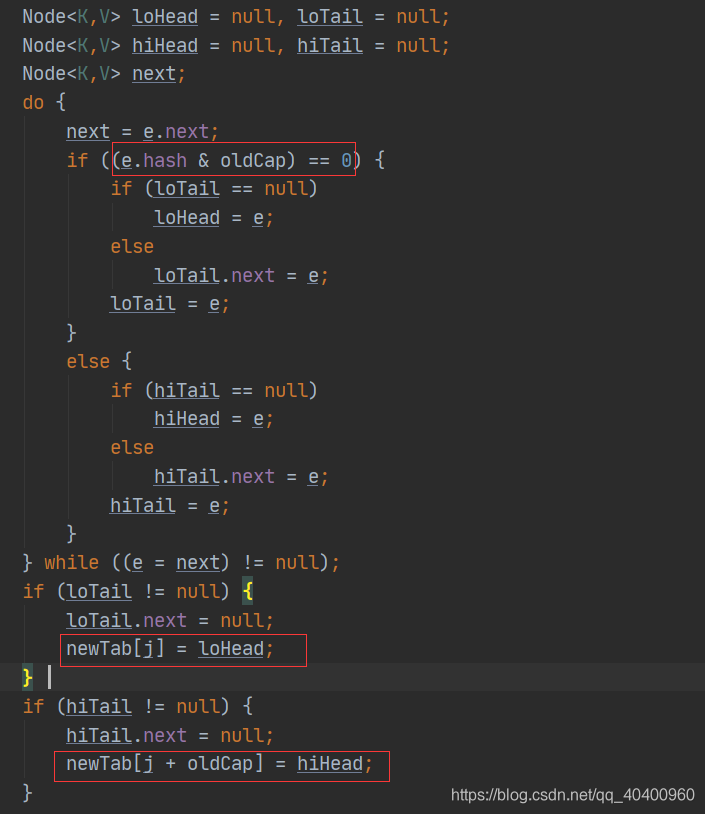
from the source code, we can see that if a key hash and the original capacity The bitwise AND operation result of oldCap is 0, then the bucket subscript before expansion is equal to the bucket subscript after expansion, otherwise the bucket subscript after expansion is the original subscript plus oldCap. The basic principles used are summarized as follows:
1. If the bitwise AND operation of a number m and a power of 2 number n is not equal to 0, then: m&(n 2-1)=m&(n-1)+n
Understanding: a power of 2 For the square number n, only one bit in the binary is 1 (assuming that the k-th bit is 1), and the other bits are all 0. If the bitwise AND operation of a number m and n results in 0, it means the binary number of m The k bit must be 0, so the value represented by the first n bits of m and the first n-1 bits must be equal.
2. If a number m and a power of 2 number n are subjected to a bitwise AND operation to be equal to 0, then: m&(n 2-1)=m&(n-1)
Understanding: a power of 2 number n , In the binary system, only one bit is 1 (assuming that the k-th bit is 1), and the other bits are all 0. If the result of bitwise AND operation of a number m and n is not 0, it means the k-th bit in the binary system of m It must be 1, then the difference between the first n bits of m and the value represented by the first n-1 bits is exactly the number represented by 1 in the kth position, and the second number is exactly n.
Schematic diagram:
