HDFS read file process:
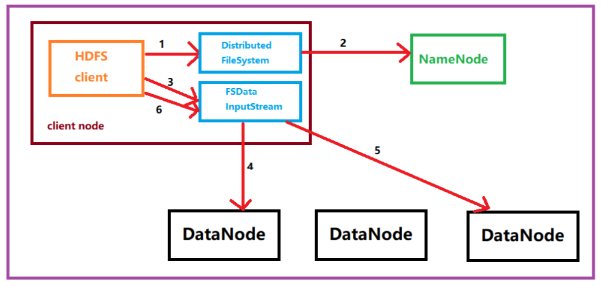
Brief description of the process of reading files:
1. The client initiates a data read request to the NameNode;
2. The NameNode responds to the request and tells the client the data block location of the file to be read (which DataNode exists);
3. The client reads the data to the corresponding DataNode, and when the data is read Reach the end, close the connection with this DataNode, and look for the next data block, until the file data is all read;
4. Finally, close the output stream.
Detailed interpretation of the process of reading files:
1. The client calls the open method of the FileSystem instance to obtain the input stream InputStream corresponding to this file.
2. Call the NameNode remotely through RPC to obtain the storage location of the data block corresponding to the file in the NameNode, including the storage location of the copy of the file (mainly the address of each DataNode).
3. After obtaining the input stream, the client calls the read method to read the data. Select the nearest DataNode to establish a connection and read data.
4. If the client and one of the DataNodes are located on the same machine (such as the mapper and reducer in the MapReduce process), then the data will be read directly from the local.
5. Reach the end of the data block, close the connection with this DataNode, and then find the next data block again. Until the file data is all read;
6. The client calls close to close the input stream DFS InputStream
HDFS file writing process:
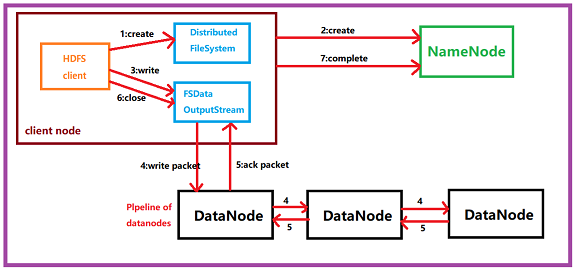
Brief description of file writing process:
1. The client initiates a write data request to the NameNode;
2. The corresponding request of the NameNode (NameNode will check whether the file to be created already exists, whether the creator has permission, a record will be created if it succeeds, and an exception will be reported if it fails);
3. The client The file is sliced (divided into data blocks), and then the data blocks are uploaded and sent one by one. Each data block must be written to the three DataNodes;
4. After success, the DataNode will return a confirmation queue to the client and the client The client performs validation, and then the client uploads the next data block to the DataNode until all data blocks are written;
5. When all data blocks are successfully written, the client sends a feedback to the NameNode and closes the data stream.
Detailed interpretation of the document writing process:
1. Use the client provided by HDFS to initiate an RPC request to the remote NameNode;
2. The NameNode will check whether the file to be created already exists and whether the creator has permission to operate. If it succeeds, it will create a record for the file, otherwise it will Let the client throw an exception;
3. When the client starts to write a file, the client will divide the file into multiple packets, and manage these packets in the form of a data queue "data queue" internally. And apply for blocks to the NameNode to obtain a suitable DataNode list for storing replicas. The size of the list is determined by the replication settings in the NameNode;
4. Start to write packets into all replicas in the form of pipelines. The client writes the packet to the first DataNode in a stream. After the DataNode stores the packet, it passes it to the next DataNode in the pipeline until the last DataNode. This way of writing data is a pipeline forms;
5, will return after the last DataNode successfully stored a ack packet (confirmation queue), delivered to the client in the pipeline, in the client's internal development library maintains "ack queue", successfully received ack packet datanode returned Then the corresponding packet will be removed from the "data queue";
6. If a DataNode fails during the transmission process, the current pipeline will be closed, the failed DataNode will be removed from the current pipeline, and the remaining blocks will continue to be used in the remaining DataNodes. Form transmission, and the NameNode will allocate a new DataNode to keep the number of replicas set;
7. After the client finishes writing the data, it will call the close() method on the data stream to close the data stream