mysql data storage structure
The system will generate a table_name.ibd file for each table separately. In this file, data related to the table, indexes, and internal data dictionary information of the table are stored. The table structure file ends with .frm, which has nothing to do with the storage engine.
Schematic diagram

What is an index
Index is essentially a data structure
Why should there be an index
The search engine can only scan each row of the entire table and compare and determine whether the value of the index is equal to the condition value. We know that pure memory operations are fast, but it is relatively slow to fetch data from the disk to the memory. When there is a large amount of data in the table, the number of interactions between the memory and the disk greatly increases, which leads to low query efficiency. You can quickly find the data you want through the index
Comparison case of not using index and using index
Do not use the index situation:
Let me briefly introduce disk I/O and read-ahead. The disk reads data, which takes into account the mechanical movement. The time it takes to read data each time can be divided into three parts : seek time, rotation delay, and transmission time . The seek time refers to the time required for the magnetic arm to move to the specified disk. The mainstream disk is generally below 5ms; the rotation delay refers to the disk rotation speed we often say, such as 7200 revolutions for a disk, which means the disk energy per minute. Turn 7200 times, which is 120 times per second, and the rotation delay is 1/120/2=4.17ms; transmission time refers to the time to read data from the disk or write data to the disk, generally at zero A few milliseconds, compared to the first two, can be ignored. Then the time to access a disk, that is, the time of a disk I/O is approximately equal to 5+4.17=9.17ms, about 9ms, which sounds good, but the million-level data of the database reaches 9000s after one pass. If the waiting time of your query function reaches this level, you can basically pack it home. But if you use the index
Use index
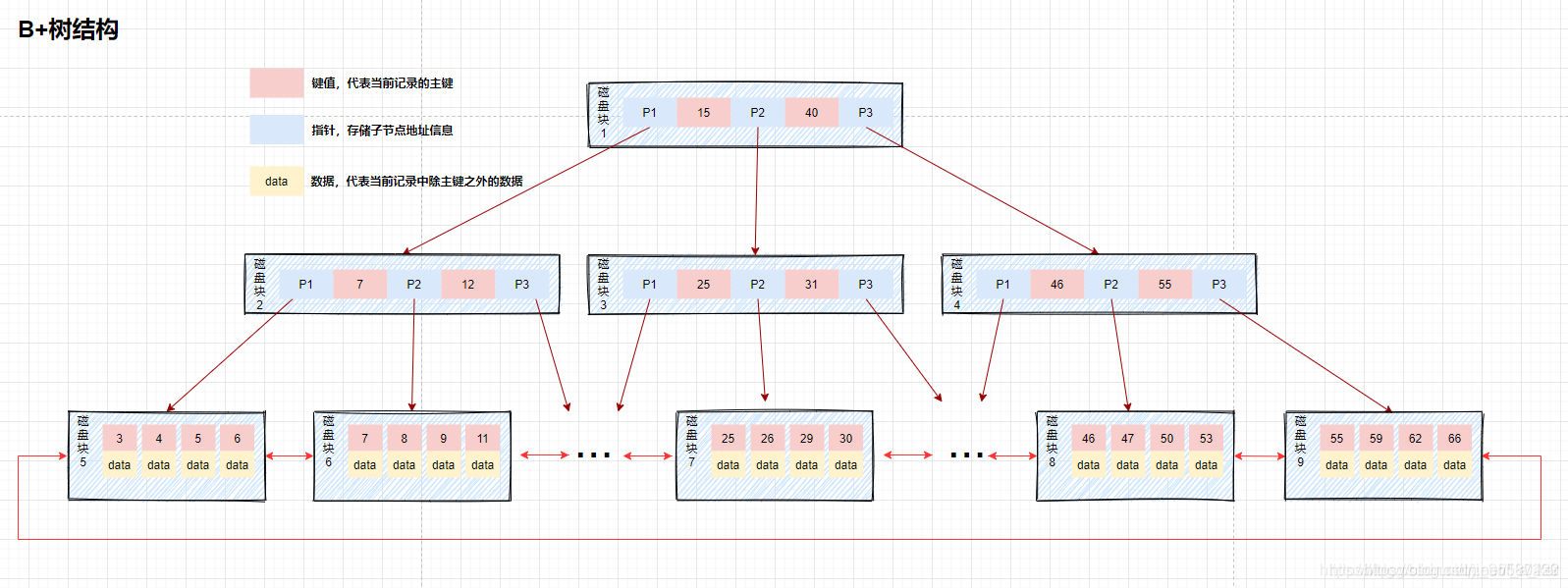
The page size in the nnoDB storage engine is 16KB, the primary key type of the general table is INT (occupies 4 bytes) or BIGINT (occupies 8 bytes), and the pointer type is generally 4 or 8 bytes, that is, one The page (a node in the B+Tree) stores approximately 16KB/(8B+8B)=1K key values (because it is an estimate, for the convenience of calculation, the value of K here is 〖10〗^3).
In other words, a B+Tree index with a depth of 3 can maintain 10^3 * 10^3 * 10^3 = 1 billion records. (There is an error in this calculation method, and no leaf nodes are calculated. If the leaf node is calculated, the depth is 4).
We only need to perform three IO operations to find the data we want from 1 billion pieces of data. At this time It is recommended to jump hammer DBA directly. The highlight moment that you brag about has arrived, brothers.
The meaning of the index
Index is a data structure that helps MySQL obtain data efficiently.
Index structure (B+ tree)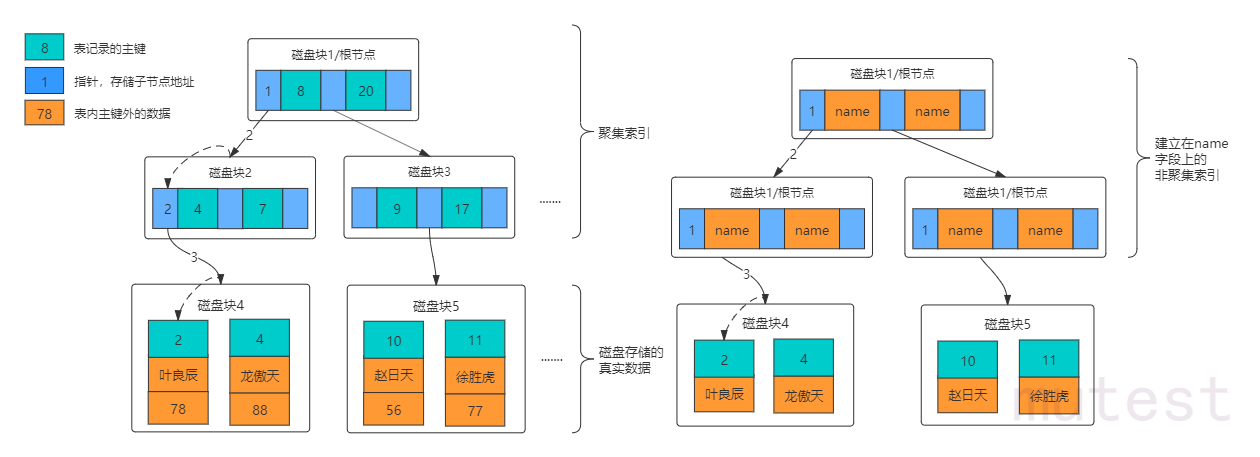
Index execution process (clustered index)
Non-clustered indexes need to return to the table (leaf nodes store the primary key id and need to go through the primary key index tree again after checking)
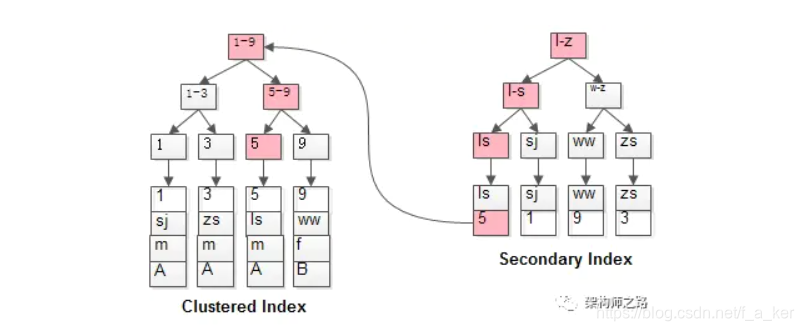
Index classification
- According to the data stored in the leaf node, it is divided into: clustered index (leaf node stores all data of a record) (primary key index is clustered index), non-clustered index (leaf node stores primary key id) [non-clustered index check finished Need to go back to the table to query the tree structure of the clustered index]
- According to whether the value will be repeated, it is divided into: unique index (primary key index is the only index) and ordinary index (no restrictions allow null and repeated values)
- According to the number of fields to be indexed, it is divided into: single-column index and joint index
- Full-text index: The full-text index is mainly used to find keywords in the text and can only be created on columns of CHAR, VARCHAR or TEXT type. Only the MyISAM storage engine in MySQL supports full-text indexing. Full-text indexing allows you to insert duplicate values and null values in indexed columns.