introduction
Redis underlying C language structure (similar to java class)
1. RedisServer structure (representing redis server)

The redis server contains multiple DBs, 16 by default. We mainly focus on the member variable redisDb
2. RedisDB structure (representing a DB database)
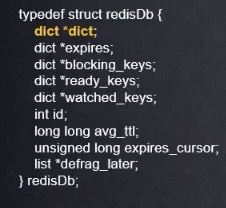
Notes:
- dict means dictionary.
- expires key timeout with timeout set
- id database ID
The other member variables are skipped, and the main focus is on the member variable dict, which is very important, because all data is indexed through the dictionary
3. dict structure (represents a dictionary)
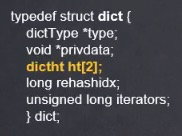
4. Dictht structure (hashtable)

The underlying structure of the dictionary is implemented by hashtable, so there must be a dicEntry structure
Get size length with O(1) time complexity
used represents the length used in the current array
5. dictEntry structure

If a hash conflict occurs when the dictEntry is stored in the hashtable, it will be connected by a linked list, and next represents the dicEntry of the next node.
Both key and val are redisObject structures.
6, redisObject structure

- type represents the data type of the real data (string, list...) (external) (you can easily determine whether the executed command is legal, for example, only string can use the setnx command)
- Encoding is the encoding of the real data at the bottom of redis, which is very important! Have the ultimate pursuit of memory utilization
- lru is related to memory elimination strategy
- Refcount is related to memory management, use the counter method to judge whether it is alive
- The ptr pointer points to the actual storage location of the data: String, hash, list, set, Sorted Set

The general flow chart of the above steps:

1. String
Redis data storage does not directly use the char[] of the c language to store it, and the end of the c language data needs to be represented by'\0'

3.2 In the past, it was a data structure that could be dynamically expanded
len represents the data length. No need to rely on the end of \0
Disadvantage: If I store a very short string such as 1, it will also take up a lot of memory (the memory footprint of the len+free pointer is larger than the data itself)

Some data structures have been added after 3.2. According to the length of the stored data, select the appropriate structure to save space

Note: Although there is this kind of SDS_TYPE_5 structure, it is useless (because the free field cannot be expanded), it will be automatically converted to SDS_TYPE_8
Two coding structures at the bottom
embstr and raw

If the length of the stored string is less than 43 (there is a \0 at the end), it is directly allocated in a cpu cache line next to the redisObject object. It can be read all at once, no need to go through the ptr pointer (additional addressing). At this time, it is the embstr encoding type, as shown in the figure:

Two, list
An ordered (sorted according to the sequence of joining) data structure, using quicklist (double-ended linked list) and ziplist as the underlying implementation of List.
quicklist is a doubly linked list composed of ziplist
#通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended
# -3: max size: 16 Kb <-- probably not recommended
# -2: max size: 8 Kb <-- good
# -1: max size: 4 Kb <-- good
list-max-ziplist-size -2
list-compress-depth 0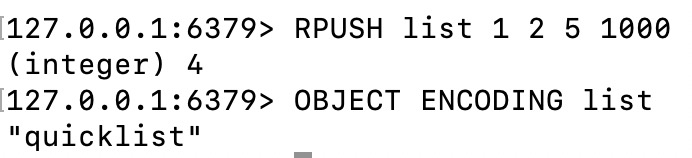


Three, hash hash
The underlying implementation is a dictionary (dict), which is also a data structure used by redisDb to store KV.
When the amount of data is relatively small or a single element is relatively small, the bottom layer is stored in ziplist.
#数据大小和元素阈值redis.conf设置
hash-max-ziplist-entries 512
hash-max-ziplist-value 64Execute the command to set a hash value, you can see that all elements are in the order they were saved

When I added values to the hash, I found that the order was disordered, indicating that the storage structure was changed (from ziplist to hash). The ziplist is ordered, and the hash is disordered.

The ziplist (ordered) storage structure is as follows:

Four, set collection
The bottom layer uses instset and hashtable two data structures for storage. Inset can be understood as an array, and hashtable is an ordinary hash table
#inset集合最多包含多少个节点
set-max-intset-entries 512
When adding elements:
- If the stored element can be converted into an int object, use the intset structure. Otherwise, use hashtable.
- If the length of the intset exceeds 512 after the element is stored, it is converted to a hashtable.
- If it is already a hashtable structure, continue to use hashtable
Five, zset collection
The bottom layer uses ziplist or skiplist (skip list)
Use ziplist when the following configuration is met, otherwise use skiplist
#元素数量小于128个
#所有元素的长度小于64字节
zset-max-ziplist-entries 128
zset-max-ziplist-value 64ziplist structure:

skiplist structure:
