There is only so much content in the main body of our Hadoop article. The next three articles are three MapReduce cases, mainly code, and the implementation process is relatively simple. Pay attention to the column "Broken Cocoon and Become a Butterfly-Big Data" to view related series of articles~
table of Contents
Second, the code implementation
1. Demand analysis
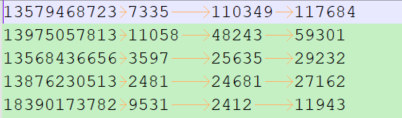
There are log data in the following four columns:

Represents mobile phone number, upstream traffic, downstream traffic, and total traffic respectively. Now it is necessary to process this data and output the top 5 user information of traffic usage.
Second, the code implementation
2.1 First define a Bean class. It is worth noting that there is a compareTo method to achieve descending sorting.
package com.xzw.hadoop.mapreduce.topn;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/12/7 10:40
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class TopNBean implements WritableComparable<TopNBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
public TopNBean() {
}
public TopNBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(TopNBean o) {//比较方法,降序排序
return Long.compare(o.sumFlow, this.sumFlow);
}
public void set(long upFlow, long downFlow) {
this.downFlow = downFlow;
this.upFlow = upFlow;
this.sumFlow = downFlow + upFlow;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
upFlow = dataInput.readLong();
downFlow = dataInput.readLong();
sumFlow = dataInput.readLong();
}
}
2.2 Define the Mapper class
package com.xzw.hadoop.mapreduce.topn;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/12/7 10:57
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class TopNMapper extends Mapper<LongWritable, Text, TopNBean, Text> {
private TopNBean k = new TopNBean();
private Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
v.set(fields[0]);
k.set(Long.parseLong(fields[1]), Long.parseLong(fields[2]));
context.write(k, v);
}
}
2.3 Define a comparator that allows all data to be grouped into the same group
package com.xzw.hadoop.mapreduce.topn;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @author: xzw
* @create_date: 2020/12/7 11:16
* @desc: 让所有数据分到同一组的比较器
* @modifier:
* @modified_date:
* @desc:
*/
public class TopNComparator extends WritableComparator {
protected TopNComparator() {
super(TopNBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
return 0;
}
}
2.4 Define the Reducer class
package com.xzw.hadoop.mapreduce.topn;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @author: xzw
* @create_date: 2020/12/7 11:04
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class TopNReducer extends Reducer<TopNBean, Text, Text, TopNBean> {
@Override
protected void reduce(TopNBean key, Iterable<Text> values, Context context) throws IOException,
InterruptedException {
Iterator<Text> iterator = values.iterator();
for (int i = 0; i < 5; i++) {
if (iterator.hasNext()) {
context.write(iterator.next(), key);
}
}
}
}
2.5 Define the Driver class
package com.xzw.hadoop.mapreduce.topn;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/12/7 11:21
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class TopNDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"e:/input/topn.txt", "e:/output1"};
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TopNDriver.class);
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
job.setMapOutputKeyClass(TopNBean.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setGroupingComparatorClass(TopNComparator.class);
job.setOutputValueClass(TopNBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
2.6 Test results