The concept of queue:
1. It is the middleware of the queue structure
2. The message does not need to be processed immediately after being placed
3. Processing by subscribers/consumers in order
Queue principle:

It is also the principle of decoupling: the business system has nothing to do with the queue processing system
One write (business system) and one read (queue management system).
Just write to the queue, don’t worry about other things, it doesn’t matter whether you can finish reading or not.
In the same way, just read from the queue, just do the work when you come, and rest when you don’t have work.
Application scenarios:
Redundancy: Persistent storage in the queue, subsequent acquisition by the order processing program, after processing is completed, the record is deleted
Decoupling: It is the decoupling of these two systems (business and queue processing). What we usually do is a system. There is no direct relationship between the enqueue and dequeue systems. One of the systems is bounced, and the other system will not be affected because there is a queue in between.
Traffic cutting: seckill and panic buying. The traffic has increased sharply, and the message queue is used in conjunction with the cache (that is, under the limit, if only 10 is allowed, the queue will not be saved after 10 is stored, and it will prompt the end of the spike when it comes)
Asynchronous communication: Because the message itself can directly return the enqueued system, it is said that the asynchronous operation of the program is realized
Scenario scalability: If there is only an order system and a financial system now, I want to add a distribution system in the future, and just let the distribution system subscribe to this queue directly
Ordering guarantee: In some scenarios, the processing order of bank data is very important, because the queue itself can be made into a single-threaded, single-in, single-out system
Implementation medium:
1. Use mysql: high reliability, easy to implement, and slow
2. Use redis: fast speed, low efficiency in a single large message packet
3. Use more professional third-party libraries: strong professionalism, reliability, and high learning costs.
Please refer to my blog http://blog.csdn.net/qq_33862644/article/details/79386484
Message processing trigger mechanism:
1. Reading in endless loop mode: easy to implement, unable to reply in time when a fault occurs (applicable to a short time such as a spike)
2. Timed tasks: the pressure is evenly divided, and there is an upper limit for processing (no matter how unstable the peak is in your system before the queue, the system after the queue will still be executed regularly)
Note: Timing time is the key: Don’t start the next timing task if the previous timing task is not completed.
Case: Order system, after placing the order, the order information is written into the queue, and the order is returned immediately. The distribution system reads the queue regularly every few minutes, and aggregates the orders
3. The daemon process: similar to php-fpm and cgi, it requires shell basics (use this process to detect whether there is content in the queue, and if there is content, start the dequeue system for processing)
Use mysql to achieve decoupling case:
Why decoupling: If the architecture is together. The order system is under great pressure, and logistics information does not need to be returned immediately. Orders collapse, logistics will jump, so decoupling
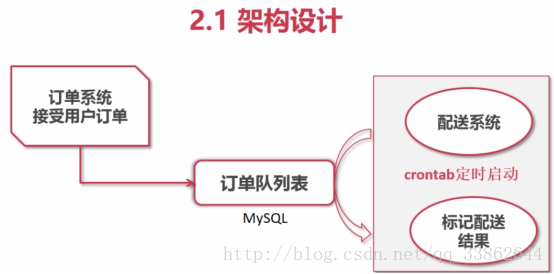
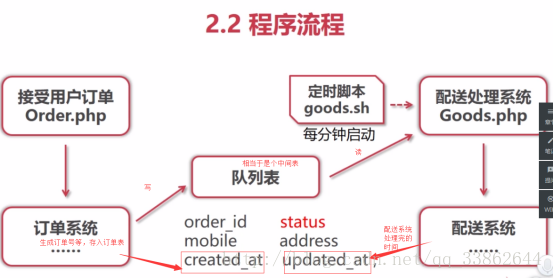
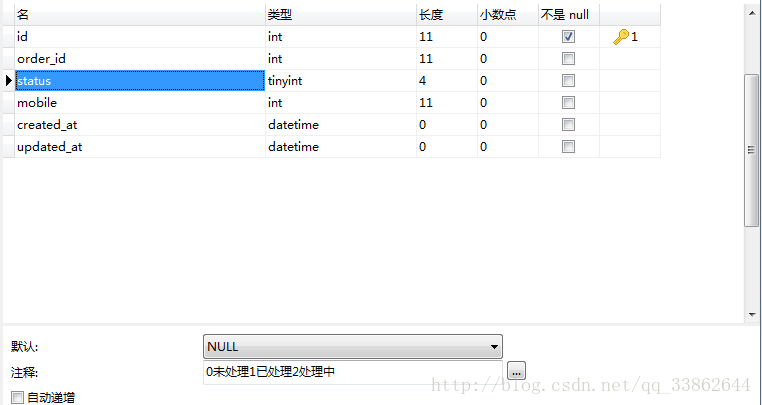
Table design:
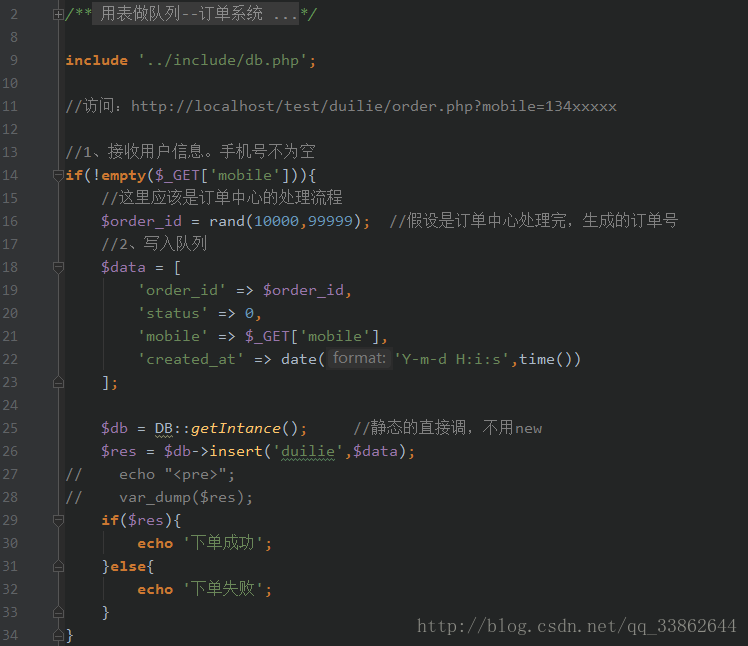
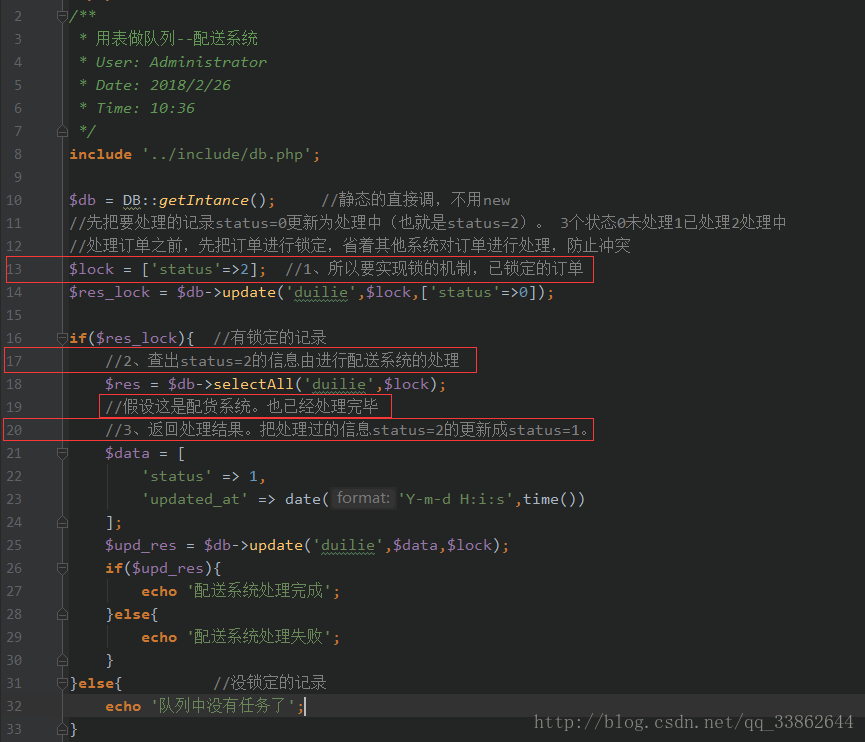
The code that the order system writes to the queue:
The picking system reads the code of the queue:
Perform timing tasks Crontab -e

Note: This log file needs to be created by yourself

1. Visit order.php through the browser to add an order
2. Go to the database to see the result, and see the result in the log in the shell (the execution is not successful, it may be that the sh file needs to be placed in a specific directory, and it will be running after the review is completed)
Use redis for traffic cutting case
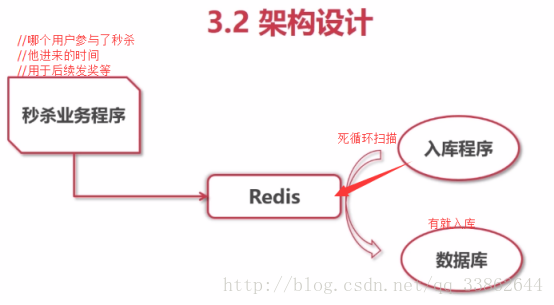
Ideas:
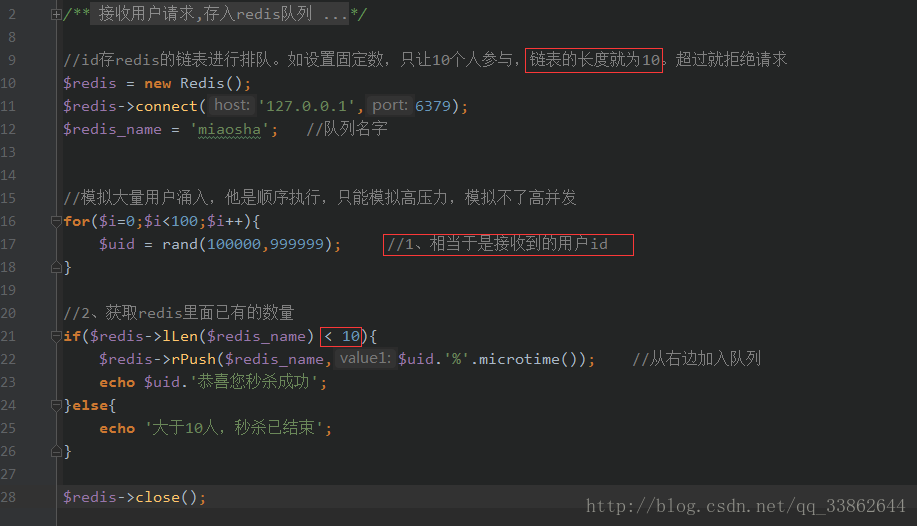
1. The spike program requests to write redis
2. Check the length of the data stored in redis, and discard it if it exceeds the upper limit (return to the end of the second kill)
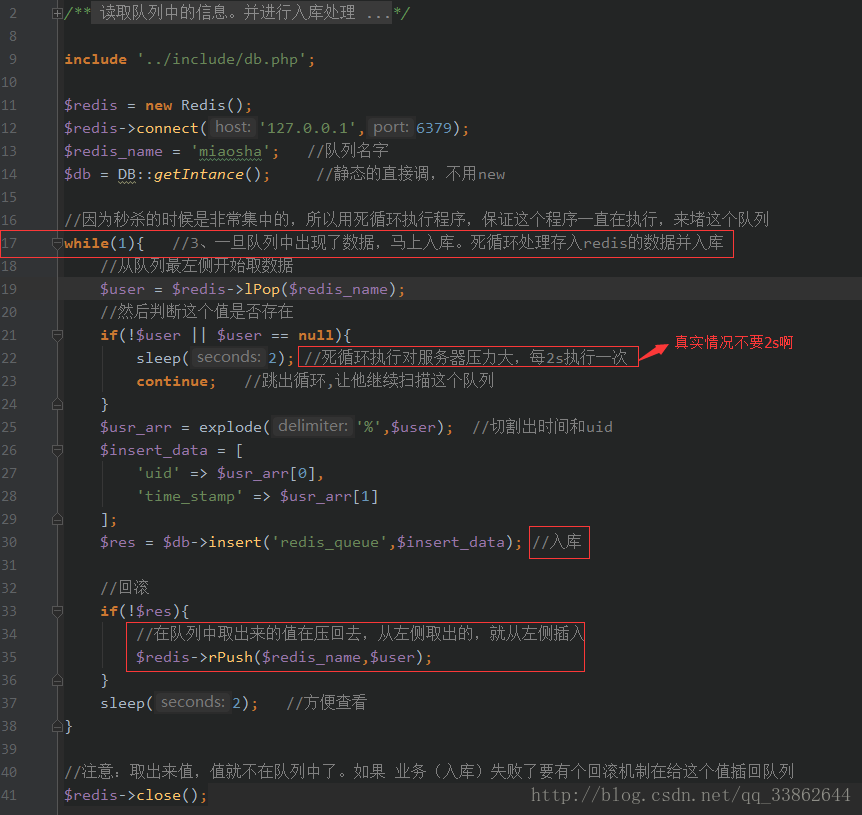
3. The data stored in redis is processed in an endless loop and stored in the database
Table design:

Spike code:
Incoming code:
Browser directly access user.php
Use php -f savetodb.php in the shell
Go to the database to view